前言
 图1:数之不尽的图计算框架
图1:数之不尽的图计算框架
洞察力敏锐的读者,一定看到了图1中赫然有Hadoop的名字,没错,当市场的热点(风口)来临的时候,什么框架都敢宣称支持图计算,不管到底有多不靠谱。【关于“Hadoop已死!”的话题,曾刊登在《关于开源和闭源的探讨(上)》中,感兴趣的朋友可登录“XAI嬴图”知乎账号搜索阅读】
Apache Spark也有自己的图计算组件——GraphX,支持着数量少得可怜的几种图算法,并且所有的算法都有一个特点就是非常浅层的计算,例如PageRank网页排序、Connected Component联通分量、Triangle Counting三角形计算,但是,任何关于深层计算的图算法都没有或者根本无法支持,例如全图K-hop、Random Walking随机游走、Louvainl鲁汶社区识别等等。
这也是基于BSP理念构建的“大规模分布式”系统的一个通病,对于浅层(短链)的存储、查询与算法是可以较好地支持,但是一旦进入深度(长链)的查询、分析与计算就会效率极为低下——因为深度关联分析意味着系统的多个实例间需要频繁的交互,进而导致效率大幅降低,反应时长大幅增加……直至无法返回计算结果。不知道那些在GraphX之上开发“自研、原生图数据库”的厂家们,是否有突破GraphX的这诸多限制?Spark + GraphX的存在,充分验证了那句话——开源不是免费(天下没有免费的午餐)。
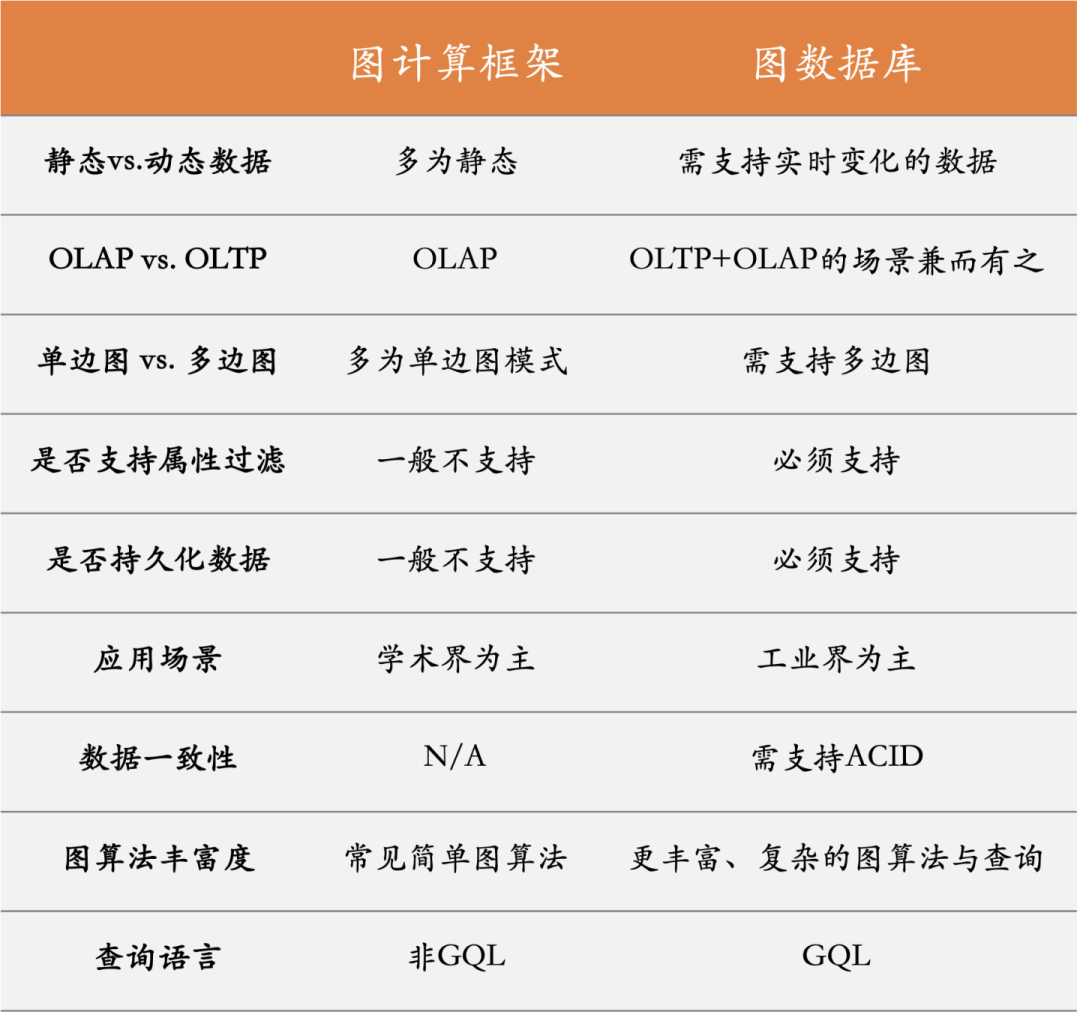 图2:图计算框架 VS. 图数据库
图2:图计算框架 VS. 图数据库
我们把图计算框架与图数据库做一个完整的对比,就会发现它们之间的差异极大,例如:
数据一致性:图计算框架不care,基本采用对当前或某个时点的数据进行静态加载(例如映射入内存),算完就扔掉之前加载过的数据,这个逻辑倒是和Hadoop如出一辙。所谓持久化,就是磁盘上的源文。
