




背景信息
集群环境
本文使用的集群环境是最新的阿里云 EMR 5.16.0,集群节点的属性如下:
master: 1 * ecs.g7.2xlarge 8 vCPU 32 GiB
core: 4 * ecs.g7.6xlarge 24 vCPU 96 GiB
使用的组件及版本如下:
Paimon: 0.7-SNAPSHOT(Paimon社区0.6 release版本)
Hudi: 0.14.0
Flink: 1.15
Spark: 3.3.1
OSS-HDFS: 1.0.0
本文主要由两部分组成,分别是 Paimon 和 Hudi 数据实时入湖性能测试(Flink),以及 Paimon 和 Hudi 准实时数仓全链路搭建(Flink + Spark),测试数据均存储在 EMR 的 OSS-HDFS 中。
数据实时入湖
parallelism.default: 16jobmanager.memory.process.size: 4gtaskmanager.numberOfTaskSlots: 1taskmanager.memory.process.size: 8g/16g/20gexecution.checkpointing.interval: 2minexecution.checkpointing.max-concurrent-checkpoints: 3taskmanager.memory.managed.size: 1mstate.backend: rocksdbstate.backend.incremental: truetable.exec.sink.upsert-materialize: NONE
3.1 upsert 场景
'bucket' = '16','file.format' = 'parquet','file.compression' = 'snappy','write-only' = 'true'
Hudi 表的配置如下,采用 BUCKETindex,桶个数为 16,与 Flink 并行度一致。由于 Hudi MOR 表的读取会受到参数 compaction.max_memory 的影响,将其配置为 taskmanager.memory.process.size 的一半。
'table.type' = 'MERGE_ON_READ','metadata.enabled' = 'false','index.type' = 'BUCKET','hoodie.bucket.index.num.buckets' = '16','write.operation' = 'upsert','write.tasks' = '16','hoodie.parquet.compression.codec' = 'snappy','read.tasks' = '16','compaction.schedule.enabled' = 'false','compaction.async.enabled' = 'false','compaction.max_memory' = '4096/8192/10240' -- TM process memory的一半
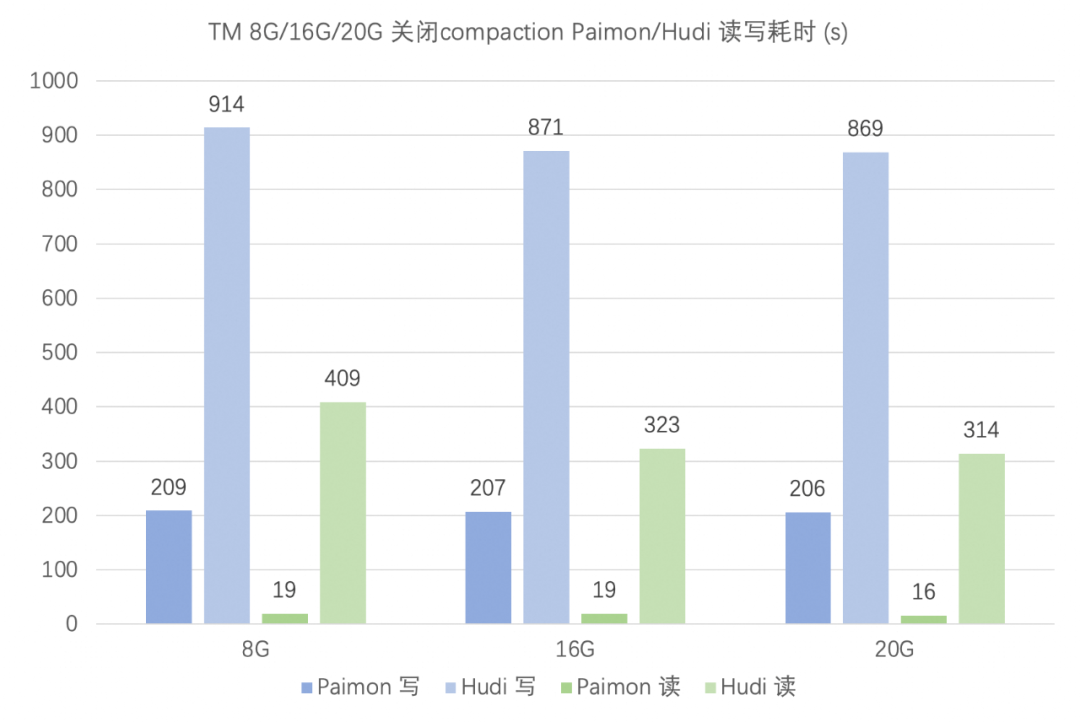
'bucket' = '16','file.format' = 'parquet','file.compression' = 'snappy','num-sorted-run.compaction-trigger' = '5' -- 默认配置
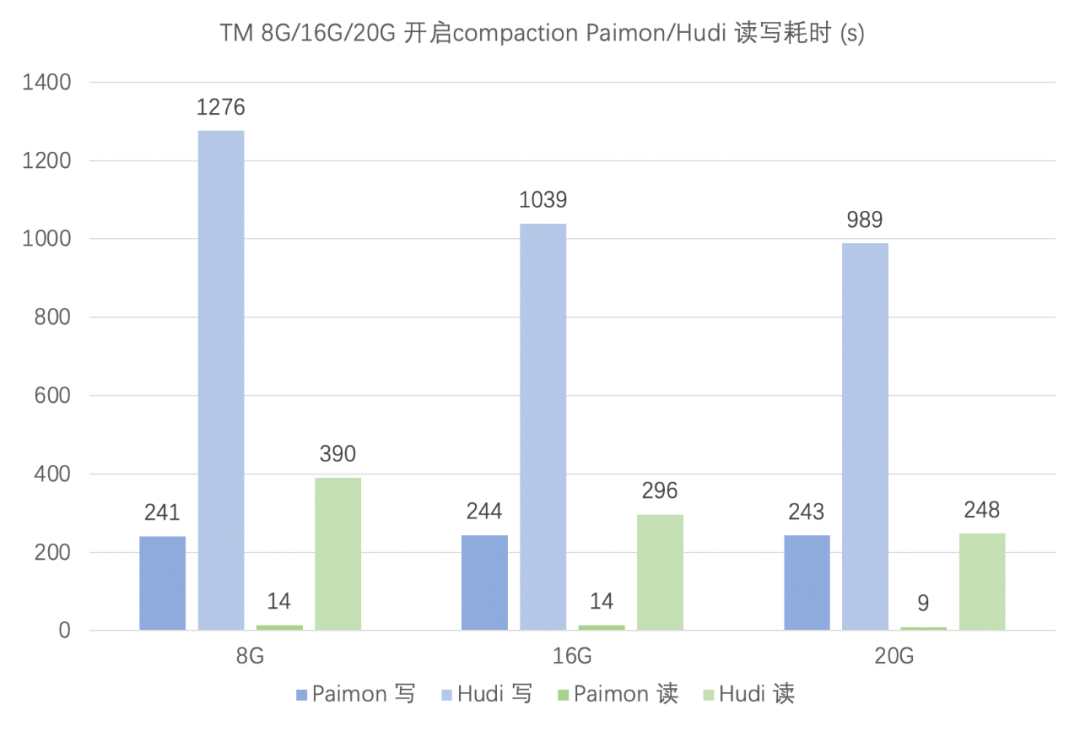
Hudi 配置:
由于测试所需的总耗时不多(checkpoint 个数也相应较少),并且随着未 compaction 的 log 文件增加,Hudi 需要的 compaction 内存将变得更大,因此配置 compaction.delta_commits 为 2 来保证在写入期间有 compaction 执行完成。
'table.type' = 'MERGE_ON_READ','metadata.enabled' = 'false','index.type' = 'BUCKET','hoodie.bucket.index.num.buckets' = '16','write.operation' = 'upsert','write.tasks' = '16','hoodie.parquet.compression.codec' = 'snappy','read.tasks' = '16','compaction.schedule.enabled' = 'true','compaction.async.enabled' = 'true','compaction.tasks' = '16','compaction.delta_commits' = '2''compaction.max_memory' = '4096/8192/10240' -- TM process memory的一半
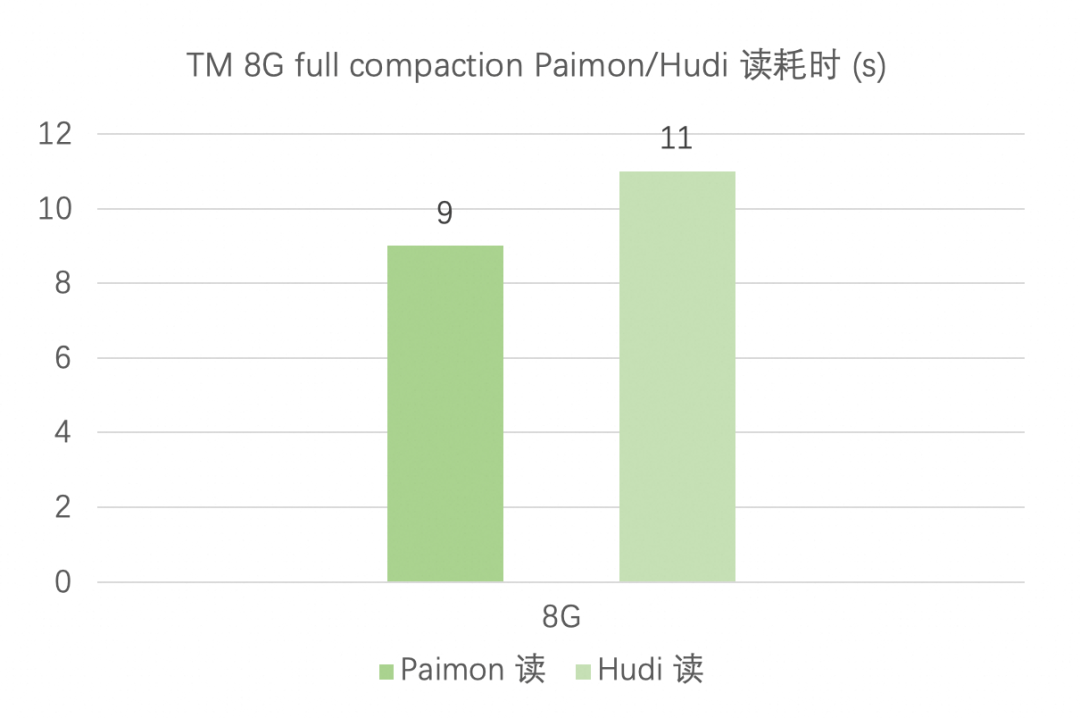
3.2 append 场景
数据入湖的另一种场景是数据 append 写,比如日志入湖。
