




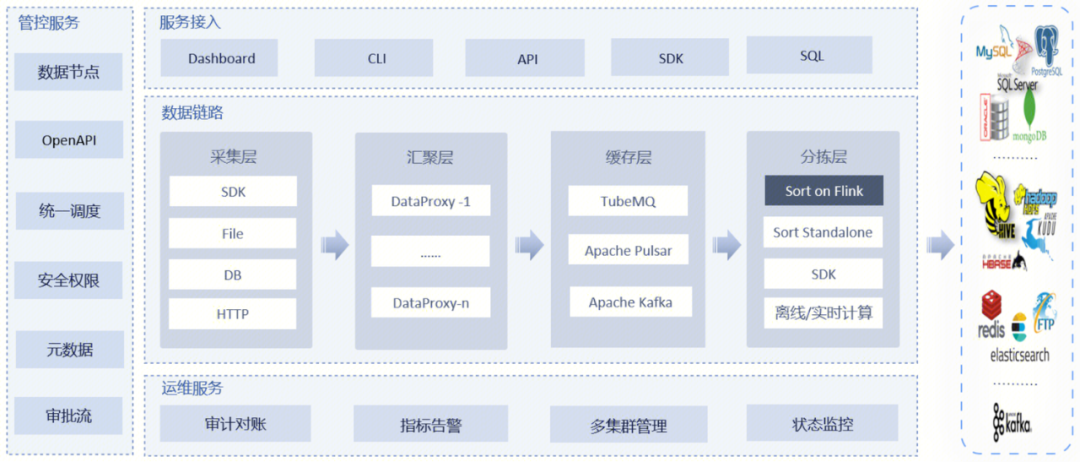
作为业界首个一站式、全场景海量数据集成框架,Apache InLong(应龙) 提供了自动、安全、可靠和高性能的数据传输能力,方便业务快速构建基于流式的数据分析、建模和应用。目前 InLong 正广泛应用于广告、支付、社交、游戏、人工智能等各个行业领域,服务上千个业务,其中高性能场景数据规模超百万亿条/天,高可靠场景数据规模超十万亿条/天。
StarRocks 数据导入
01
01
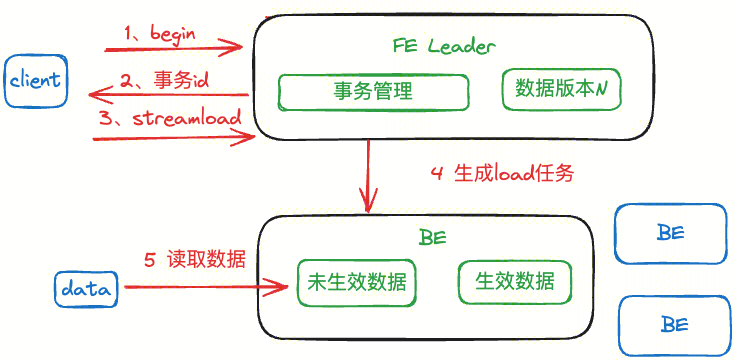
StarRocks 作为数据湖云原生化、弹性化、实时化的重要产品,为业务在报表推送、实时数据分析、数据湖分析等场景提供了助力。目前 StarRocks 提供四种数据导入能力,分别是 Stream Load, Broker Load, Routine Load,Spark Load。目前 Apache InLong 选用 Stream Load 方式进行实时写入,由于需要事务性保证,使用了带事务能力的 Stream Load 接口 Stream_Load_Transaction_Interface[1],下面介绍下 StarRocks 中的事务写入原理。
02
02
StarRocks 的事务写入基于典型的两阶段提交事务实现,客户端使用事务服务主要包含以下几个接口:
/api/transaction/begin:开启一个新事务。 /api/transaction/prepare:预提交当前事务,临时持久化变更。预提交一个事务后,可以继续提交或者回滚该事务。这种机制下,如果在事务预提交成功以后 StarRocks 发生宕机,仍然可以在系统恢复后继续执行提交。 /api/transaction/commit:提交当前事务,持久化变更。 /api/transaction/rollback:回滚当前事务,回滚变更。 /api/transaction/load:发送数据,可以使用已有的事务,如果没有指定事务label,会随机生成一个 label 进行数据写入
Begin + load 阶段:
Commit 阶段
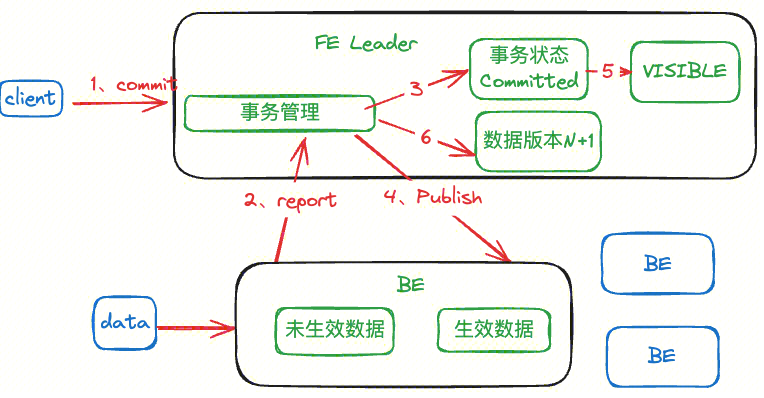
FE 接受 commit 信息之后,会将事务状态改为 committed。之后事务管理器会向 BE 节点发送 publish version 消息,BE 收到 publish 中的版本消息后,会将本地的消息版本改为本次事务对应的版本;同时会向 FE 回包代表数据版本已经成功修改,并且将数据的状态改为 VISIBLE。此时数据对用户可见,客户端执行查询的时候会比较版本号,从而解决读写版本冲突;
