




GaussDB家族还是挺复杂的,最近我们也正在抓紧开发D-SMART GaussDB专版。在这个专版中要对GaussDB数据库、openGauss数据库以及生态中的各种高斯内核的数据库提供支持。想做好这一点首先得仔细的了解一下GaussDB家族的成员都有谁。实际上GaussDB的所有成员,不管是华为的GaussDB,开源的openGauss,还是基于openGauss内核的其他国产商用数据库,其都有一个通用的核心-“高斯数据库核心”。
正是因为共用一个核心,在数据库的特性上存在大量的共性,运维工具方面就可以有大量的想通的东西,比如指标体系、等待事件、主备库同步等。
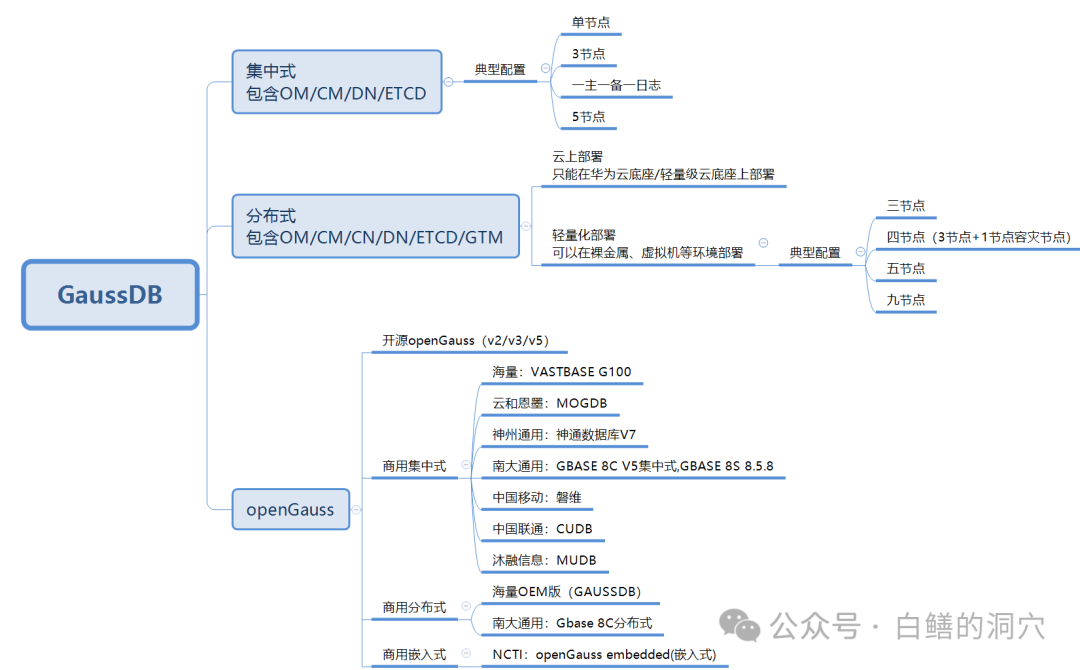
从上面的图可以看出,GaussDB家族还是挺庞大的。华为的GaussDB商用版分为集中式和分布式两种部署模式,这两种部署模式还分云上部署版本和独立部署版本。华为云的用户可以直接使用云上版本,直接在云管平台中订阅就可以了。云下部署的版本可以通过华为的管理工具TPOPS来实现部署。
