





海量数据库所配备的生态工具——异构数据库一键式迁移平台exBase是针对数据库迁移痛点定制的解决方案。
增量同步功能使用基于日志的增量重做机制,对网络带宽消耗少、数据延迟低、能有效保持事务原子性,并能够支持断点续传。
实时增量数据同步,主要是针对数据源的变化进行跟踪采集,将变化的数据传输到目标端,保证目标端的数据与源端一致。
在此基础上,海量数据研发团队对增量同步的架构进行了升级改造,采用数管分离的架构模式,使其扩展性更强,结构更为清晰。
增量同步架构升级
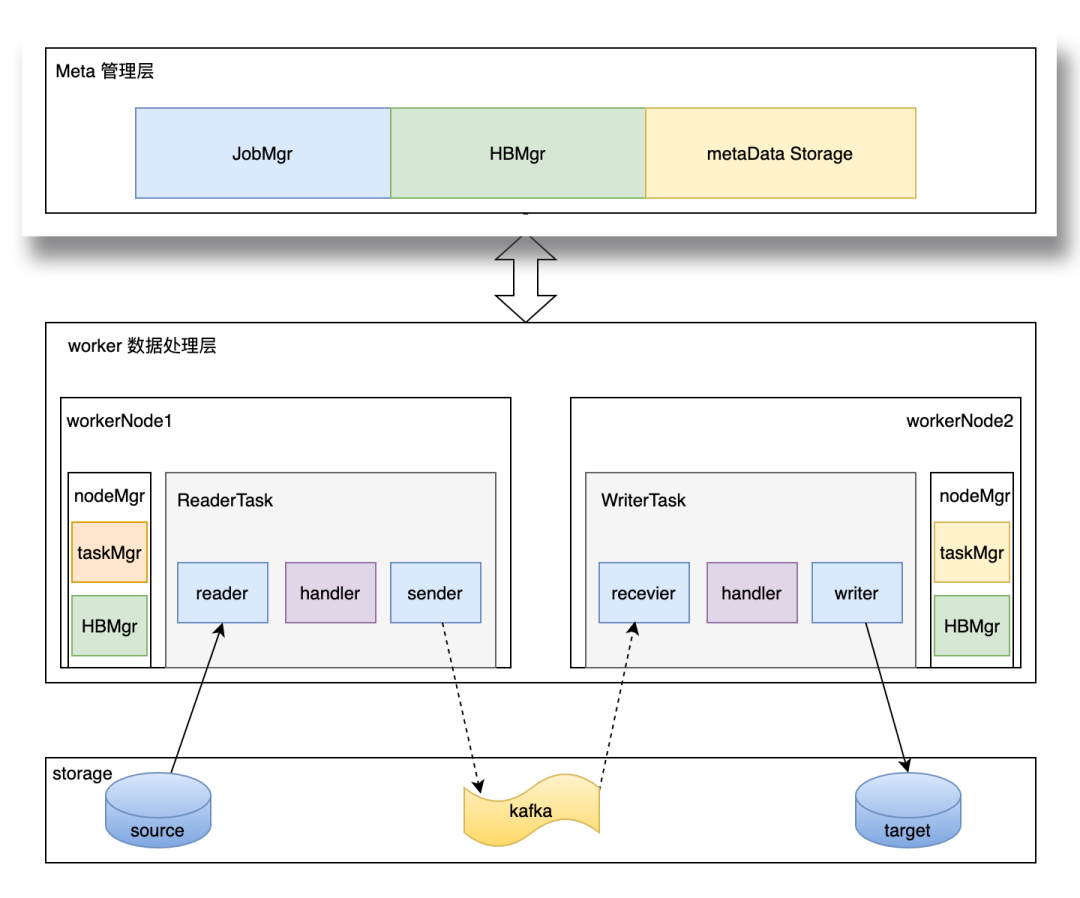
相较于传统架构,新增Meta管理层,负责存储增量任务相关数据并管理和调度工作流。Meta管理层主要由JobMgr、HBMgr、MetaData Storage模块组成。
JobMgr主要负责增量任务的生命周期管理工作。包括job的创建,job信息管理,task的分发与调度,等工作;HBMgr是心跳管理组件,负责与各Node节点的心跳交互,负责接收处理心跳及心跳中包含的task状态等信息;MetaData Storage是元数据存储模块,主要负责持久化job信息、Node信息等相关重要数据。
该架构实现了管理能力的抽象,由Meta层对整体数据流行为进行调度和管理。数据面worker层的开发人员,可与专注于数据本身的采集与装载,而不需要考虑业务相关场景。
01 数据流转
