




前文
领导: “现在我们有一个物联网业务场景 ,时序业务场景谁家产品好?”
程序员小明: “当然是时序数据库好,时序业务场景就用时序的相关产品。”
领导:“时序业务场景必须用时序数据库吗?能不能用关系型数据库? 关系型数据库哪里不好?”
程序员小明:“性能的问题,只要是时序业务场景,时序数据库的官方测试比关系型数据库快一百倍。”
领导:“你去跟另外一个项目吧,这个项目不需要你了。”
程序员小明: …
很明显小明的回答不科学严谨, 没有站在实事求是的角度上出发。下面我们帮下小明做下TDengine和openGauss的测试。
TDengines是一个专用型时序数据库,它与通用型的关系型数据库对比如何,与列式数据库对比又如何?
在时序的业务背景下,TDengines是不是一定有优势 ,通用型的打不过专用型,也是默认安装配置的参数打不过后,通过高压缩、并行处理后,是不是能够拉近一些距离,甚至通用型数据库比专用型数据库跑得更快。
测试思路1,公平公正公开,越简单越好
测试思路2,时序做主场,站在时序业务场景, 不用TDengines默认的测试工具。
测试思路3, 对手必须支持列式,选择openGauss,因为openGauss支持中度压缩,高度压缩。
实验环境
| 操作系统 | CPU | 内存 | openGauss | TDengine |
|---|---|---|---|---|
| CentOS Linux release 7.6.1810 | i7-13700H* 8核 | 12G | openGauss 5.1.0单机布署 | TDengine3.2.2.0布署 |
- openGauss和TDengine都部署在一个机器上
- openGauss上面随机生成 1亿条时序数据
- 1亿条时序每条数据具备唯一性,按照0.0001秒生成一条数据
- 将openGauss的数据迁移到TDengines,保障一致性
- openGauss和TDengines默认参数,没有做任何改动变化
- 运行sql程序,并记录执行时间。
测试步骤
- openGauss建行式表,导入1亿条数据,执行查询
- openGauss建列式表,中度压缩,导入1亿条数据,执行查询
- openGauss建列式表,,高度压缩,导入1亿条数据,执行查询
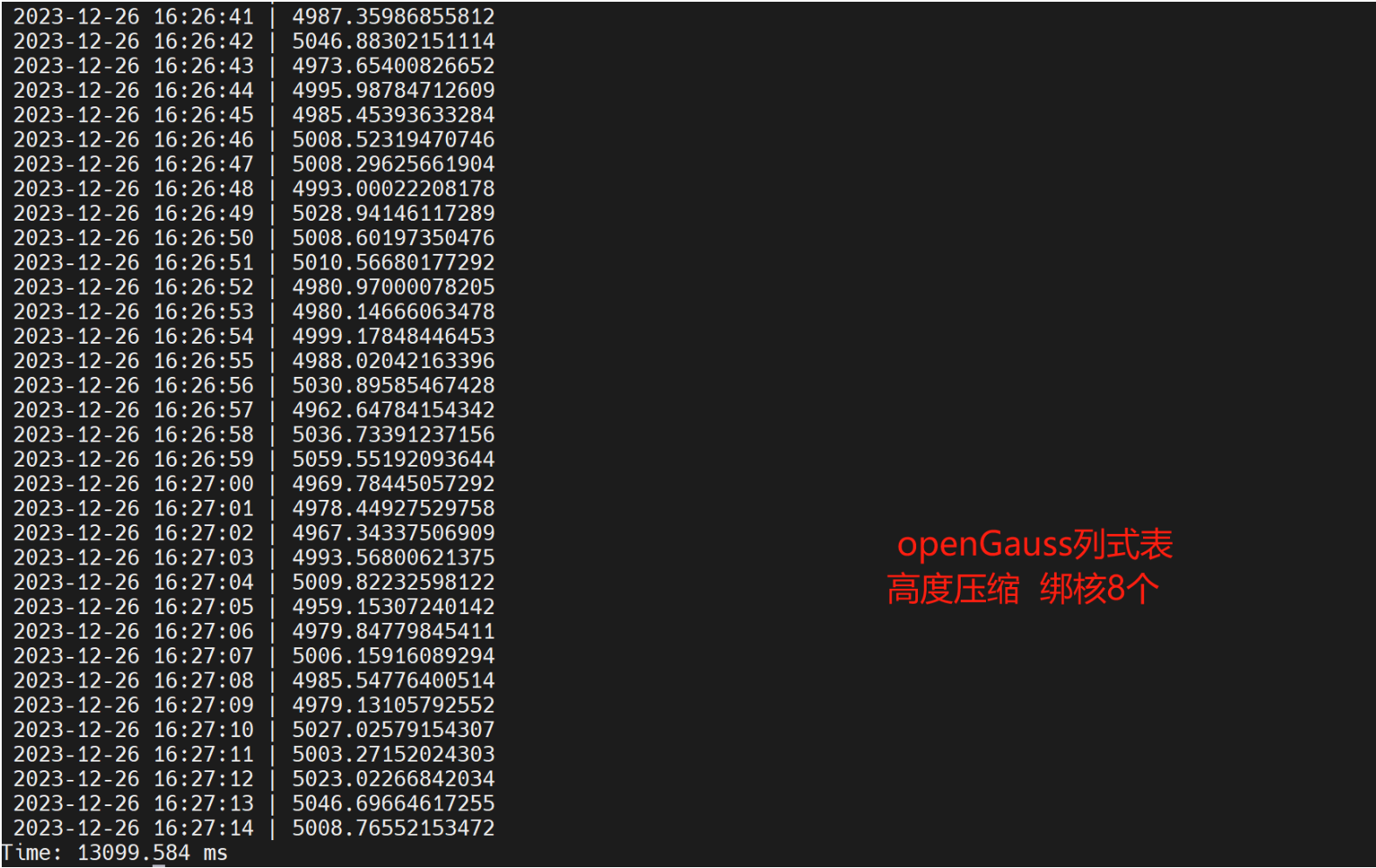