从个人感受上来说,有了TPOPS工具之后,GaussDB的安装部署便捷了很多。早期我们也尝试过在云下部署GaussDB,那个感觉还是挺酸爽的,在华为工程师的远程指导下,花了几天时间才完成部署。
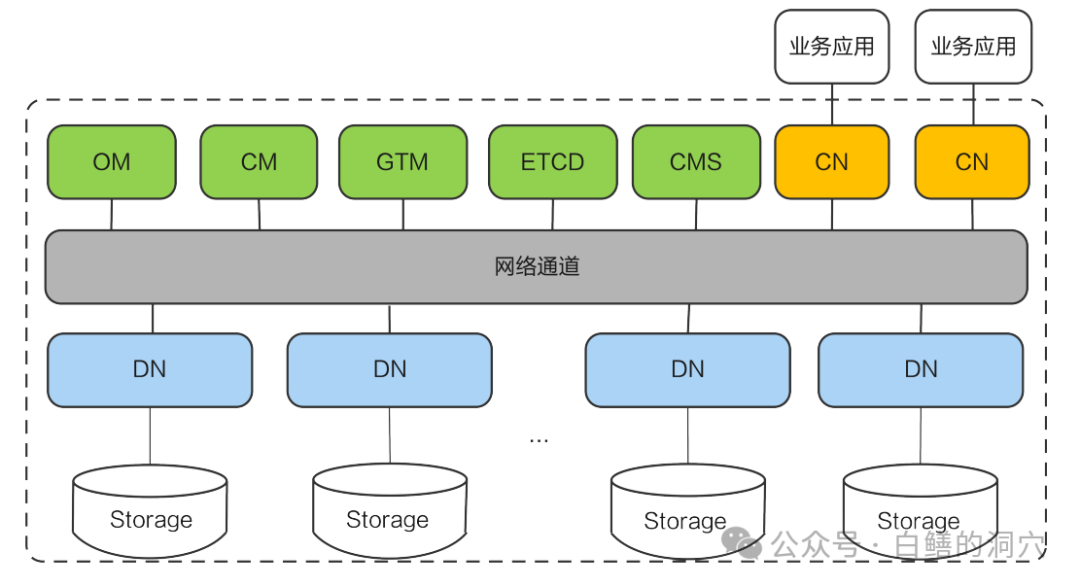
GaussDB分布式可能大家比较了解,最初GaussDB主推的模式是分布式,主要针对一些大型的系统。上图是在云下轻量化部署的GaussDB分布式的典型架构。应用连接CN,数据存储于DN,GTM做全局分布式事务管理,CM负责集群管理,ETCD存储集群的一些基础配置。不过分布式数据库对于应用研发是有一定门槛的,对于一些不需要分布式数据库的场景,完全可以使用更为简化的解决方案。
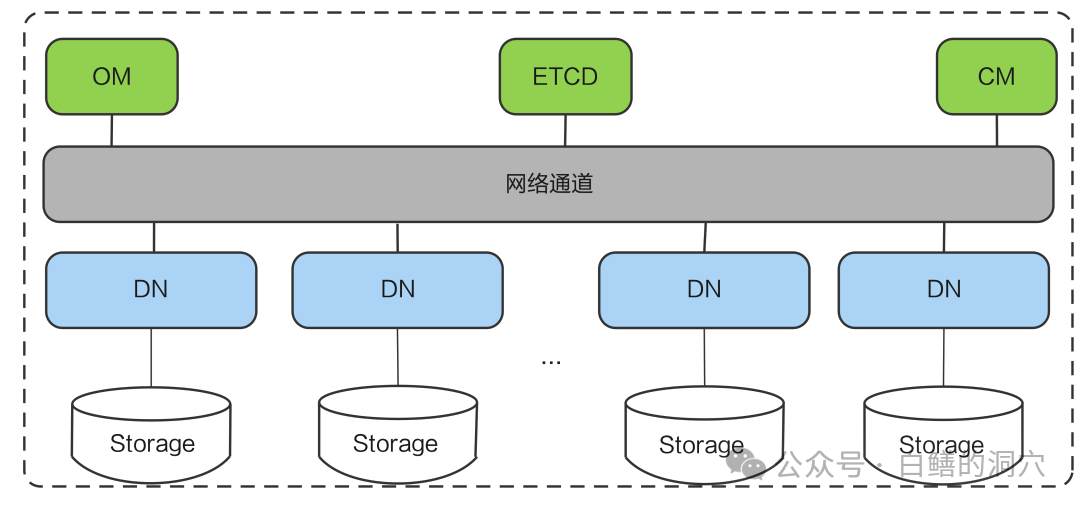
在目前GaussDB的版本中(比如目前最常用的2.23.01.200_503),GaussDB支持十分丰富的集中式数据库模式:3节点、5节点、一主一备一日志、单节点。在集中式模式下,GTM和CN都不需要了,应用直接连接DN访问数据库。多个DN组成一个GaussDB集中式集群,通过组复制(Paxos或者Quorum)实现高可用和故障自动切换。