本节测试数据源同样由 Flink datagen 产生,然后使用 Flink 写入 Paimon 和 Hudi 表中,同样统计使用 Flink 写入 5 亿条数据(在 append 场景 Paimon 和 Hudi 均不需要 bucket)的总耗时;以及使用 Flink 批读已写入的 Paimon 和 Hudi 表的总耗时。
Paimon 表的配置:
'bucket' = '-1','file.format' = 'parquet','file.compression' = 'snappy'
Hudi 表的配置:
由于单个批次数据量足够大,不存在小文件问题,因此关闭 clustering:
'table.type' = 'COPY_ON_WRITE','metadata.enabled' = 'false','write.operation' = 'insert','write.tasks' = '16','hoodie.parquet.compression.codec' = 'snappy','read.tasks' = '16','write.insert.cluster' = 'false','clustering.schedule.enabled' = 'false','clustering.async.enabled' = 'false'
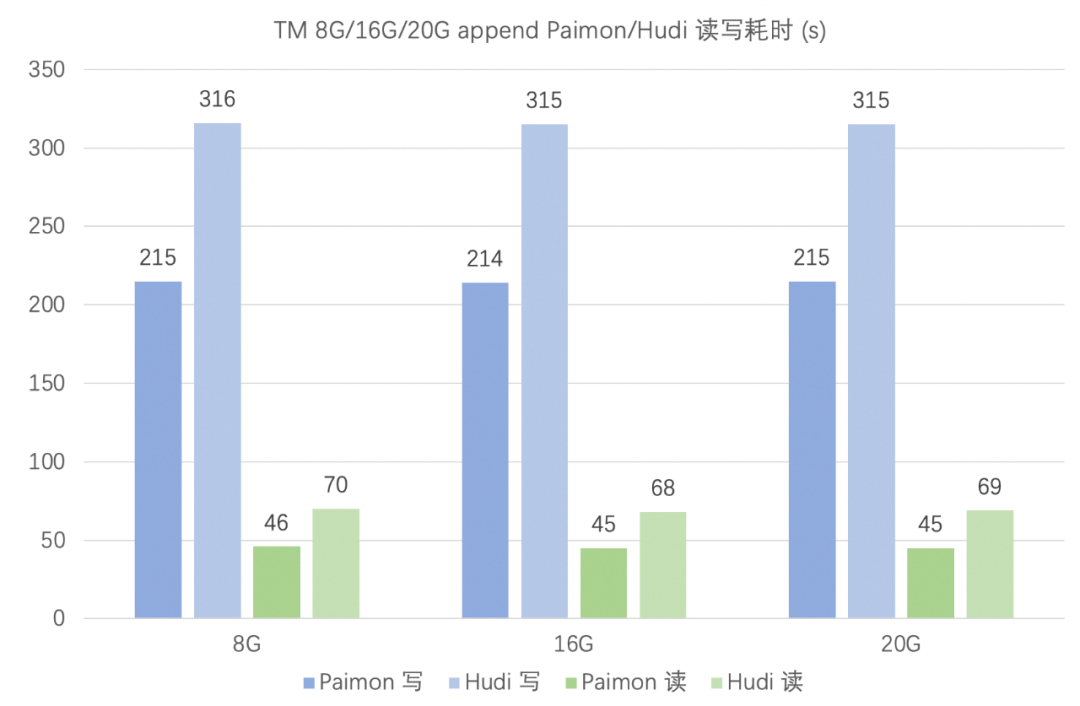
在 append 场景,Paimon 读写性能优于 Hudi,且二者都对 TM 内存要求均不高。
准实时数仓
ODS 层:通过 Flink 的 datagen connector 产生 orders(订单表,包含原始订单信息),再通过 Flink 实时写入,作为 ODS 层。 DWM 层:通过 Spark streaming 实时消费 ODS 层,产出 DWM 层 dwm_shop_users(用户-商户聚合中间表,包含中间聚合指标)。 DWS 层:通过 Spark streaming 实时消费 DWM 层的 changelog 数据,构建 DWS 层 dws_users(用户聚合指标表)以及 dws_shops(商户聚合指标表)。
4.1 datagen -> ODS
yarn-session.sh -Dparallelism.default=8 \-Djobmanager.memory.process.size=2g \-Dtaskmanager.numberOfTaskSlots=2 \-Dtaskmanager.memory.process.size=8g \-Dtaskmanager.memory.managed.size=1m \-Dexecution.checkpointing.interval=2min \-Dexecution.checkpointing.max-concurrent-checkpoints=3 \-Dstate.backend=rocksdb \-Dstate.backend.incremental=true \-Dtable.exec.sink.upsert-materialize=NONE \--detached
CREATE TEMPORARY TABLE datagen_orders(order_name STRING,order_user_id BIGINT,order_shop_id BIGINT,order_product_id BIGINT,order_fee DECIMAL(20, 2),order_state INT)WITH ('connector' = 'datagen','rows-per-second' = '10000','fields.order_user_id.kind' = 'random','fields.order_user_id.min' = '1','fields.order_user_id.max' = '10000','fields.order_shop_id.kind' = 'random','fields.order_shop_id.min' = '1','fields.order_shop_id.max' = '10000','fields.order_product_id.kind' = 'random','fields.order_product_id.min' = '1','fields.order_product_id.max' = '1000','fields.order_fee.kind' = 'random','fields.order_fee.min' = '0.1','fields.order_fee.max' = '10.0','fields.order_state.kind' = 'random','fields.order_state.min' = '1','fields.order_state.max' = '5');
