




翻译和引用自Nikola YouTube
随着大模型AI的进一步发展,我们需要存储和处理的数据量呈指数级增长,寻找存储各种数据风格的最佳方式依然是最大的挑战之一。
相信现在几乎已经没有人还会认为关系数据库是依然是唯一数据存储处理方式。
比如说抖音的视频和直播等信息,其原始数据通常是无法实现以传统(关系)数据库方式存储的,或者以传统方式存储它们需要大量的精力和时间,同时会增加总体数据的分析时间。
即使我们还在以某种方式坚持传统方法,结构化方式存储数据,但我们需要设计复杂且耗时的 ETL 工作负载来将这些数据移动到企业数据仓库中。
这种架构方式使得数据分析从业人员,可能被分为两类,一类人主要每天接触 Python负责处理转换数据到关系型数仓,一类主要接触SQL针对关系型数据库进行分析。
Parquet 一种文件格式
可以说最近几年 Parquet 已经被认为是当今存储数据的事实上的标准了,它主要有以下几个优势:
数据压缩:通过应用各种编码和压缩算法,Parquet 文件可减少内存消耗,减少存储数据的体积。
列式存储:快速数据读取操作在数据分析工作负载中至关重要,列式存储是快速读取的关键要求。
与语言无关:开发人员可以使用不同的编程语言来操作 Parquet 文件中的数据。
开源格式:这意味着您不会被特定供应商锁定
支持复杂数据类型
行存储vs列存储
我们已经提到过 Parquet 是一种基于列的存储格式。
然而,要了解使用 Parquet 文件格式的好处,我们首先需要区分基于行和基于列的数据存储方式。
在传统的基于行的存储中,数据存储为行序列。像下图所示一样:
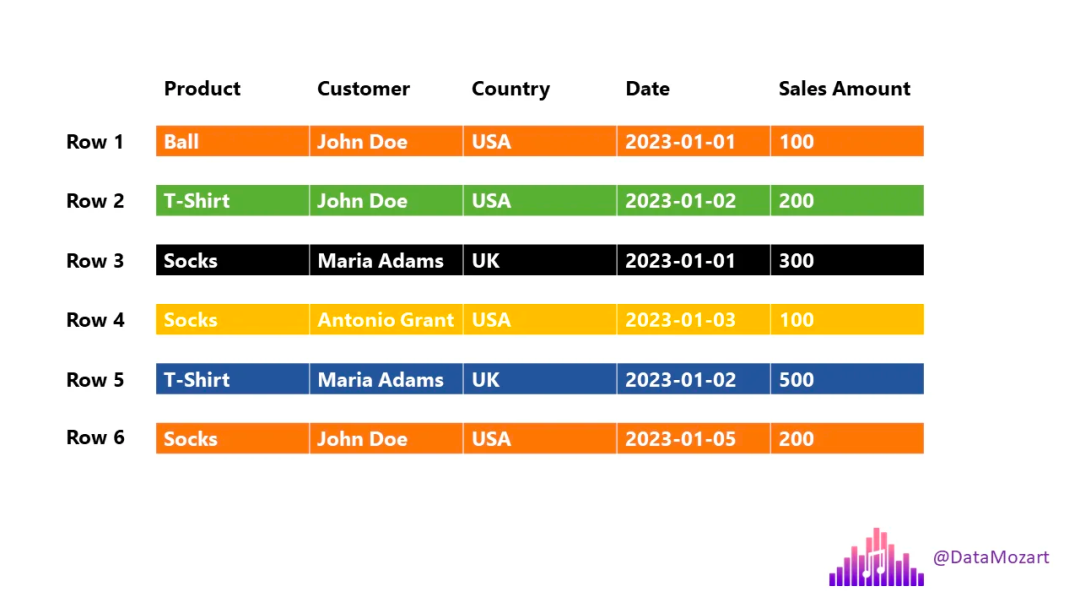
现在我们举例OLAP数据分析中的一个场景,用户可能会问的一些常见问题:
我们卖了多少个球?
有多少美国用户购买了 T 恤?