- openGauss建列式表,导入1亿条数据,绑核多CPU,执行查询
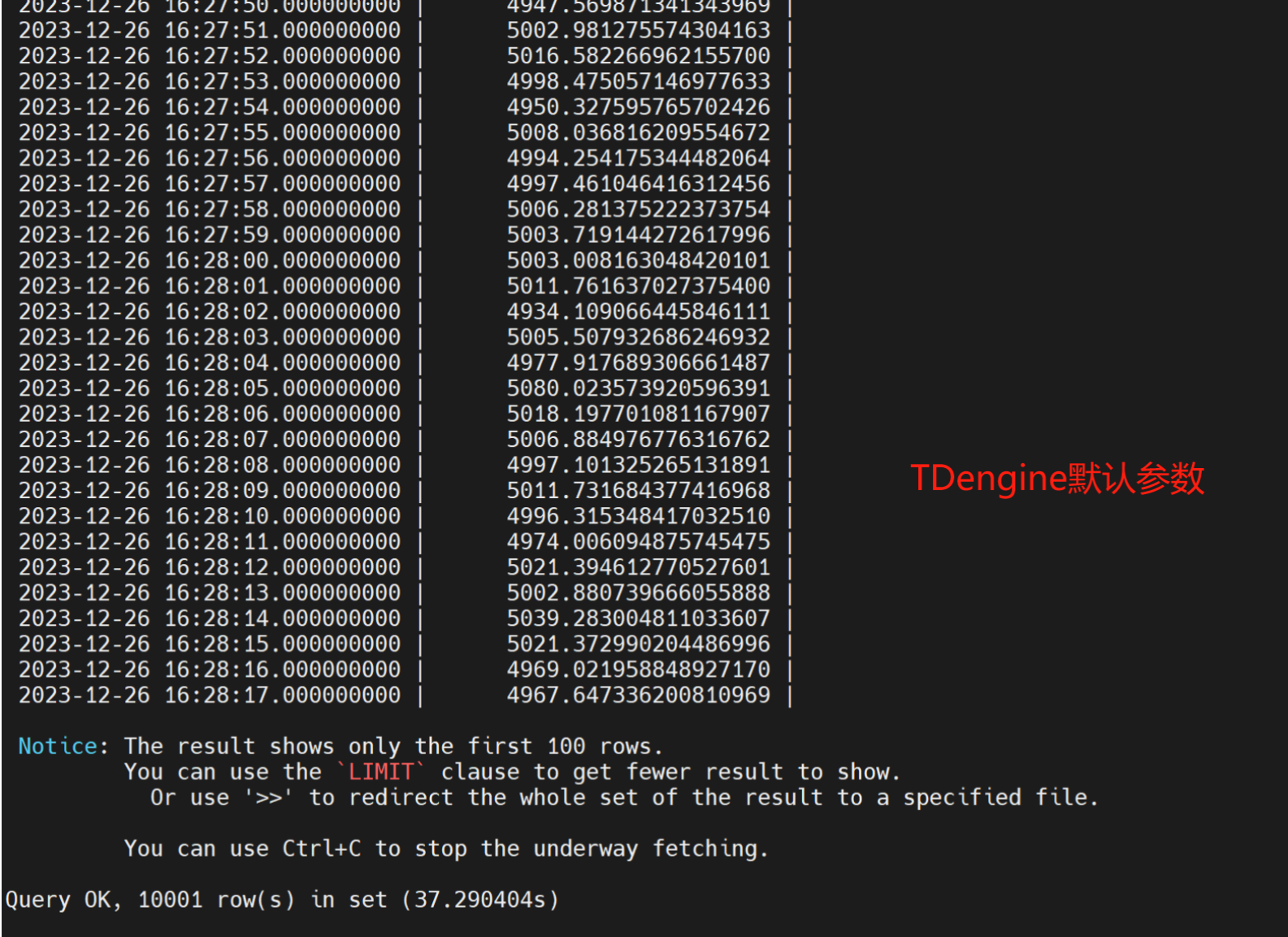
- TDengine常规建表,导入openGauss相同的1亿条数据,执行查询
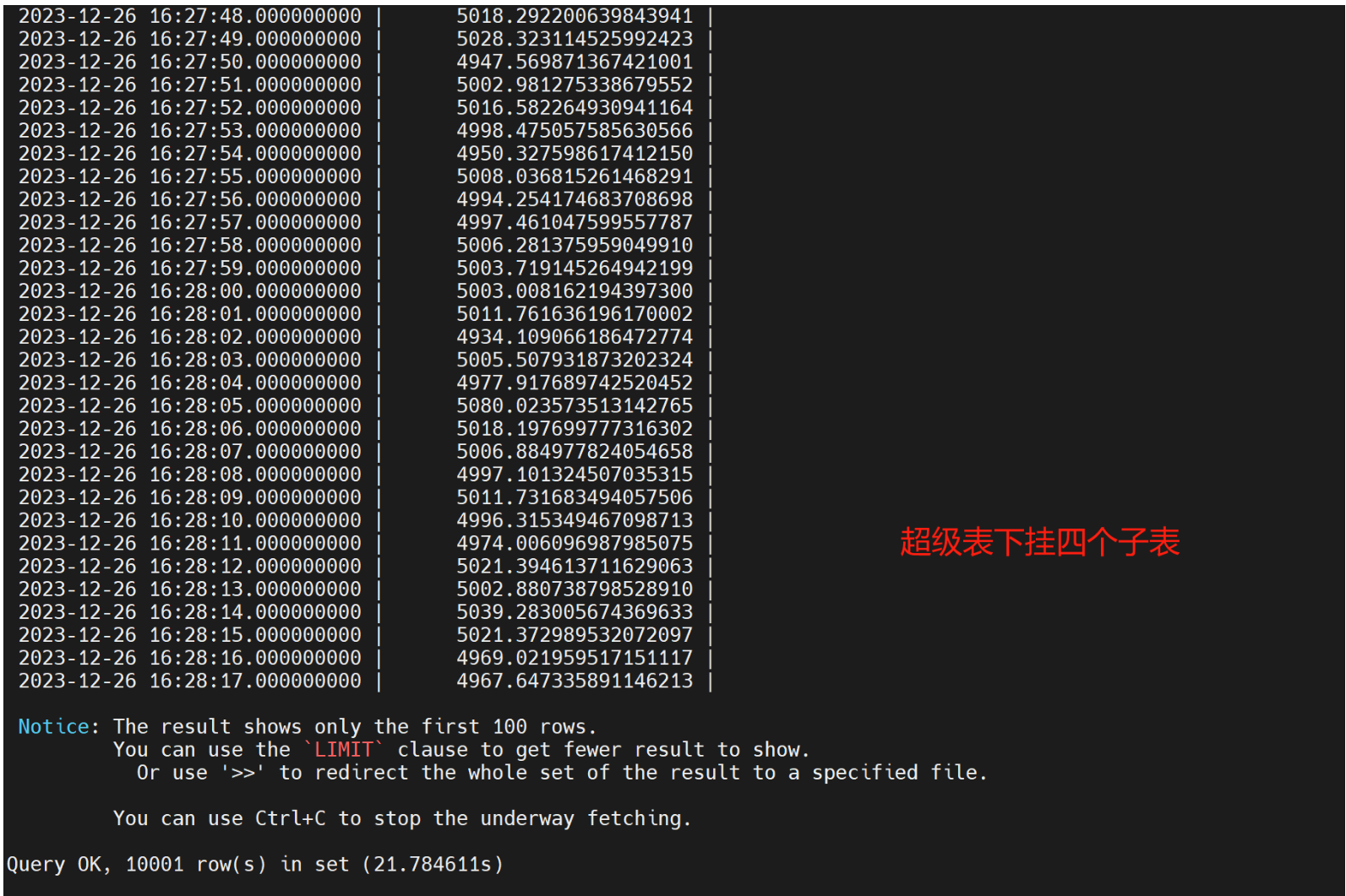
- TDengine运行超级表模式,导入openGauss相同的1亿条数据,执行查询
实验语句
# openGauss建行式表,带主键
create table t3( c1 timestamp, c2 float, primary key(c1) );
# openGauss建列式表,中度压缩
create table t2( c1 timestamp, c2 float) with(orientation = column,COMPRESSION =MIDDLE);
# openGauss建列式表,高度压缩
create table t1( c1 timestamp, c2 float) with(orientation = column,COMPRESSION =HIGH);
