




我们有个mongodb实例,某段时间cpu使用率达到了100%。
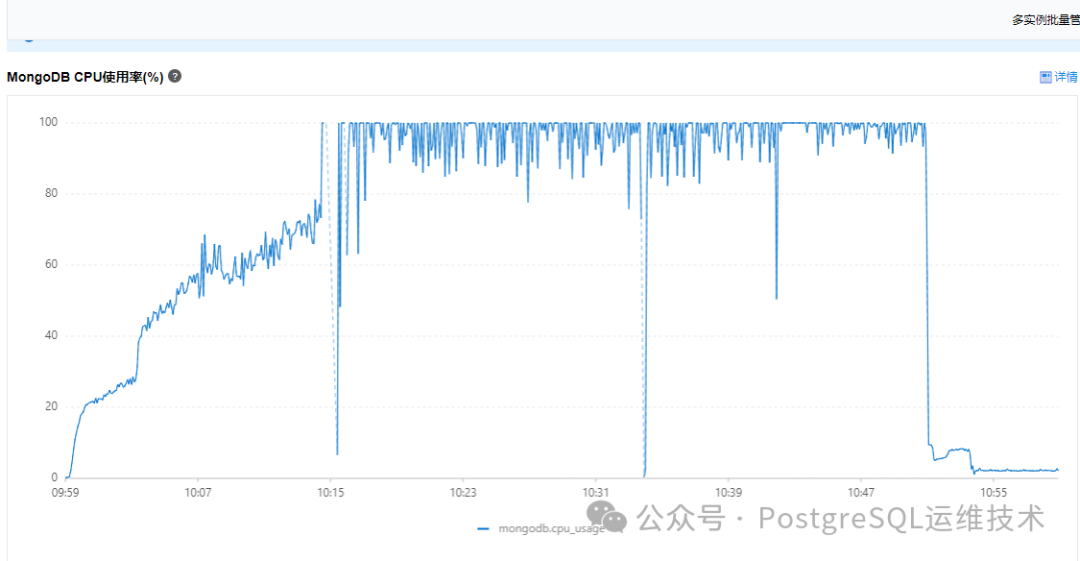
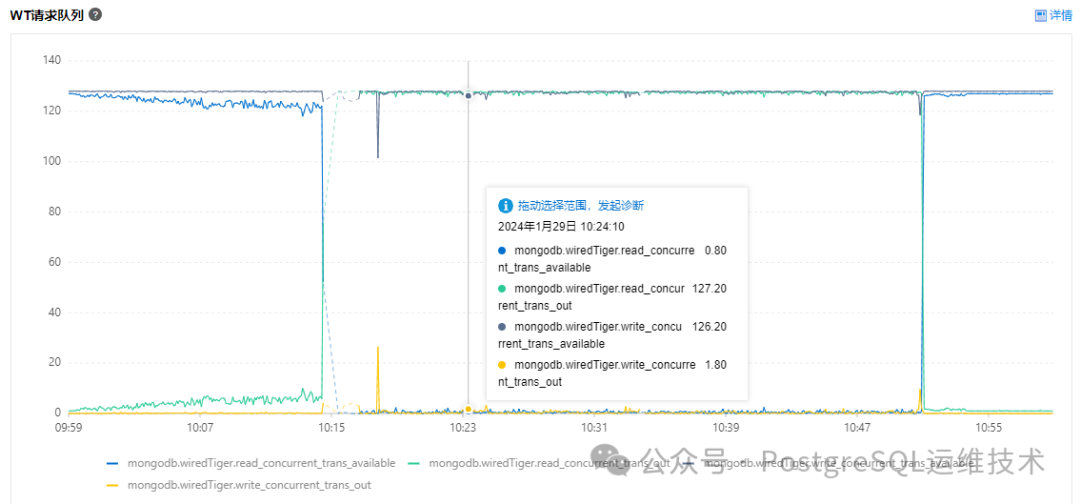
与此同时,我们观察到这段时间内GlobalLock和wt请求队列的指标也有波动。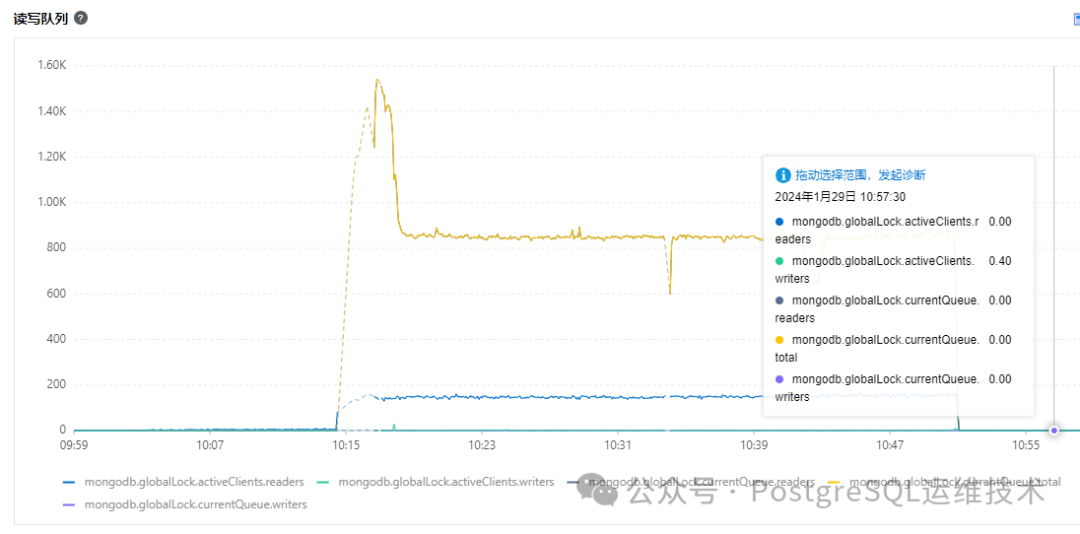
那么cpu突增和globalLcok以及wt请求队列之间存在什么样的联系呢?
MongoDB 中的globalLock
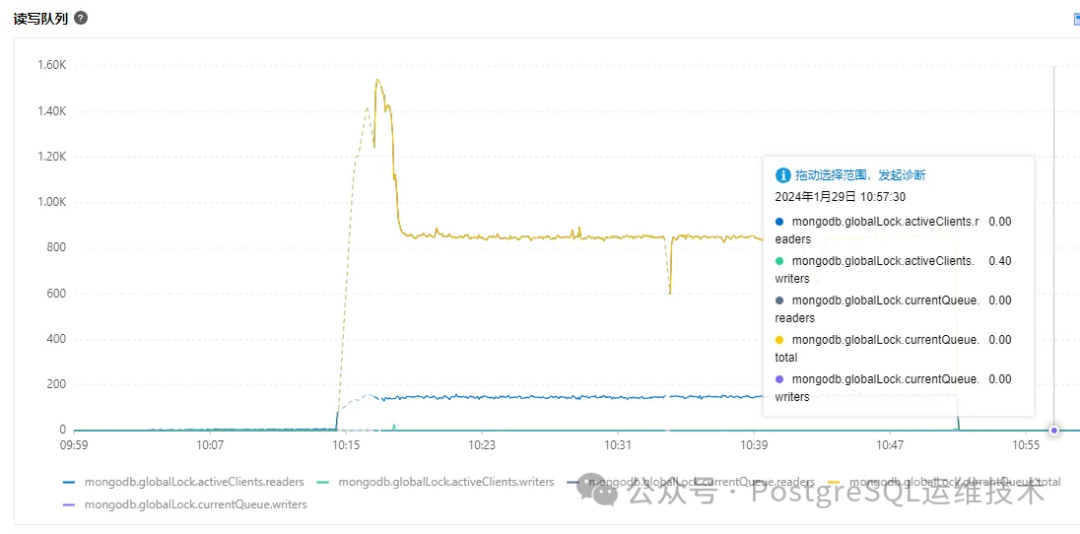
上图中所示的监控指标含义如下:
mongodb.globalLock.currentQueue.total:排队等待锁的操作总数(即globalLock.currentQueue.readers和globalLock.currentQueue.writers的总和)。 mongodb.globalLock.currentQueue.readers:当前排队等待读锁的操作数。 mongodb.globalLock.currentQueue.writers:当前排队等待写锁的操作数。 mongodb.globalLock.activeClients.readers:执行读操作的活动客户端连接数。 mongodb.globalLock.activeClients.writers:执行写操作的活动客户端连接数。
MongoDB将资源进行了层次划分:global-->db-->collect-->document。资源层级从上到下优先级依次降低。在对资源加锁时,也是按层次管理的方式。从globalLock-->DBLock-->CollectionLock-->DocumentLock。MongoDB中最小的资源粒度是Document,document级别的锁由WT引擎控制。
一般而言,在对低优先级的资源加锁时,需要对更高级别的资源加意向锁。比如在对collection加排他锁之前,需要对database和global加意向排他锁。
mongodb中的锁模式
| lock Mode | 描述 |
|---|---|
| R | 表示共享(S)锁。 |
| W | 表示排他(X)锁。 |
| r | 表示意向共享(IS)锁。 |
| w | 表示意向排他(IX)锁。 |
mongodb中的锁矩阵
/**
* LockMode compatibility matrix.
