





本文汇总了三篇 TiDB 运维指南,主要介绍了如何使用 HyBench 对 TiDB进行测试、TiDB 集群的各种容量计算方式以及利用 Prometheus 编写 TiDB 巡检脚本的方法。
01
背景
这篇文章介绍了如何使用 HyBench 对 TiDB 进行测试,并简述 HyBench 适配 TiDB 的注意事项。
Hybench 是一款由中国软件评测中心、清华大学联合牵头,多家公司共同研发的 HTAP 数据库基准测试工具。
TiDB 是一款兼容 MySQL 的数据库,Hybench 已在 Gitee 开源,支持 MySQL 数据库,通过修改 HyBench 源码以适配 TiDB。
前置需求
● 启动一个 TiDB 本地测试集群
● 准备 JDK 17,并配置环境变量
● 安装 Maven
运行测试
●修改数据库连接信息
依据实际需求修改配置文件 conf/db.prop 中的 HOST, IP, USERNAME, PASSWORD 等信息。
● 生成测试数据
● 初始化表结构
● 初始化表索引
● 导入测试数据
● 连接数据库,查看库表信息
● 运行 TP 负载测试
● 清理测试表数据
注意事项
本文基于开源数据库压测软件 HyBench 对 TiDB 进行适配,并做简单测试,提出以下注意事项:
● HyBench 需要使用 JDK 17,这在 README 中有一处提及,全文搜索一下比较容易找到。
○ 封装了 java 执行命令(需要配置 jdk17)
● 目前,开源版本只支持 1X、10x 数据,后续在商业版本中会增加 100x,1000x 及更大规模的数据。
○ 对应文件 src/main/resource/parameters.toml 中可以看到 [1x] 和 [10x] 。
● 导入数据使用的 SQL 命令为 LOAD DATA LOCAL INFILE ,是 db.prop 配置文件中,JDBC 连接串需要增加参数 allowLoadLocalInfile=true 。4. 自 v7.4.0 起,TiDB 已经兼容 MySQL 8.0 的主要功能,推荐使用最新版本的 MySQL Connector/J 来连接 TiDB,因此源码工程依赖升级为 mysql-connector-j:8.2.0
● 项目地址:shawnyan/hybench (https://gitee.com/shawnyan/hybench/ )
● 如果没有特殊需求,优先推荐使用 TiUP bench 组件对 TiDB 进行压测。
点击此处丨查看原文
02
背景
TiDB 集群的监控面板里面有两个非常重要、且非常常用的指标,相信用了 TiDB 的都见过:
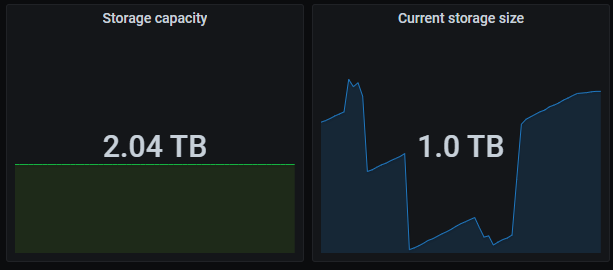
○ Storage capacity:集群的总容量
○ Current storage size:集群当前已经使用的空间大小
当你准备了一堆服务器,经过各种思考设计部署了一个 TiDB 集群,有没有想过这两个指标和服务器磁盘之间到底是啥关系?