Rollback 阶段
如果写入过程或者 commit 过程失败,则事务 abort,清理事务的任务在 BE 节点异步执行,将数据导入生成的数据标记为不可用,这些数据之后会从 BE 上被删除。状态为 committed 的事务(commit 成功但 publish version 超时的事务)不能被回滚。
03
03
StarRocks 可以通过给数据设置版本控制来解决读写冲突
StarRocks 通过引入 FE 中的事务管理实现了两阶段导入,保证了导入的原子性
InLong 实时写入 StarRocks 原理
01
01
Apache InLong 实时写入 StarRocks 如图所示,实时写入通过 Flink 实时任务来实现,Flink 任务写入侧具体执行逻辑如下:
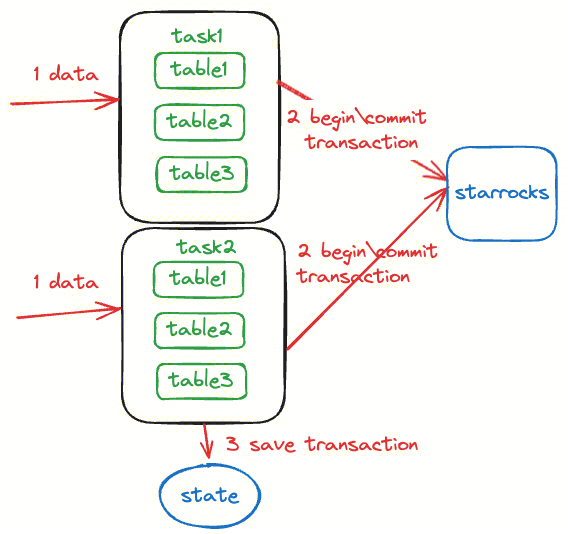
根据 Flink 并行度配置生成多个 Task 执行写入
每一个 Task 基于 StarRocks 提供的 Stream Load 机制进行写入,每一个 Flink checkpoint 周期使用相同的 StarRocks 事务 label;
Flink 开始做 checkpoint 时,状态中存入当前写入的 table 以及对应的事务 label;
写入算子收到 checkpoint 完成的消息时,将所有的 table 对应的事务进行 commit,此时数据对用户可见
02
02
1 任务写入数据
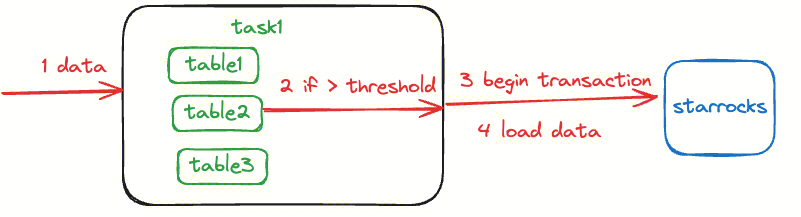
在写入数据时,首先不会直接将数据写入到 StarRocks 中,而是将每个 table 对应的数据进行缓存。单个表数据达到一定大小之后才会调用一次刷新 flush 操作,flush 操作包括以下流程:
启动一个事务,每个 checkpoint 内会使用同一个事务 label,调用 api/transaction/begin 使用该 label 进行数据写入,调用 api/transaction/load 实际写入数据
这种写入流程保证了:
每次写入使用相同的事务 label,提交时可以提交一整个 checkpoint 内的所有数据,单个 checkpoint 只会提交一次,重复提交 StarRocks 不会生效; 每次写入都是批次写入,缓解 StarRocks 写入压力
2 任务保存检查点
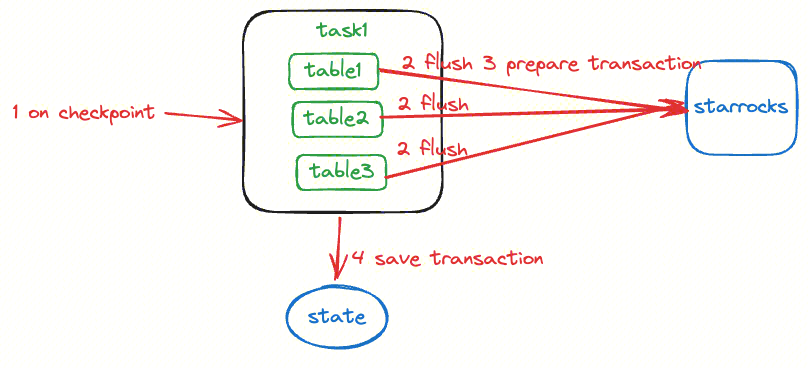
对目前内存中保存的所有表的数据都进行 flush, 确保内存中所有的数据已经导入到 StarRocks, 当前数据在 StarRocks 中不可见