CREATE TABLE IF NOT EXISTS paimon_catalog.order_dw.ods_orders(order_id STRING,order_name STRING,order_user_id BIGINT,order_shop_id BIGINT,order_product_id BIGINT,order_fee DECIMAL(20, 2),order_create_time TIMESTAMP(3),order_update_time TIMESTAMP(3),order_state INT)WITH ('bucket' = '-1','file.format' = 'parquet','file.compression' = 'snappy');INSERT INTO paimon_catalog.order_dw.ods_ordersSELECTUUID() AS order_id,order_name,order_user_id,order_shop_id,order_product_id,order_fee,NOW() AS order_create_time,NOW() AS order_update_time,order_stateFROM datagen_orders;
create TEMPORARY table ods_orders(order_id STRING,order_name STRING,order_user_id BIGINT,order_shop_id BIGINT,order_product_id BIGINT,order_fee DECIMAL(20, 2),order_create_time TIMESTAMP(3),order_update_time TIMESTAMP(3),order_state INT)WITH ('connector' = 'hudi','path' = '/xxx/hudi/order_dw.db/ods_orders','precombine.field' = 'order_update_time','table.type' = 'COPY_ON_WRITE','hoodie.database.name' = 'order_dw','hoodie.table.name' = 'ods_orders','hoodie.datasource.write.recordkey.field' = 'order_id','metadata.enabled' = 'false','write.operation' = 'insert','write.tasks' = '8','hoodie.parquet.compression.codec' = 'snappy','write.insert.cluster' = 'false','clustering.schedule.enabled' = 'false','clustering.async.enabled' = 'false');INSERT INTO ods_ordersSELECTUUID() AS order_id,order_name,order_user_id,order_shop_id,order_product_id,order_fee,NOW() AS order_create_time,NOW() AS order_update_time,order_stateFROM datagen_orders;
4.2 ODS -> DWM
CREATE TABLE paimon_catalog.order_dw.dwm_shop_users(shop_id BIGINT,user_id BIGINT,ds STRING COMMENT '小时',pv BIGINT COMMENT '该小时内,该用户在该商户的消费次数',fee_sum DECIMAL(20, 2) COMMENT '该小时内,该用户在该商户的消费总金额')tblproperties ('primary-key' = 'shop_id, user_id, ds','bucket' = '8','changelog-producer' = 'lookup','file.format' = 'parquet','file.compression' = 'snappy','merge-engine' = 'aggregation','fields.pv.aggregate-function' = 'sum','fields.fee_sum.aggregate-function' = 'sum','metadata.stats-mode' = 'none');
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions.{date_format, lit}object PaimonOds2DwmJob {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().getOrCreate()val sourceLocation = "/xxx/paimon/order_dw.db/ods_orders"val targetLocation = "/xxx/paimon/order_dw.db/dwm_shop_users"val checkpointDir = "/xxx/paimon/order_dw.db/dwm_shop_users_checkpoint"import spark.implicits._spark.readStream.format("paimon").load(sourceLocation).select($"order_shop_id",$"order_user_id",date_format($"order_create_time", "yyyyMMddHH").alias("ds"),lit(1L),$"order_fee").writeStream.format("paimon").option("checkpointLocation", checkpointDir).start(targetLocation)spark.streams.awaitAnyTermination()}}