反正我们经常被客户问这个问题,以前虽然能说出个大概,总体方向上没错,但是深究一下其实并不严谨,这次翻了源码彻底把这个问题搞清楚。开始之前再卖一个关子,大家可以看看自己手上的集群监控有没有这种情况:
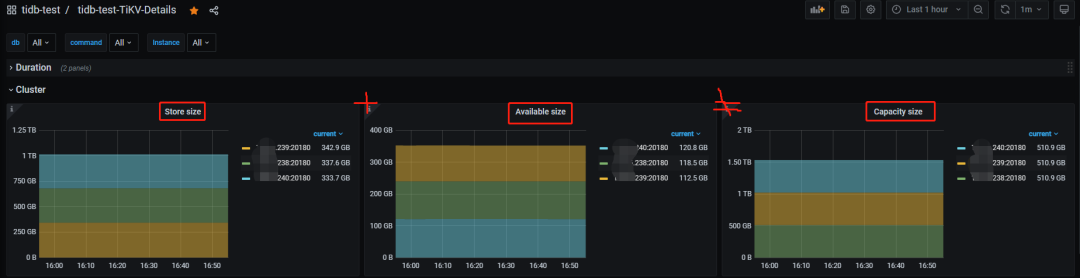
TiKV 实例的已用空间(store size)+ 可用空间(available size) ≠ 总空间(capacity size)
盘越大越明显。
再仔细点看,监控上显示的总容量大小和 TiKV 实例所在盘大小也不匹配。
是不是有“亿点”意外。
结论先行
● PD 监控下的 Storage capacity 和 Current storage size 来自各个 store 的累加,这里 store 包含了 TiKV 和 TiFlash
● Current storage size 包含了多个数据副本(TiKV 和 TiFlash 的所有副本数),非真实数据大小
● TiKV 实例容量统计的是 TiKV 所在磁盘的整体大小与 raftstore.capacity 参数较小的值,同时监控用的 bytes(SI) 标准显示,就是说不是用 1024 做的转换而是 1000,所以和 df -h 输出的盘大小有差距
● TiKV 实例的已用空间只统计了 data-dir 下的部分目录,非整个 data-dir 或整块盘
● 基于前两条,可用空间也就不等于总空间减去已用空间了
看到的现象
● Dashboard 上显示的 TiKV 盘大小(GiB)是实际部署盘的总大小,Grafana 也是部署盘的总大小但单位是 GB
● Grafana 集群总容量是所有存储节点部署盘的累计大小(GB)
● TiKV 实例已用空间大小计算方式未知(要搞清楚只能扒源码了)
不同进制转换带来的影响
这里简单提一下 GB 和 GiB 的区别,帮助大家理解。
○GB 是按 10 进制来转换,也就是说 1GB=1000MB,市面上厂商宣传的大小都是 10 进制,可理解为商业标准
○ GiB 是按 2 进制来转换,也就是说 1GiB=1024MiB,计算机系统只认这个,可理解为事实标准
那么当你买了一台 128G 存储的手机,实际使用中会发现空间“缩水”了,U 盘、硬盘等也类似。与这两个进制差异有关的还有两个行业标准,即 byte(SI) 和 byte(IEC) ,感兴趣的可以去查一下历史,这里只需要知道:
○ byte(SI) 对应十进制
○ byte(IEC) 对应二进制
Grafana 里面可以使用编辑监控面板调整显示单位,例如:
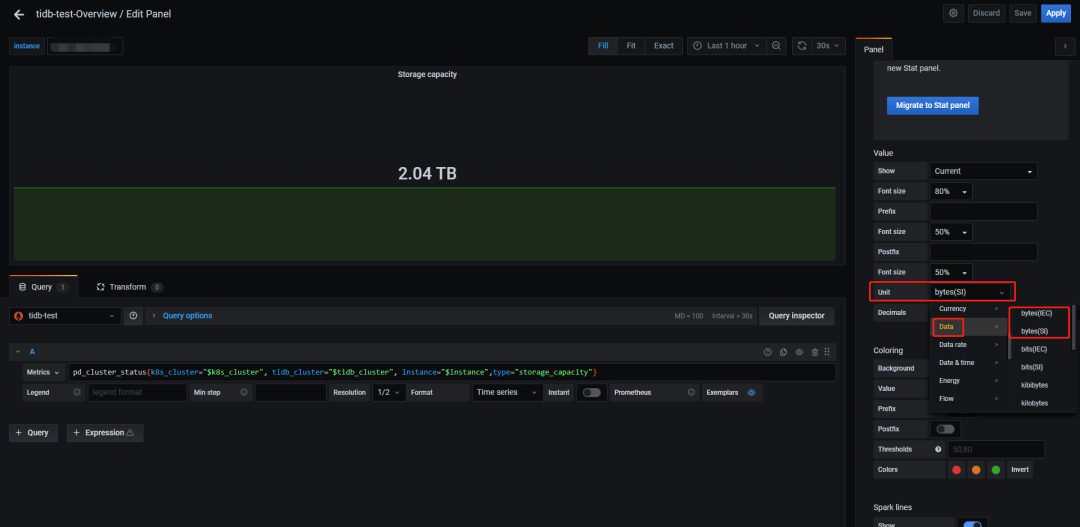
如果把单位统一的话,前 2 个现象就很好解释了。
但需要注意的是,在 Grafana 中并不是所有面板都采用了 byte(SI) ,甚至同一个指标也出现不同面板显示的单位不一样,比如 Overview 下面的 TiDB 分组内存面板使用十进制,System Info 分组内存面板使用二进制,用的时候要小心。
TiKV 的数据文件
● db 目录,这是最终数据的存放目录, db 在源码中写死无法修改
● rocksdb[-xxx-xxx].info 文件,数据 RocksDB 实例的日志文件,已经按日期归档好的可手动删除
● raft-engine 目录,这是 raft 日志存放目录,受参数 raft-engine.dir 控制,没有开启 Raft Engine 特性时名称默认为 raft ,受参数 raftstore.raftdb-path 控制
● raftdb[-xxx-xxx].info 文件,raft 日志 RocksDB 实例的日志文件,已经按日期归档好的可手动删除
● snap 目录,快照数据存放目录
● import 目录,看名字是和导入相关,具体什么作用未知