新架构增加了对采集数据的归一化处理,且采用了采集端和目标端完全分离的架构,即Reader不需要感知目标库类型,只需要将采集到的数据按照归一化逻辑统一处理为同样的格式的Record;Writer不需要感知采集端类型,只需要将数据按照目标库的数据类型装载即可。如图所示:
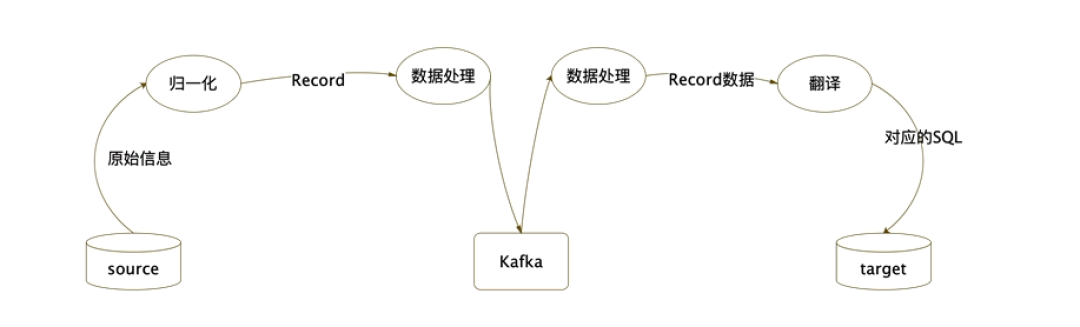
数据在ReaderTask和WriterTask之间采用kafka进行数据传递,保证两端解耦,边界更清晰。数据在各Task内的流转采用流水线架构模式,以提升整体同步的速率。
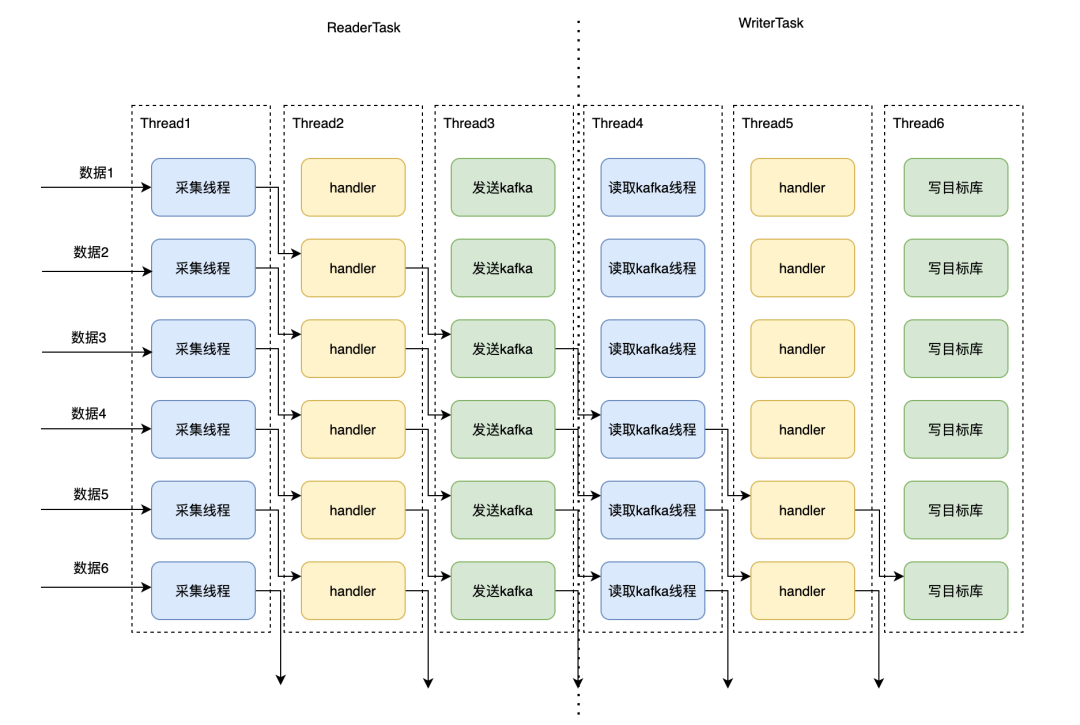
各线程之间数据的传输通过内部队列进行,将task进行流水线架构改造后,可使各单元模块功能更内聚,模块之间更解耦,方便后续扩展,增加可维护性;且该流水线架构可较大提高整个系统处理数据的吞吐率,进而降低增量同步的延迟时间,提升同步的效率。
02 新增同步异常处理策略机制
之前exBase遇到数据异常仅支持异常终止并抛出错误,无法应对用户对链路持续性要求高的场景,因此需要增加异常自动处理机制(以目标端数据为准/以源端为准进行数据覆写或跳过的操作),可以自动识别和解决数据异常带来的问题,使得增量同步链路得以持续运行,避免因轻微数据异常导致链路中断。
目前新增量中可支持异常类型和处理策略如下:
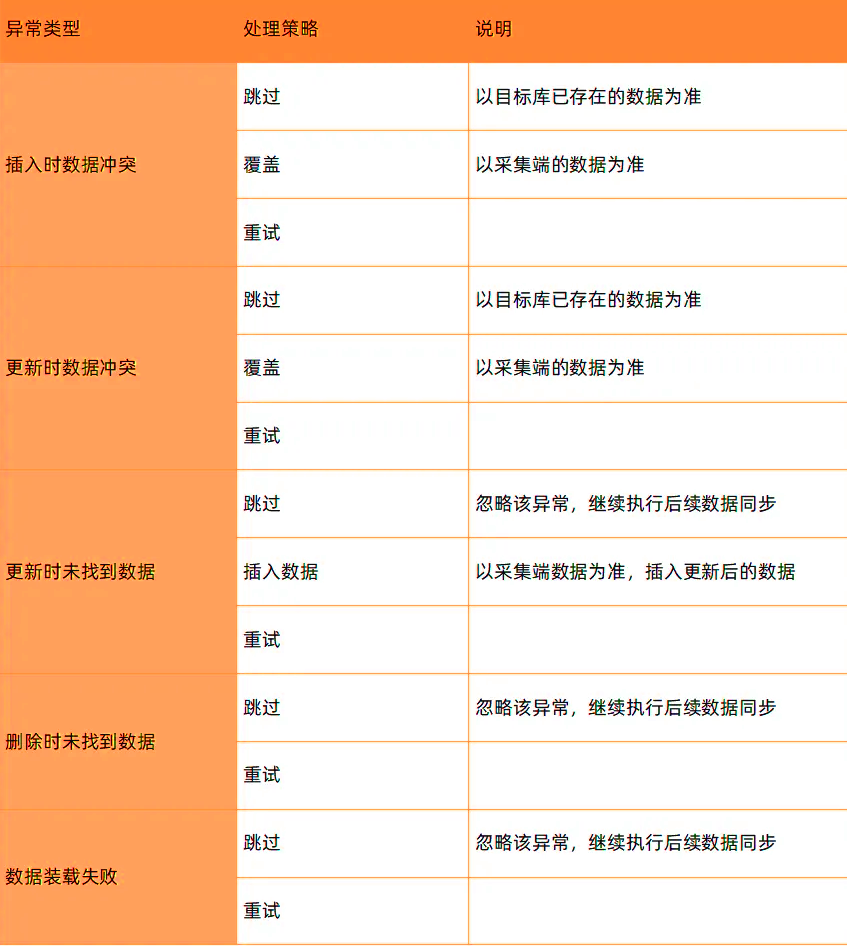