查询语言
:why bother? 图计算框架一般都采用的是API调用的方式。
持久化?图计算框架基本不考虑这些问题。
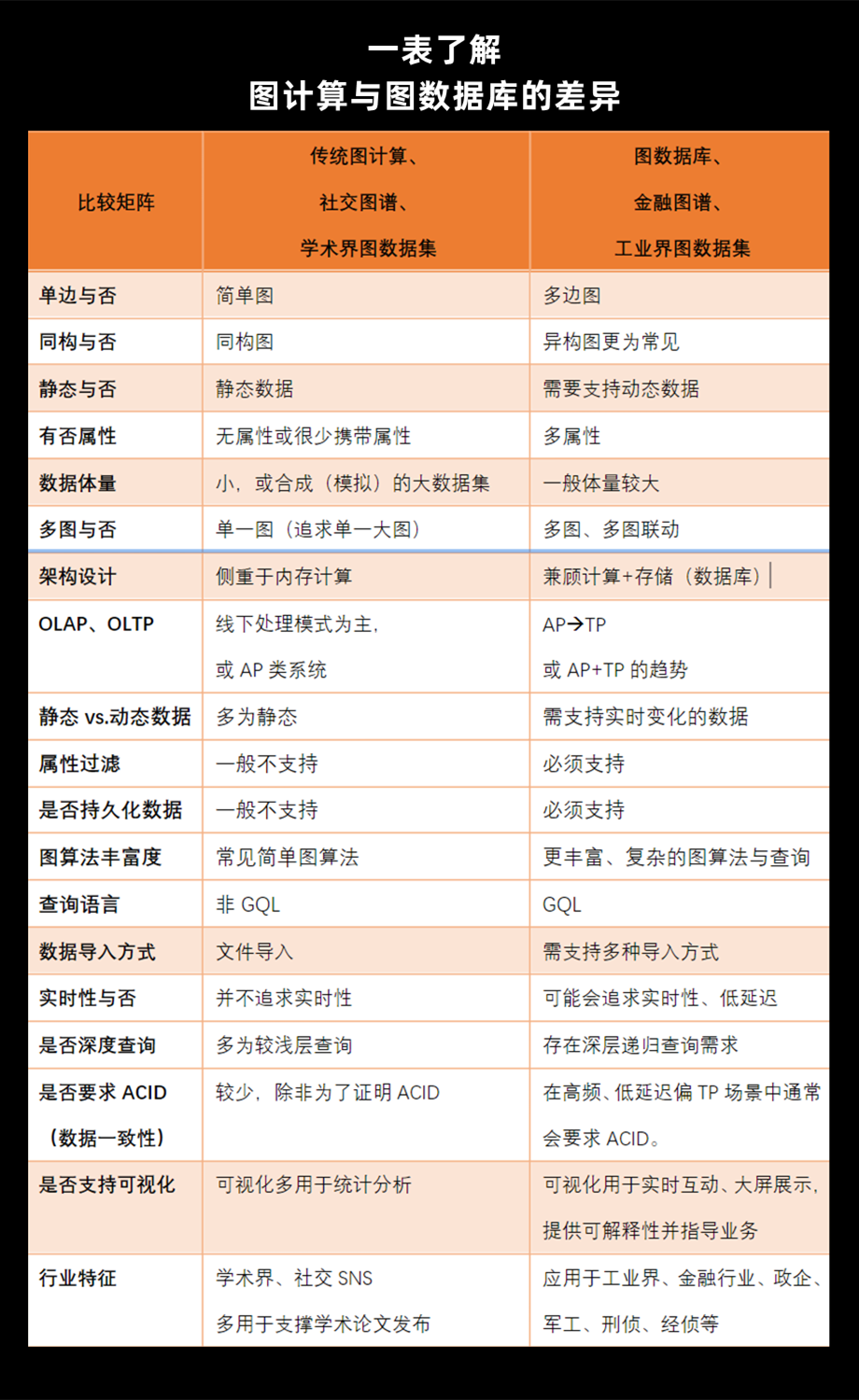
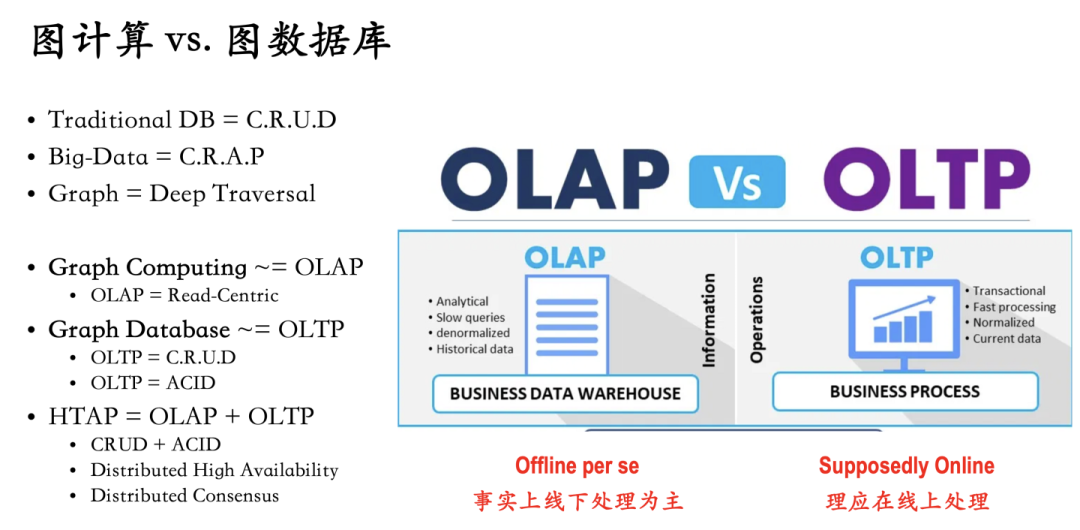 图3:图计算与图数据库的差异比较
图3:图计算与图数据库的差异比较
从另外一个维度(数据处理模式)来看,图计算是侧重于OLAP类型的处理,偏线下、批处理、非实时模式的数据分析,而图数据库则更多的需要先具备线上、实时的数据更新的能力(也包括读写、删除、数据一致性保持的能力),并在此基础上通过架构层面的扩展性(包括分布式)来支持OLTP与OLAP的融合,业界也称之为HTAP模式,即在一个图数据库的集群内同时可以支持OLTP与OLAP的工作模式——它本质上的逻辑是一方面允许数据库的增删改查(以及数据一致性保持),另一方面允许处理复杂的图查询与算法。理论上,在最小为1台主机或实例的情况下,也可以通过分时或并行处理等方法实现HTAP(尽管听起来颇具讽刺意味),但是一般而言最小三实例的“分布式共识”集群上,可以更优雅的实现HTAP(例如一台实例接受写与更新操作,并向另外两台实时同步,以实现一致性;同时指定或动态选择其它实例来接受AP类型的数据分析请求。【注:在后面的知识点中,我们会单独详解分布式图数据库的实现模式】

有哪些场景是必须要用图数据库的呢?
我们拉个清单列表以飧诸位读者:
图数据库适用于任何复杂数据分析场景(8大类场景):

对分析深度有要求的(关联分析);
对分析维度有要求的(多角度分析);
对分析的准确度有要求的(图模型的分析准确度更高!不像ML和AI基本靠猜来撞大运);