● space_placeholder_file 文件,预留空间的临时文件(TiKV 磁盘告警救急用,磁盘越大这个文件越大),相关参数 storage.reserve-space
● last_tikv.toml 和 LOCK 文件,看名字猜测就行
Show Me The Code
TiDB 的监控数据分为两类,一类是服务器环境信息(CPU、内存、磁盘、网络等),一类是 TiDB 运行指标(Duration、QPS、Region 数、容量等)。前者通过与 Prometheus 配套的标准探针采集,即 node_exporter 和 black_exporter ,后者通过在源码中类似埋点方式采集数据然后由 Prometheus 来拉取。
点击此处丨查看原文
03
背景
笔者最近在驻场,发现这里的 tidb 集群是真的多,有将近 150 套集群。而且集群少则 6 个节点起步,多则有 200 多个节点。在这么庞大的集群体量下,巡检就变得非常的繁琐了。
那么有没有什么办法能够代替手动巡检,并且能够快速准确的获取到集群相关信息的方法呢?答案是,有但不完全有。其实可以利用 tidb 的 Prometheus 来获取集群相关的各项数据,比如告警就是一个很好的例子。可惜了,告警只是获取了当前数据进行告警判断,而巡检需要使用一段时间的数据来作为判断的依据。而且,告警是已经达到临界值了,巡检却是要排查集群的隐患,提前开始规划,避免出现异常。
认识 PromQL
要使用 Prometheus ,那必须要先了解什么是 PromQL 。
PromQL 查询语言和日常使用的数据库 SQL 查询语言(SELECT * FROM ...)是不同的,PromQL 是一种嵌套的函数式语言,就是我们要把需要查找的数据描述成一组嵌套的表达式,每个表达式都会评估为一个中间值,每个中间值都会被用作它上层表达式中的参数,而查询的最外层表达式表示你可以在表格、图形中看到的最终返回值。比如下面的查询语句:
然后还需要认识一下告警的 PromQL 中,经常出现的一些函数:
● rate
● irate
● histogram_quantile
修改 PromQL
要让巡检使用 PromQL ,就必须要修改告警中的 PromQL。这里需要介绍一个函数:max_over_time(range-vector),它是获取区间向量内每个指标的最大值。其实还有其他这类时间聚合函数,比如 avg_over_time、min_over_time、sum_over_time 等等,但是我们只需要获取到最大值,来提醒 dba 就行了。
Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数:[:] 。
巡检脚本
了解了以上所有知识,我们就可以开始编写巡检脚本了。
这是笔者和同事共同编写的一部分巡检脚本,最重要的是 tasks 中的 PromQL ,在脚本执行之前要写好 PromQL,其他部分可以随意更改。如果一次性巡检天数太多,比如一次巡检一个月的时间,Prometheus 可能会因检查数据太多而报错的,所以使用的时候要注意报错信息,避免漏掉一些巡检项。
总结
一个完善的巡检脚本的编写是一个长期的工作。因为时间有限,笔者只编写了基于 Prometheus 的一部分巡检项,有兴趣的同学可以继续编写更多巡检项。
目前巡检脚本都是基于 Prometheus 的数据来作判断,但是在真实的巡检当中,dba 还会查看一些 Prometheus 没有的数据,比如表的健康度、一段时间内的慢 SQL、热力图、日志信息等等,这些信息在后面一些时间,可能会慢慢入到巡检脚本中。
现在该脚本已在 Gitee 上开源,欢迎大家使用:
https://gitee.com/mystery-cyf/prometheus--for-inspection/tree/master
点击此处丨查看原文
欢迎来到金融专区!
与 PingCAP 一同打造创新的金融数据基础平台,
加速数字化和智能化转型!