# openGauss插入1亿随机数据
insert into t3(c1,c2) select ('2023-12-26 16:26:38.000000'::timestamp) +concat(s.a/10000,'s')::INTERVAL, random() FROM generate_series(1, 100000000) AS s(a);
# openGauss执行语句
select c1::timestamp(0),sum(c2) from t3 group by c1::timestamp(0) order by c1::timestamp(0);
select c1::timestamp(0),sum(c2) from t2 group by c1::timestamp(0) order by c1::timestamp(0);
select c1::timestamp(0),sum(c2) from t1 group by c1::timestamp(0) order by c1::timestamp(0);
# openGauss导出csv数据
\copy (SELECT * FROM t3 order by c1) to '/tmp/tmp_t3.csv' with csv;
# 默认的csv数据不能直接导入Tdengine,需要对时间戳进行处理
sed -i s/^/\"/g $file
sed -i s/,/\",/g $file
# TDengine创建表
create table ttt( c1 timestamp, c2 float );
# TDengine批量导数
insert into ttt file '/tmp/tmp_t3.csv';
# TDengines执行语句
select timetruncate(c1,1s),sum(c2) from ttt group by timetruncate(c1,1s) order by timetruncate(c1,1s);
# TDengines 超级表
CREATE TABLE cbd (c1 timestamp, c2 double) TAGS(location binary(20), type int) ;
CREATE TABLE cbd1 USING cbd TAGS ('gz1', 1);
CREATE TABLE cbd2 USING cbd TAGS ('gz2', 2);