*
* This matrix answers the question, "Is a lock request with mode 'Requested Mode' compatible with
* an existing lock held in mode 'Granted Mode'?"
*
* | Requested Mode | Granted Mode |
* |----------------|:------------:|:-------:|:--------:|:------:|:--------:|
* | | MODE_NONE | MODE_IS | MODE_IX | MODE_S | MODE_X |
* | MODE_IS | + | + | + | + | |
* | MODE_IX | + | + | + | | |
* | MODE_S | + | + | | + | |
* | MODE_X | + | | | | |
*/
MongoDB中对某个collect具体的document进行读写操作时,加锁的流程如下所示:
写操作
1. globalLock Mode_IX
2. DBLock MODE_IX
3. Colleciotn MODE_IX
4. pass request to wiredtiger(document级别的锁由WT引擎控制。)
读操作
1. globalLock MODE_IS
2. DBLock MODE_IS
3. Colleciton MODE_IS
4. pass request to wiredtiger(document级别的锁由WT引擎控制。)
MongoDB 中的请求队列
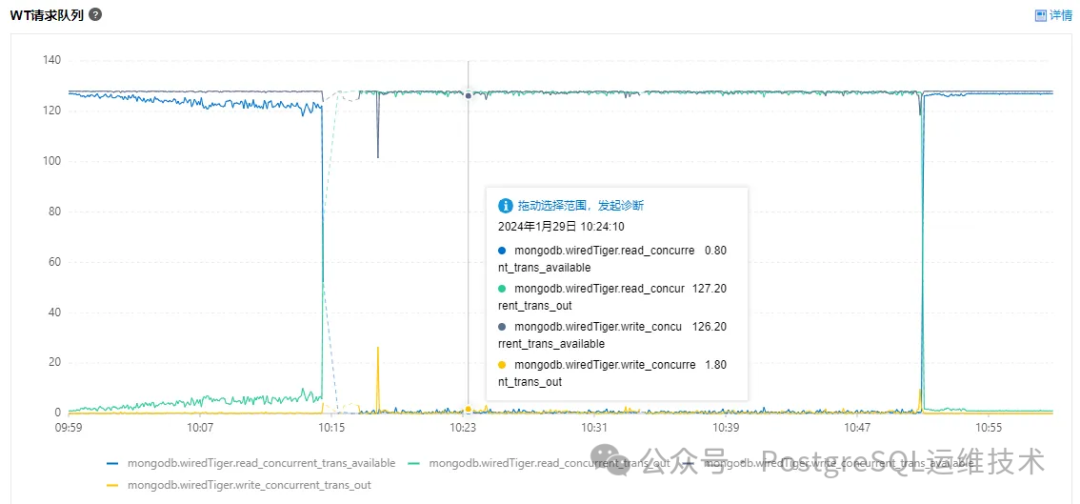
上图中所示的监控指标含义如下:
write_concurrent_trans_out:写并发请求数。 read_concurrent_trans_out:读并发请求数。 write_concurrent_trans_available:可用的写并发数。 read_concurrent_trans_available:可用的读并发数。
MongoDB中有2个参数:storageEngineConcurrentReadTransactions和storageEngineConcurrentWriteTransactions,分别用于指定允许进入存储引擎(wiredTiger)的并发读事务和并发写事务的最大数量,默认值都是128。所以我们可以看到上图中的write_concurrent_trans_out和read_concurrent_trans_out指标在10:15~10:52分之间都接近128,而write_concurrent_trans_available和read_concurrent_trans_available接近于0,这说明这段时间存储引擎处理的并发读写事务达到了阈值,后续的读写请求都需要排队了。