public class OrdersLakeHouseMerger extends HoodieAvroRecordMerger {@Overridepublic Option<Pair<HoodieRecord, Schema>> merge(HoodieRecord older, Schema oldSchema, HoodieRecord newer, Schema newSchema, TypedProperties props) throws IOException {...Object oldData = older.getData();GenericData.Record oldRecord = (oldData instanceof HoodieRecordPayload)? (GenericData.Record) ((HoodieRecordPayload) older.getData()).getInsertValue(oldSchema).get(): (GenericData.Record) oldData;Object newData = newer.getData();GenericData.Record newRecord = (newData instanceof HoodieRecordPayload)? (GenericData.Record) ((HoodieRecordPayload) newer.getData()).getInsertValue(newSchema).get(): (GenericData.Record) newData;merge uvif (HoodieAvroUtils.getFieldVal(newRecord, "uv") != null && HoodieAvroUtils.getFieldVal(oldRecord, "uv") != null) {newRecord.put("uv", (Long) oldRecord.get("uv") + (Long) newRecord.get("uv"));}merge pvif (HoodieAvroUtils.getFieldVal(newRecord, "pv") != null && HoodieAvroUtils.getFieldVal(oldRecord, "pv") != null) {newRecord.put("pv", (Long) oldRecord.get("pv") + (Long) newRecord.get("pv"));}merge fee_sumif (HoodieAvroUtils.getFieldVal(newRecord, "fee_sum") != null && HoodieAvroUtils.getFieldVal(oldRecord, "fee_sum") != null) {BigDecimal l = new BigDecimal(new BigInteger(((GenericData.Fixed) oldRecord.get("fee_sum")).bytes()), 2);BigDecimal r = new BigDecimal(new BigInteger(((GenericData.Fixed) newRecord.get("fee_sum")).bytes()), 2);byte[] bytes = l.add(r).unscaledValue().toByteArray();byte[] paddedBytes = new byte[9];System.arraycopy(bytes, 0, paddedBytes, 9 - bytes.length, bytes.length);newRecord.put("fee_sum", new GenericData.Fixed(((GenericData.Fixed) newRecord.get("fee_sum")).getSchema(), paddedBytes));}HoodieAvroIndexedRecord hoodieAvroIndexedRecord = new HoodieAvroIndexedRecord(newRecord);return Option.of(Pair.of(hoodieAvroIndexedRecord, newSchema));}}