客户 Maria Adams 的总消费金额是多少?
1 月 2 日我们有多少销售额?
为了能够回答这些问题,引擎必须从头到尾扫描每一行!
因此,为了回答这个问题:有多少美国用户购买了 T 恤,引擎必须执行以下操作:

本质上,我们只需要两列中的信息:产品(T 恤)和国家/地区(美国),但引擎将会扫描所有五列数据!
这不是我们想要的最有效的解决方案。
现在让我们看看列存储是如何工作的,是否如您可能猜想的那样:
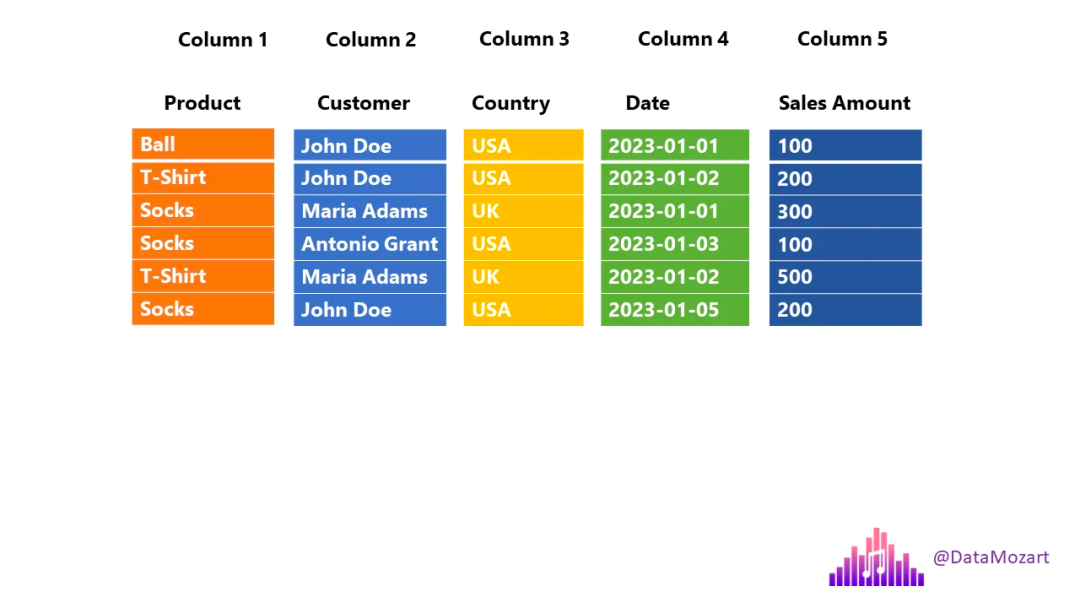
如上图所示,在这种情况下,每一列都是一个单独的实体 - 这意味着,每一列在物理上都与其他列分开的!
回到我们之前的业务问题:引擎现在可以只扫描查询所需的列(产品和国家/地区),同时跳过不必要扫描的列。
在大多数情况下,这种数据跳过应该会提高分析查询的性能。
好的,但在Parquet诞生之前,列式存储早已经出现,那么,Parquet 格式有何特别之处?