我们可以通过db.serverStatus()命令,查看globalLock几个指标的当前值:
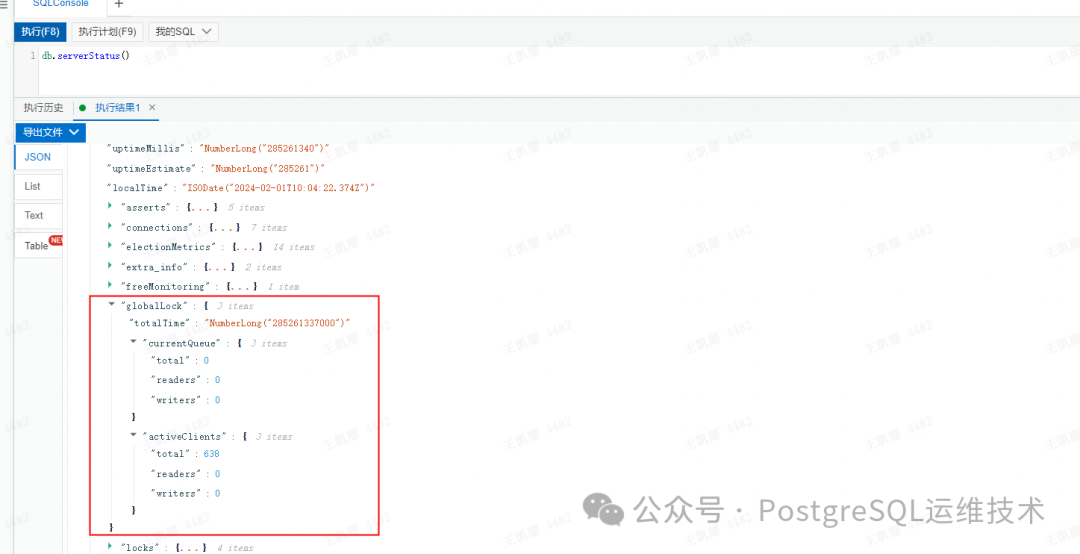
globalLock和WT排队队列的关系
从上面的锁矩阵中我们知道意向锁之间是不相互阻塞的,所以如果不加限制,所有对document进行的读写操作都会被传到WT引擎侧,但是引擎处理请求的能力是有限的,如果所有的并发请求都被打到存储引擎层,会给存储引擎造成很大的压力,所以mongodb引入了ticket机制:
连接在获取Global锁之前,需要先获取对应的ticket,mongodb通过ticket来控制请求的并发度,而ticket的数量即是storageEngineConcurrentReadTransactions和storageEngineConcurrentWriteTransactions参数设置的值,默认是128。
如果能拿到ticket,globalLock的状态就会变成active,即对应上面的监控指标:mongodb.globalLock.activeClients.readers或mongodb.globalLock.activeClients.writers,如果拿不到ticket(ticket被用尽),globalLock的状态就会变成Queued,即对应上面的监控指标:mongodb.globalLock.currentQueue.readers和mongodb.globalLock.currentQueue.writers。
所以一般情况下:globalLock queue队列的上升,对应着读写ticket可用数(available)的减少,甚至跌为0。
CPU突增与globalLock、WT请求队列波动的联系
MongoDB CPU使用率高常见原因一般是扫描行数高或者是并发过大。
当单个查询的扫描行数高时,执行时间就会变长,那么CPU时间就会变长。当请求堆积或者此类查询的并发较高时,整体的CPU占用时间就会变长,CPU使用率突增。单个请求执行时间过长,就会导致连接占用的ticket长时间未释放,这个时候并发的请求就会导致ticket耗尽,z造成后续的请求堆积,globalLock queue队列增长。这种场景我们可以通过优化单个请求来缩短单个请求的处理时间。
当单个请求的rt很低,但是并发很大时,也可能会出现超出数据库处理能力进而引发请求堆积的问题,这时候可以通过减少并发或升级硬件资源(内存、磁盘、CPU)来解决问题。
参考:https://zhuanlan.zhihu.com/p/644323120 https://mongoing.com/archives/4768 https://www.mongodb.com/docs/manual/reference/parameters/#mongodb-parameter-param.storageEngineConcurrentReadTransactions

点个“赞 or 在看” 你最好看!

👇👇👇 谢谢各位老板啦!!!