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions.{date_format, lit}object Ods2DwmJob {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().getOrCreate()val sourceLocation ="/xxx/hudi/order_dw.db/ods_orders"val targetLocation = "/xxx/hudi/order_dw.db/dwm_shop_users"val checkpointDir = "/xxx/hudi/order_dw.db/dwm_shop_users_checkpoint"import spark.implicits._spark.readStream.format("hudi").load(sourceLocation).select($"order_shop_id".alias("shop_id"),$"order_user_id".alias("user_id"),date_format($"order_create_time", "yyyyMMddHH").alias("ds"),lit(1L).alias("pv"),$"order_fee".alias("fee_sum")).writeStream.format("hudi").option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").option("hoodie.datasource.write.recordkey.field", "shop_id, user_id, ds").option("hoodie.datasource.write.precombine.field", "ds").option("hoodie.database.name", "order_dw").option("hoodie.table.name", "dwm_shop_users").option("hoodie.metadata.enable", "false").option("hoodie.index.type", "BUCKET").option("hoodie.bucket.index.num.buckets", "8").option("hoodie.datasource.write.operation", "upsert").option("hoodie.datasource.write.record.merger.impls", "org.apache.hudi.common.model.merger.OrdersLakeHouseMerger").option("hoodie.parquet.compression.codec", "snappy").option("hoodie.table.cdc.enabled", "true").option("hoodie.table.cdc.supplemental.logging.mode", "data_before_after").option("checkpointLocation", checkpointDir).start(targetLocation)spark.streams.awaitAnyTermination()}}
spark-submit --class Ods2DwmJob \--master yarn \--deploy-mode cluster \--name PaimonOds2DwmJob \--conf spark.driver.memory=2g \--conf spark.driver.cores=2 \--conf spark.executor.instances=4 \--conf spark.executor.memory=16g \--conf spark.executor.cores=2 \--conf spark.yarn.submit.waitAppCompletion=false \./paimon-spark-streaming-example.jarspark-submit --class Ods2DwmJob \--master yarn \--deploy-mode cluster \--name HudiOds2DwmJob \--conf spark.driver.memory=2g \--conf spark.driver.cores=2 \--conf spark.executor.instances=4 \--conf spark.executor.memory=16g \--conf spark.executor.cores=2 \--conf spark.yarn.submit.waitAppCompletion=false \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension \--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog \./hudi-spark-streaming-example.jar
性能对比
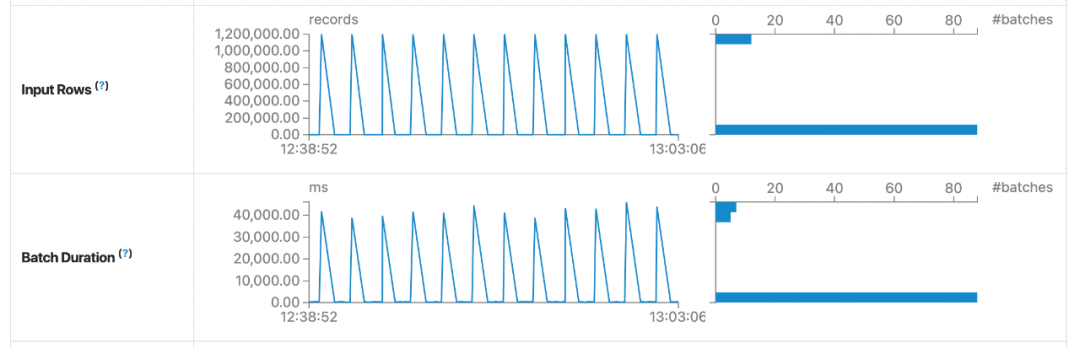
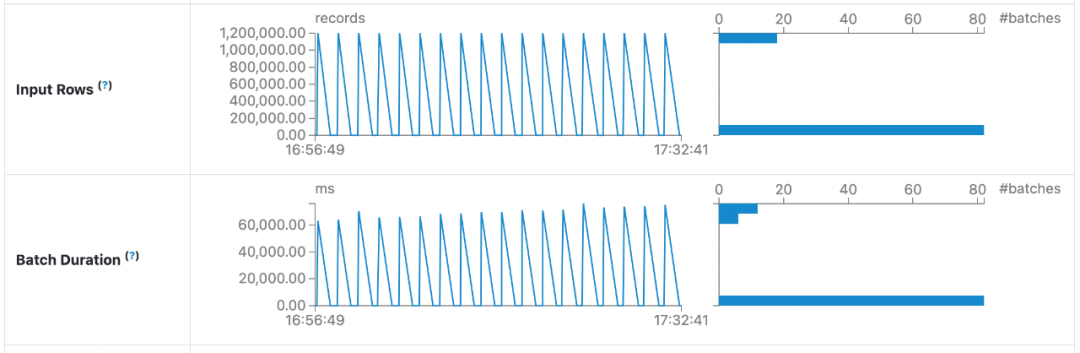