Parquet 是一种列格式,将数据存储在行组中
等等,什么?!之前的事情还不够复杂吗?别担心,这比听起来容易得多。
让我们回到之前的示例并描述 Parquet 如何存储相同的数据块:
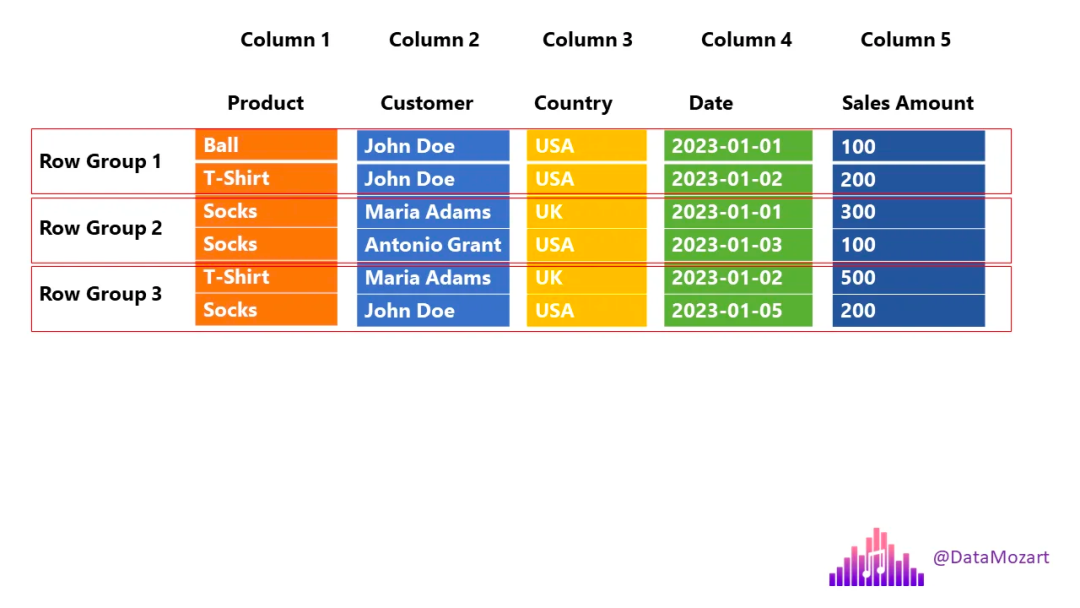
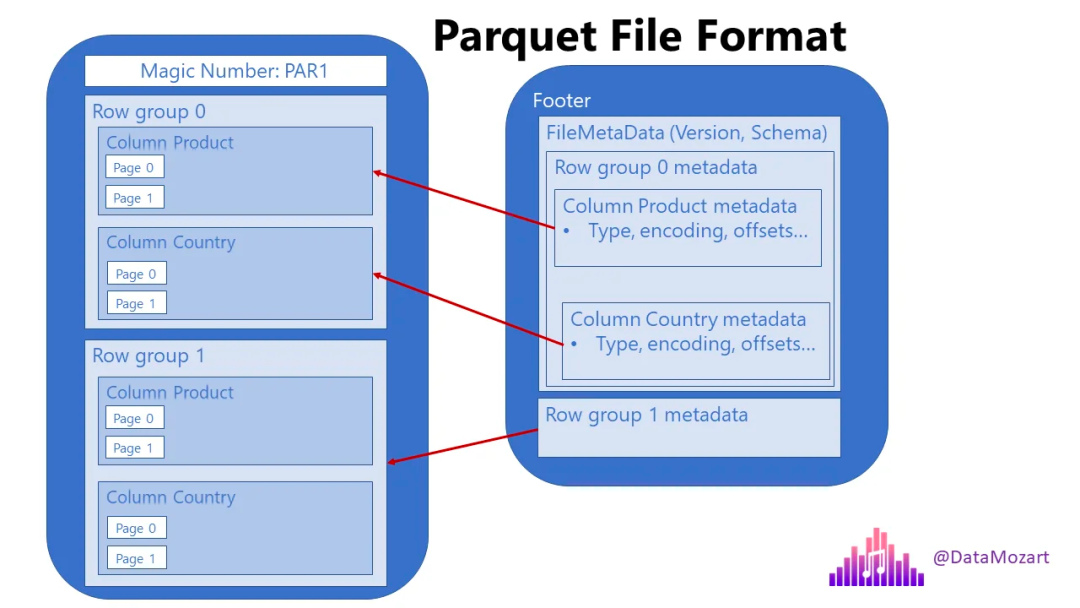
让我们停下来解释一下上面的插图,因为这正是 Parquet 文件的结构(故意省略了一些其他内容)。
列仍然存储为单独的单元,但 Parquet 引入了额外的结构,称为行组RowGroup。
为什么这个附加结构非常重要?