对所有的表对应的导入事务,进行 prepare 调用,如果 prepare 失败,则表示当前 StarRocks 不支持该事务的提交,调用 abort 接口,并失败重试
对于 prepare 成功的事务,保存在当前 Flink 状态信息中
3 任务如何确认保存点成功
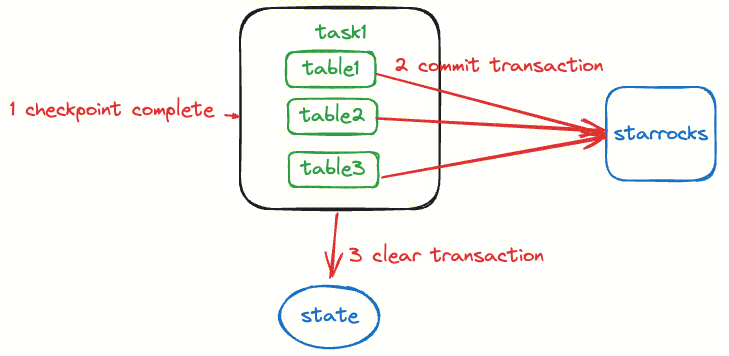
4 任务如何初始化
03
03
要保证流式写入的 exactly once 语义等同于需要保证数据的不重复以及不丢失。
1 数据不重复保证
基于 Flink 的流式任务产生数据重复的原因主要是 Flink 从某一个 checkpoint 启动时,重复提交之前已经提交过的数据。InLong 实时写入中,状态中会记录本 checkpoint 下 prepare 成功的事务 id ,故障恢复时,会提交该事务 id, 如果该事务 id 在之前的流程中被提交过,StarRocks 会返回报错信息表示该事务 id 已经提交过,该次提交会被忽略,通过这种机制保证了数据的不重复。
2 数据不丢失保证
假设在数据写入过程中,有部分数据写入失败,Flink checkpoint 机制会保证任务重启后从上一个保存点启动,Source 端会从上次保存消费位置开始消费,这样能够保证数据的不丢失,之前写入失败的数据会在重启后继续执行写入。
性能测试
01
01
使用压测程序以 1000 qps 的写入速度生成数据到 Iceberg 测试表中
生成到 1 亿数据时,启动实时同步任务同步到 StarRocks 表
StarRocks 测试表清空
测试在不同并行度的情况下任务追上最新数据的时间
02
02
| 并行度 | 数据量 | 同步时间 | 同步吞吐 | |
|---|---|---|---|---|
| 场景一 | 1 | 1 亿 | 60 分钟 | 27 Mb/s |
| 场景二 | 3 | 1 亿 | 10 分钟 | 162 Mb/s |
| 场景三 | 40 | 1 亿 | 2 分钟 | 800 Mb/s |
结语
Stream_Load_Transaction_Interface: https://docs.starrocks.io/docs/loading/Stream_Load_transaction_interface/
[2]实时同步 MySQL->StarRocks: https://inlong.apache.org/zh-CN/docs/next/quick_start/data_sync/mysql_starrocks_example/
关于 StarRocks