4.3 DWM -> DWS
CREATE TABLE paimon_catalog.order_dw.dws_users(user_id BIGINT,ds STRING COMMENT '小时',fee_sum DECIMAL(20, 2) COMMENT '该小时内,该用户的消费总金额')tblproperties ('primary-key' = 'user_id, ds','bucket' = '8','merge-engine' = 'aggregation','fields.fee_sum.aggregate-function' = 'sum');CREATE TABLE paimon_catalog.order_dw.dws_shops(shop_id BIGINT,ds STRING COMMENT '小时',uv BIGINT COMMENT '该小时内,该商户的消费总人数',pv BIGINT COMMENT '该小时内,该商户的消费总次数',fee_sum DECIMAL(20, 2) COMMENT '该小时内,该商户的消费总金额')tblproperties ('primary-key' = 'shop_id, ds','bucket' = '8','merge-engine' = 'aggregation','fields.uv.aggregate-function' = 'sum','fields.pv.aggregate-function' = 'sum','fields.fee_sum.aggregate-function' = 'sum');
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions.{lit, when}object Dwm2DwsJob {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().getOrCreate()val sourceLocation = "/xxx/paimon/order_dw.db/dwm_shop_users"val targetLocation1 = "/xxx/paimon/order_dw.db/dws_users"val checkpointDir1 = "/xxx/paimon/order_dw.db/dws_users_checkpoint"val targetLocation2 = "/xxx/paimon/order_dw.db/dws_shops"val checkpointDir2 = "/xxx/paimon/order_dw.db/dws_shops_checkpoint"import spark.implicits._val df = spark.readStream.format("paimon").option("read.changelog", "true").load(sourceLocation)df.select($"user_id",$"ds",when($"_row_kind" === "+I" || $"_row_kind" === "+U", $"fee_sum").otherwise($"fee_sum" * -1).alias("fee_sum")).writeStream.format("paimon").option("checkpointLocation", checkpointDir1).start(targetLocation1)df.select($"shop_id",$"ds",when($"_row_kind" === "+I" || $"_row_kind" === "+U", lit(1L)).otherwise(lit(-1L)).alias("uv"),when($"_row_kind" === "+I" || $"_row_kind" === "+U", $"pv").otherwise($"pv" * -1).alias("pv"),when($"_row_kind" === "+I" || $"_row_kind" === "+U", $"fee_sum").otherwise($"fee_sum" * -1).alias("fee_sum").writeStream.format("paimon").option("checkpointLocation", checkpointDir2).start(targetLocation2)spark.streams.awaitAnyTermination()}}