实际上我们在OLAP场景中,主要关心两个概念:
投影
谓词
投影是指SQL 语言中的SELECT语句 - 查询需要哪些列。回到之前的示例,我们只需要“产品”和“国家/地区”列,因此引擎可以跳过扫描其余的列。
谓词是指SQL 语言中的WHERE子句 – 哪些行满足查询中定义的条件。在我们的例子中,我们只对 T 恤感兴趣,因此引擎可以完全跳过扫描第 2 行组,其中“产品”列中的所有值都等于袜子!
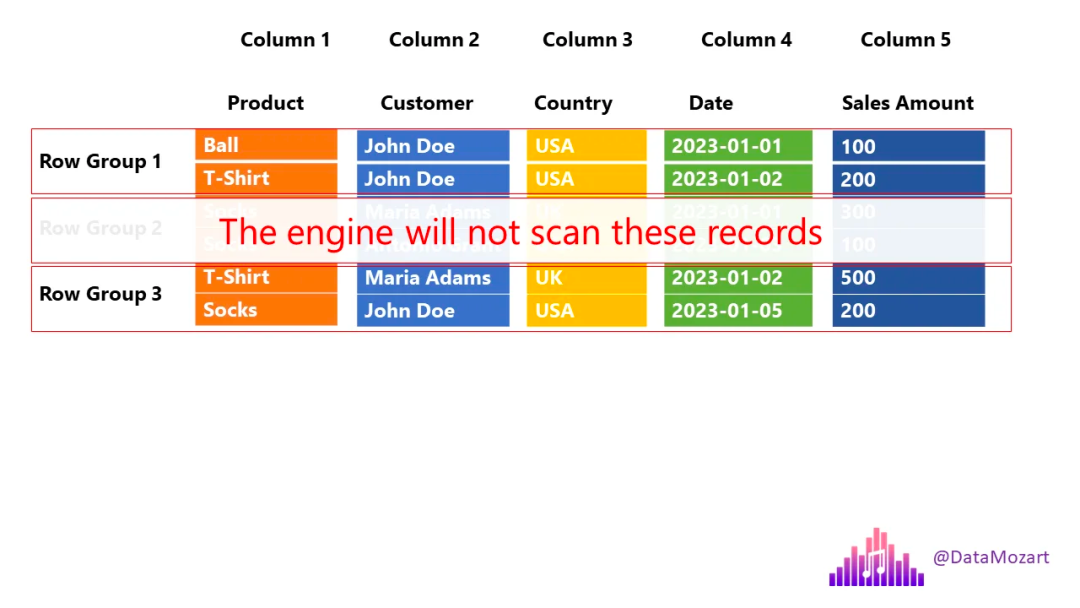
让我们暂停总结分析一下,因为我希望您认识到各种类型的存储在引擎需要执行的工作方面的差异:
行存储——引擎需要扫描所有 5 列和所有 6 行
列存储 – 引擎需要扫描 2 列和所有 6 行
具有行组的列存储 – 引擎需要扫描 2 列和 4 行
显然,这是一个过于简化的示例,只有 6 行和 5 列,您绝对看不到这三种存储选项之间的性能差异。然而,在现实生活中,当您处理大量数据时,差异就会变得更加明显。
现在,最急切的问题是:Parquet 是如何“知道”要跳过/扫描哪个行组?