在exBase的前端页面可以查询增量同步任务执行中出现的异常事件及相应的处理方式,方便用户及时核对数据。
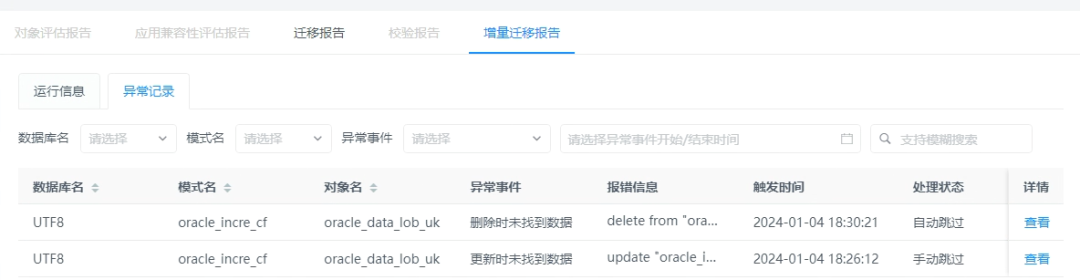
通过对增量架构升级,增强了其扩展性,提升了可维护性,为后面高可用架构部署打下基础,具有独立演进,持续迭代的能力。通过对增量同步的功能升级,支持了异常处理策略的设置,提升了整体服务的可用性。通过以上改造升级,海量数据exBase一键式异构数据库迁移平台可以更好为客户服务,以更短的周期支持客户的差异化需求。
迁移能力持续升级
通过对增量架构升级,实现了采集与装载的完全解耦,子模块之间的流水线架构增强了其扩展性,提升了可维护性,为后面高可用架构部署及端到端部署方式打下基础,具备了独立演进,持续迭代的能力。
通过增加对增量同步异常处理策略的支持,在某些数据不一致的场景下可以保证增量任务不间断的进行数据同步,同时用户可以实时查看到同步工具处理的异常数据的信息,进而提升了整体服务的可用性,提高了整体同步的准确率。
通过以上改造升级,海量数据exBase一键式异构数据库迁移平台可以更好为客户服务,以更短的周期支持客户的差异化需求。
• END •
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列、海量大数据Datalink系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