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions.{col, get_json_object, lit, when}import org.apache.spark.sql.types.{DecimalType, LongType}object Dwm2DwsJob {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().getOrCreate()val sourceLocation ="/xxx/hudi/order_dw.db/dwm_shop_users"val targetLocation1 = "/xxx/hudi/order_dw.db/dws_users"val checkpointDir1 = "/xxx/hudi/order_dw.db/dws_users_checkpoint"val targetLocation2 = "/xxx/hudi/order_dw.db/dws_shops"val checkpointDir2 = "/xxx/hudi/order_dw.db/dws_shops_checkpoint"import spark.implicits._val df = spark.readStream.format("hudi").option("hoodie.datasource.query.type", "incremental").option("hoodie.datasource.query.incremental.format", "cdc").load(sourceLocation)df.select(get_json_object($"after", "$.user_id").cast(LongType).alias("user_id"),get_json_object($"after", "$.ds").alias("ds"),when(get_json_object($"before", "$.fee_sum").isNotNull, get_json_object($"after", "$.fee_sum").cast(DecimalType(20, 2)) - get_json_object($"before", "$.fee_sum").cast(DecimalType(20, 2))).otherwise(get_json_object($"after", "$.fee_sum").cast(DecimalType(20, 2))).alias("fee_sum")).writeStream.format("hudi").option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").option("hoodie.datasource.write.recordkey.field", "user_id, ds").option("hoodie.datasource.write.precombine.field", "ds").option("hoodie.database.name", "order_dw").option("hoodie.table.name", "dws_users").option("hoodie.metadata.enable", "false").option("hoodie.index.type", "BUCKET").option("hoodie.bucket.index.num.buckets", "8").option("hoodie.datasource.write.operation", "upsert").option("hoodie.datasource.write.record.merger.impls", "org.apache.hudi.common.model.merger.OrdersLakeHouseMerger").option("hoodie.parquet.compression.codec", "snappy").option("checkpointLocation", checkpointDir1).start(targetLocation1)df.select(get_json_object($"after", "$.shop_id").cast(LongType).alias("shop_id"),get_json_object($"after", "$.ds").alias("ds"),when(get_json_object($"before", "$.fee_sum").isNotNull, lit(0L)).otherwise(lit(1L)).alias("uv"),when(get_json_object($"before", "$.fee_sum").isNotNull, get_json_object($"after", "$.pv").cast(LongType) - get_json_object($"before", "$.pv").cast(LongType)).otherwise(get_json_object($"after", "$.pv").cast(LongType)).alias("pv"),when(get_json_object($"before", "$.fee_sum").isNotNull, get_json_object($"after", "$.fee_sum").cast(DecimalType(20, 2)) - get_json_object($"before", "$.fee_sum").cast(DecimalType(20, 2))).otherwise(get_json_object($"after", "$.fee_sum").cast(DecimalType(20, 