Parquet 文件包含元数据
这意味着,每个 Parquet 文件都包含“有关数据的数据”,例如特定行组内特定列中的最小值和最大值等信息。
此外,每个 Parquet 文件都包含一个页脚,其中保存有关格式版本、架构信息、列元数据等信息。您可以在此处找到有关 Parquet 元数据类型的更多详细信息。
为了优化性能并消除不必要的数据结构(行组和列),引擎首先需要“熟悉”数据,因此它首先读取元数据。
虽然这个操作不算慢,但还是需要一定的时间,因此,如果您从多个小型 Parquet 文件中查询数据,查询性能可能会降低,因为引擎必须从每个文件中读取元数据。
因此,您最好将多个较小的文件合并为一个较大的文件(但仍然不要太大)
那么什么是“大”,什么是“小”呢,这里没有单一的“黄金”数字,因为这和任务的处理瓶颈是相关的,一般我们建议单个 Parquet 文件的大小至少应为几百 MB。
Parquet里面还有什么
以下是 Parquet 文件格式图示的简化高级说明:
通过上面的解释,我们已经明白了Parquet是如何通过跳过不必要的数据结构(行组和列)的扫描来加速您的查询并提高整体性能的。
但是,不仅仅如此 – 还记得我一开始就告诉过您 Parquet 格式的主要优点之一是减少文件的内存占用吗?这是通过应用各种压缩算法来实现的。
有两种主要的编码类型使 Parquet 能够压缩数据并实现惊人的空间节省:
1. 字典编码– Parquet 创建列中不同值的字典,然后用字典中的索引值替换“真实”值。回到我们的例子,这个过程看起来像这样:

您可能会想:当产品名称很短时,为什么会有这样的开销,对吧?但现在想象一下如果您存储了产品的详细描述呢?例如:“长臂 T 恤,颈部有领边“。
而且,现在想象一下您的产品已售出一百万次…是的,Parquet 将仅存储索引值(整数而不是文本),而不是具有百万次重复值“长臂…bla bla”。
2. 基于位压缩的运行长度编码– 当您的数据包含许多重复值时,基于位压缩的运行长度编码 (RLE) 算法可能会带来额外的内存节省。
我们可以发现当我们花费一点存储开销在写入时对数据进行些许的统计信息收集,对于将来读取时的数据跳过有这非常大的益处,Parquet是单文件的数据格式,还能比这更好吗?
数据湖文件组织格式
好吧,数据湖文件组织格式是什么呢?
我们都知道传统上Hive等采用的管理多个文件的方式就是文件夹,当我们想要获取某一天的数据时,就读取这一天数据所生成的文件夹即可,但这种情况下显然也已经跟不上时代的变化了。
常用的开源数据湖文件管理,主要包括Delta Lake、Iceberg和Hudi。
数据湖文件组织格式,也是通过记录数据写入时的统计信息,来直接跳过读取文件来提升其查询性能效果,本质上是异曲同工的,这里我们不做过多的介绍。
这里可参考:
[LakeHouse] 数据湖之Iceberg一种开放的表格式
[LakeHouse] Delta Lake全部开源,聊聊Delta的实现架构
当说数据湖文件组织格式所提供能力时,主要是 Parquet 文件的版本控制。它还存储事务日志,以便跟踪应用于 Parquet 文件的所有更改。这也称为ACID 兼容事务。
由于它不仅支持 ACID 事务,还支持时间旅行(回滚、审计跟踪等)和 DML(数据操作语言)语句,例如 INSERT、UPDATE 和 DELETE,等数据仓库的行为,所以又被叫做“data warehouse on the data lake”。
总结
和数据一样,数据存储的文件格式和文件的组织管理方式也一直在进化。因此,新的数据风格需要新的存储方式。
Parquet 文件格式是当前数据环境中最有效的存储选项之一,因为它提供了多种优势 - 通过利用各种压缩算法来减少内存消耗,并通过使引擎跳过扫描不必要的数据来实现快速查询处理。
数据湖文件组织格式,也有通过记录数据写入时的统计信息,来直接跳过读取文件来提升其查询性能的优化。
此外,Parquet 和 ORC 都是用于存储大规模数据的列式存储格式,它们都有各自的优势和适用场景,这里我们简单总结下:
Parquet是语言无关的,在设计之初没有和任何数据框架绑定在一起,基于Hadoop生态的任何项目都可以使用,目前在 Spark、Arrow等社区对Parquet有更好的支持,ORC主要来源于Hive社区。
在文件数据量不大的情况下,ORC存储压缩效率和读取性能应该是要胜过Parquet的。
如果该文件是用ORC存储,Snappy压缩的,因为Snappy不支持文件分割操作,会导致压缩文件只会被一个任务所读取。所以在实际生产中,文件存储较大时,一般使用Parquet存储,lzo压缩的方式更为常见。