对分析的时效性(及时性)有限制的(高性能、实时化、近实时分析);
对分析的灵活性有要求的(不断变动的业务筛选、组装条件);
对分析的可解释性(可审计、可追溯)有要求的;
对分析的可视化、直观性有要求的(所见即所得、多维数据的可视化、直观呈现);
对数据的实时性有需求的:有两个层面的实时性,一个是数据实时更新,一个是数据非实时,但分析结果要实时。
看到上面的8大类需求场景,以及多类之间的任意组合,可以说是无法穷举。再加上SQL和传统数据库、数仓“肆虐”多年,早已让企业不堪负重,从五花八门的数据治理到数字资产管理,再到各类业务数据分析、BI需求,可以说图数据库的应用场景是不计其数的。
具体的场景包括:(不完全举例,也不限定于反欺诈、智能推荐场景)
风控类
在线反欺诈
在线风控模型(区别于其它技术模式的线下跑批模型)
实时风控反欺诈
信贷风控
反洗钱穿透
最终受益人UBO穿透识别
投融资网络分析
风险管理与分析类
风险的科学计量、精准计量、实时计量
穿透、下钻
溯源、归因分析
模拟、情景模拟
压测
跨指标、多指标协同、关联分析
智能数据分析与管理类
多源、多系统数据融合与分析
数据治理、血缘分析等
资产管理、穿透分析等
智能搜索类、智能推荐类
因果查询
多维度搜索、高维搜索
智能推荐
NLP知识图谱
模型增效、增强类
提升传统特征工程、机器学习的效率和准确率:大幅(10x以上)提高数据采样效率、训练效率;大幅提高模型准确率(图模型能更准确地反映真实世界的各类用户行为,让分析与运算结果更准确)
通过设计和建设(高维)图模型来实现对业务流程与模式的更精准的模拟、预测、压测……
其它场景,to be identified……
【更多关于图计算与图数据库的区别的延展阅读,感兴趣的读者可点击:文库 | 图计算与图数据库差异简析】
【小结】

[1]《图数据库原理、架构与应用》; 孙宇熙,嬴图团队;