2))).alias("fee_sum")).writeStream.format("hudi").option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").option("hoodie.datasource.write.recordkey.field", "shop_id, ds").option("hoodie.datasource.write.precombine.field", "ds").option("hoodie.database.name", "order_dw").option("hoodie.table.name", "dws_shops").option("hoodie.metadata.enable", "false").option("hoodie.index.type", "BUCKET").option("hoodie.bucket.index.num.buckets", "8").option("hoodie.datasource.write.operation", "upsert").option("hoodie.datasource.write.record.merger.impls", "org.apache.hudi.common.model.merger.OrdersLakeHouseMerger").option("hoodie.parquet.compression.codec", "snappy").option("checkpointLocation", checkpointDir2).start(targetLocation2)spark.streams.awaitAnyTermination()}}
spark-submit --class Dwm2DwsJob \--master yarn \--deploy-mode cluster \--name PaimonDwm2DwsJob \--conf spark.driver.memory=2g \--conf spark.driver.cores=2 \--conf spark.executor.instances=4 \--conf spark.executor.memory=8g \--conf spark.executor.cores=2 \--conf spark.yarn.submit.waitAppCompletion=false \./paimon-spark-streaming-example.jarspark-submit --class Dwm2DwsJob \--master yarn \--deploy-mode cluster \--name HudiDwm2DwsJob \--conf spark.driver.memory=2g \--conf spark.driver.cores=2 \--conf spark.executor.instances=4 \--conf spark.executor.memory=8g \--conf spark.executor.cores=2 \--conf spark.yarn.submit.waitAppCompletion=false \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension \--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog \./hudi-spark-streaming-example.jar
性能对比
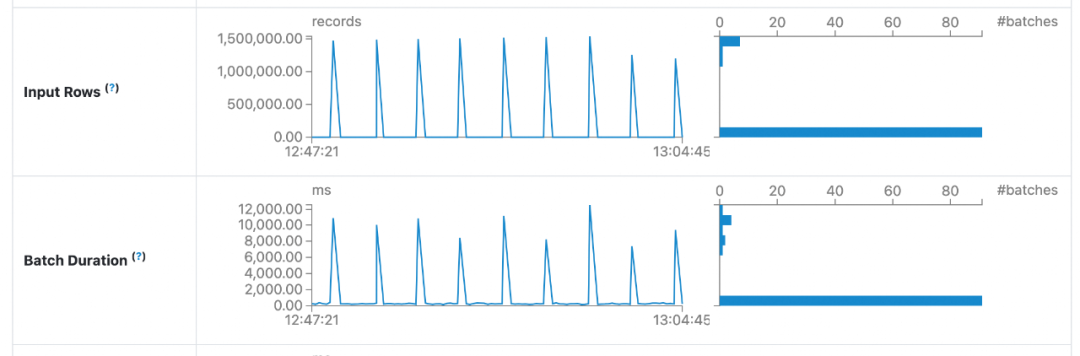
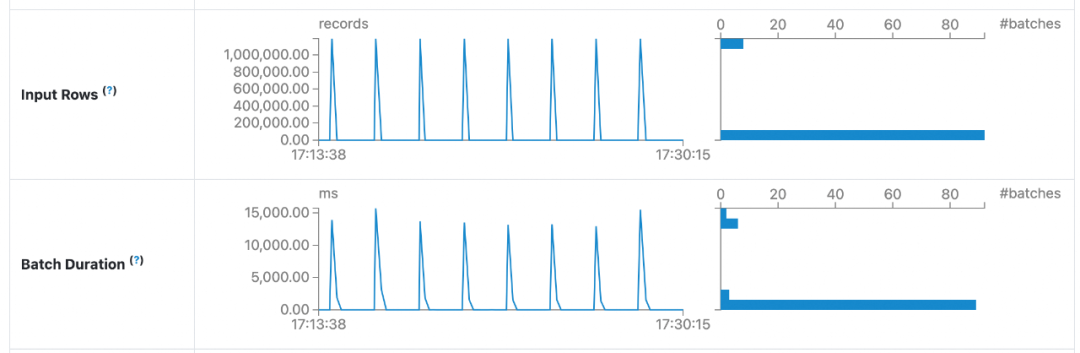
4.4 SparkSQL 查询
-- SparkSQL 查询 ods_ordersselect order_id, order_user_id, order_shop_id, order_fee, order_create_timefrom order_dw.ods_ordersorder by order_create_time desc limit 10;-- SparkSQL 查询 dws_shopsselect shop_id, ds, uv, pv, fee_sumfrom order_dw.dws_shopswhere ds = '2023120100' order by ds, shop_id limit 10;
总结
在实时入湖场景中,Paimon 具有比 Hudi 更强的读写性能,并且对内存的需求更小。
在数仓 DWM、DWS 层构建过程中,由于 Paimon 内置了 mergeFunction 功能,可以通过配置参数直接构建聚合指标,而 Hudi 需要通过手动编写自定义 Payload 或者 Merger 来实现。
在基于 Spark 构建的准实时数仓的各层链路中,Paimon 计算单个 batch 的耗时均比 Hudi 更短。
文章超链接:


 点击「阅读原文」,在线观看FFA 2023 会后资料~
点击「阅读原文」,在线观看FFA 2023 会后资料~