CREATE TABLE cbd3 USING cbd TAGS ('bj1', 3);
CREATE TABLE cbd4 USING cbd TAGS ('bj2', 4);
CREATE TABLE cbd5 USING cbd TAGS ('sh1', 5);
CREATE TABLE cbd6 USING cbd TAGS ('sh2', 6);
CREATE TABLE cbd7 USING cbd TAGS ('sz1', 7);
CREATE TABLE cbd8 USING cbd TAGS ('sz', 8);
#把openGauss导出的大文件拆成8个小文件
split -l 行数 largefile.txt
#依次把8个小文件导入到TDengine的子表上面
insert into cbd1 file '/tmp/cbdaa' ;
insert into cbd2 file '/tmp/cbdab' ;
insert into cbd3 file '/tmp/cbdac' ;
insert into cbd4 file '/tmp/cbdad' ;
insert into cbd5 file '/tmp/cbdae' ;
insert into cbd6 file '/tmp/cbdaf' ;
insert into cbd7 file '/tmp/cbdag' ;
insert into cbd8 file '/tmp/cbdah' ;
#执行查询
select timetruncate(c1,1s),sum(c2) from cbd group by timetruncate(c1,1s) order by timetruncate(c1,1s);
测试截图
总结及思考
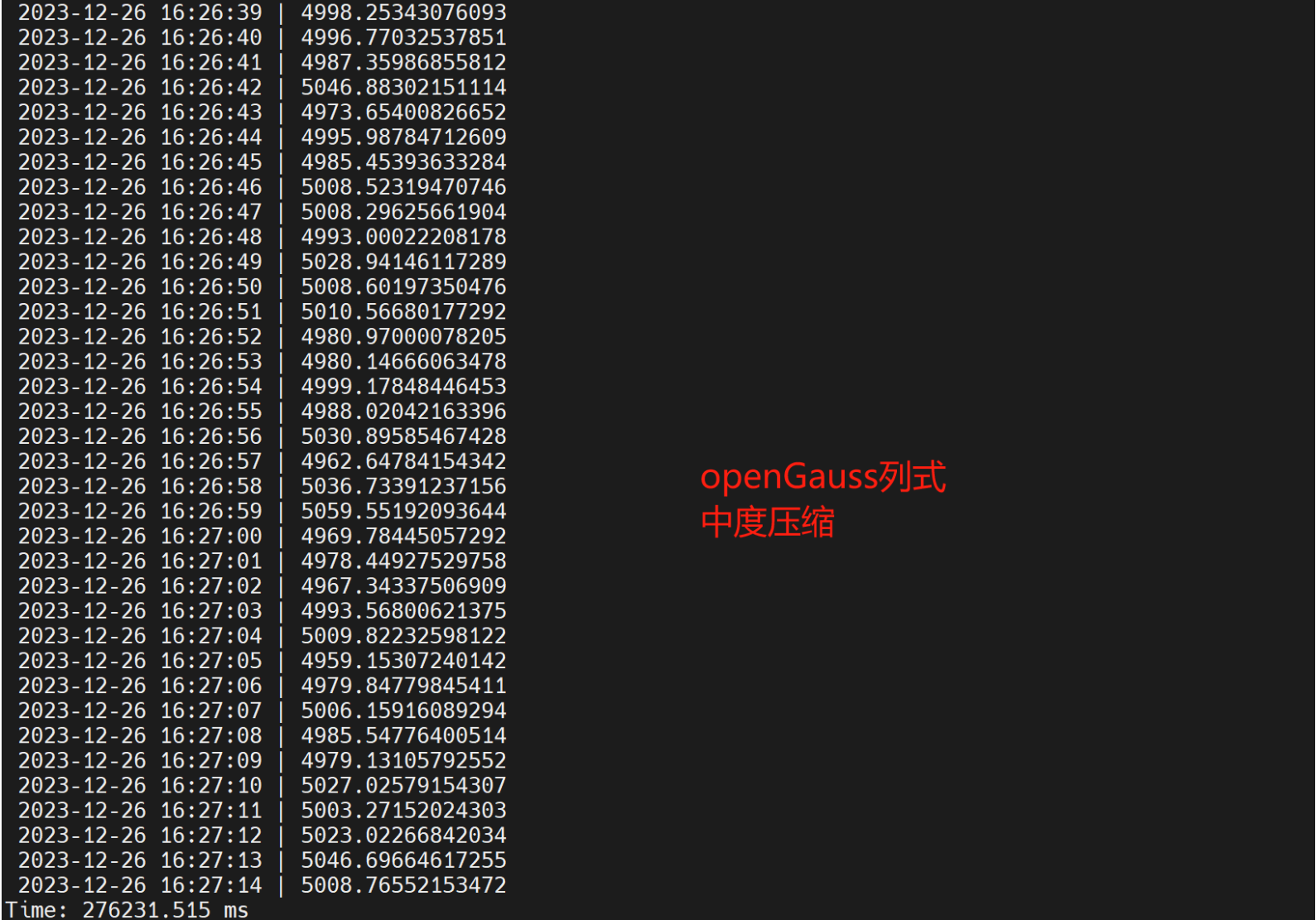
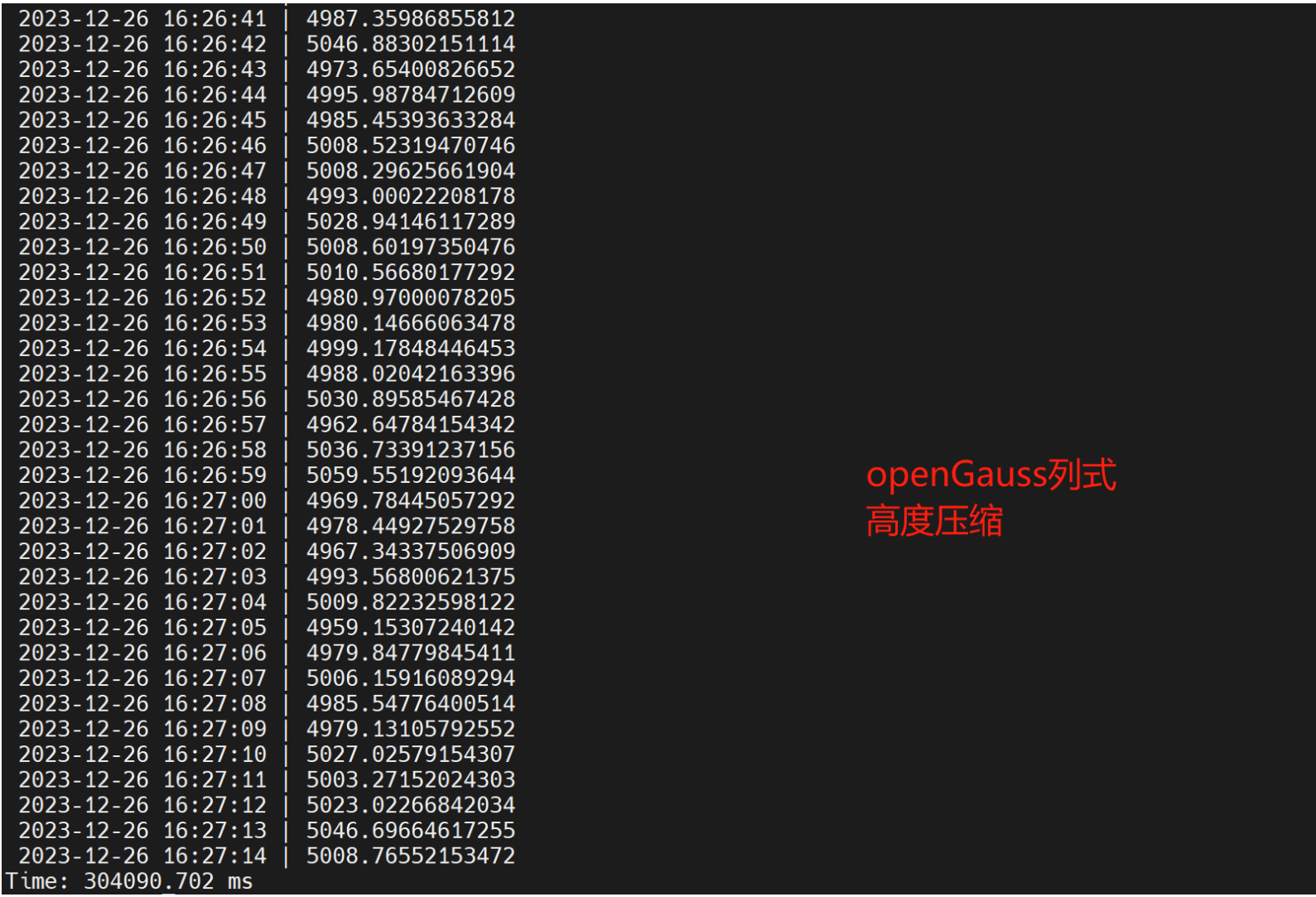
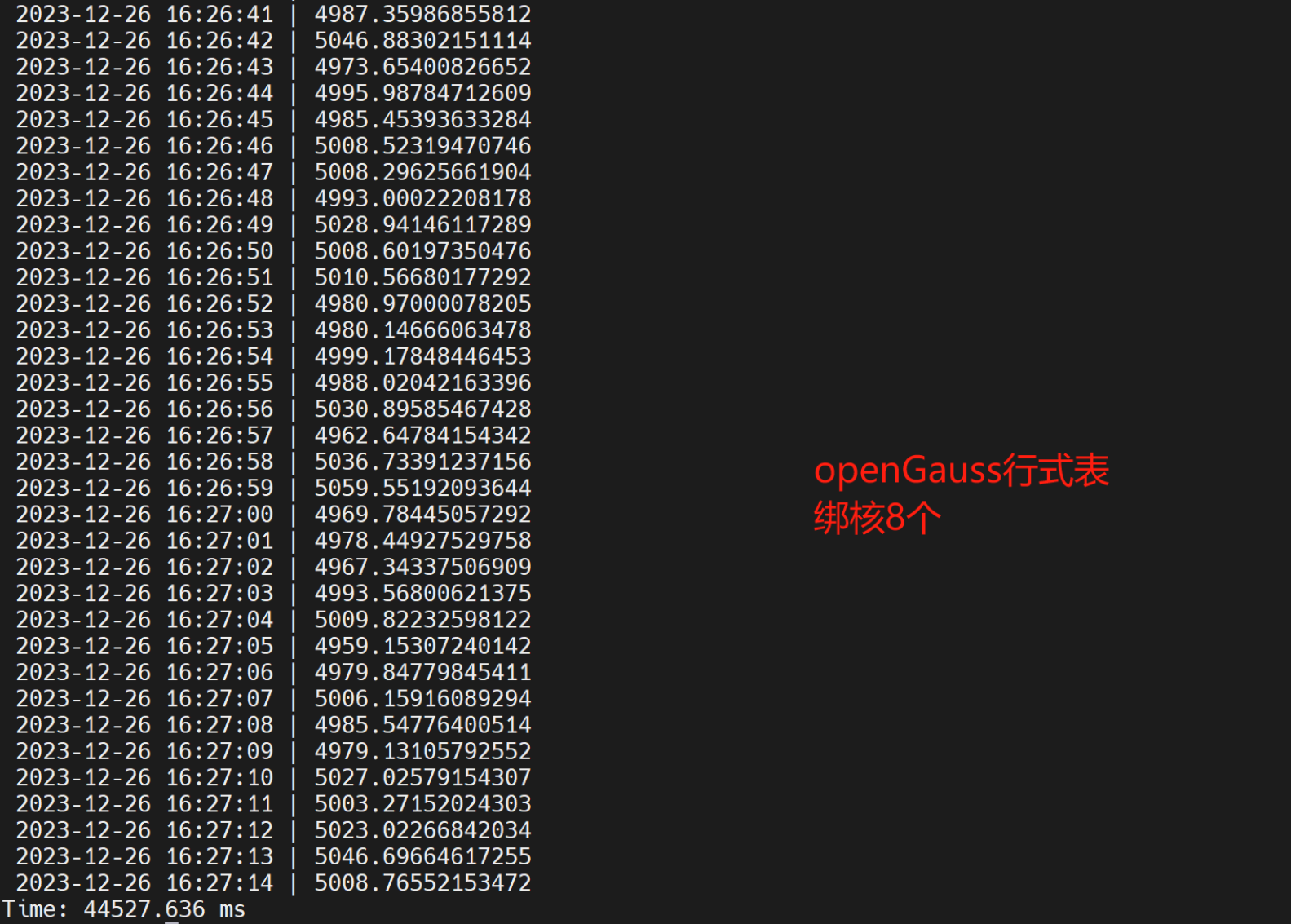
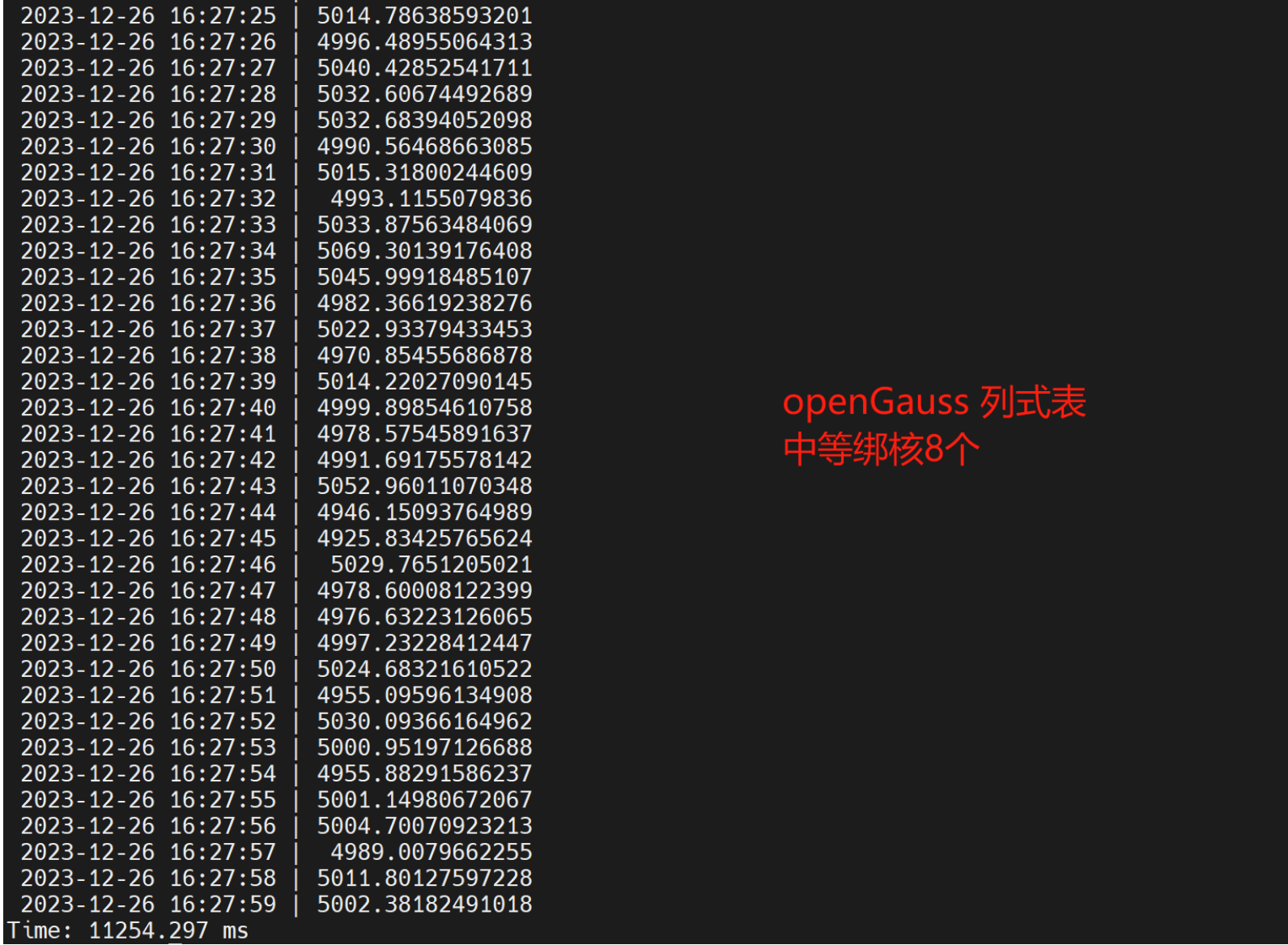
- 1亿条数据,openGauss列式中度压缩扫行时间 为276231.515ms,openGauss列式高度压缩执行时间 304090.70sms,openGauss行式表绑核8个并行 44527.636ms, openGauss列式中度压缩绑核8 个执行时间 为11254.297ms。同样数据TDengine执行时间为37.290404s,通过超级表模式执行时间21.784611s。openGauss开外挂后,跑得比TDengine快。
- 执行过程中查看系统资源消耗, openGauss对CPU、内存、硬盘消耗较多,反而TDengine占用的CPU、内存、硬盘较少。openGauss跑得比TDengine快,牺牲硬件资源的前提条件上的。
- 因为1亿数据都是前后有序的原因,TDengine导入数据的速度惊人,几乎是100万级每秒的速度。TDengine默认是以时间戳作为主键索引的,每个主键有且只有一行数据,如果时间戳相同,最新的数据会进行覆盖。
- openGauss目前支持的索引有限,仅有行式和列式。。, postgresql 的brin索引是针对时序而开发的索引结构,以后openGauss有望加入这方面的支持。如果业务上类似这样的数据量和业务数据,而且信息系统本身用的就是openGauss ,可以考虑用openGauss。
最后修改时间:2024-02-05 10:26:29
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