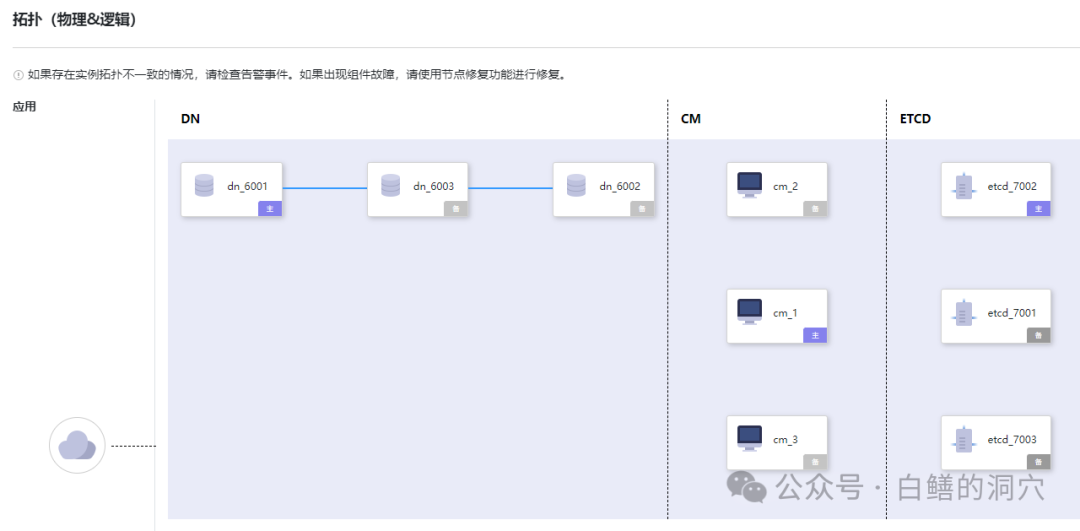
上图是最为典型的是3节点,可以通过Paxos协议组成高可用组,实现组内的自动故障切换。一个集中式的GaussDB数据库不需要CN/GTM节点,不过CM/ETCD仍然是需要的。三个DN节点代表了数据库一主二从三个副本,早期的GaussDB版本中,只能对主节点做读写操作。新版本已经提供了读写分离的模式,可以在应用层实现弱读的自动分发。而对于一些跟高可用性要求的环境,GaussDB还提供了5节点的集中式模式。
对于同城双中心容灾的场景,可以采用一主一备一日志部署模式,这种部署模式需要两个主数据中心和一个次要数据中心。其中两个主要中心分别部署主备节点,第三中心可以是次要中心,只保存REDO,不需要有数据文件,从而简化系统,节约存储资源。
最后是单副本模式,对于一些不太重要的系统,可以部署GaussDB集中式的单副本单节点,然后通过数据库备份来增强数据安全。
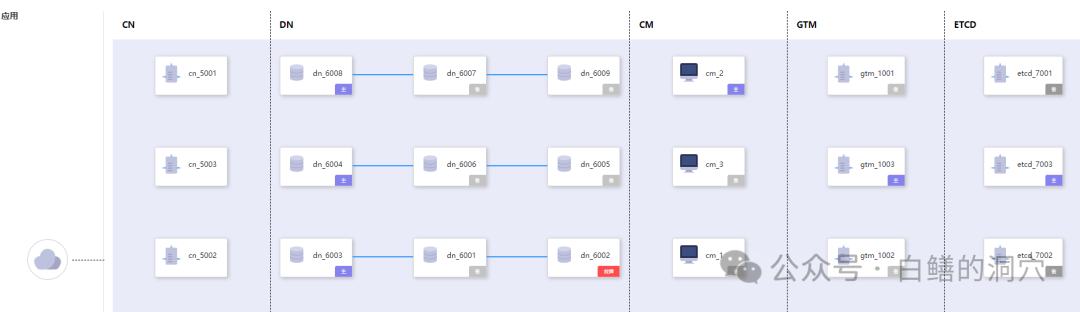
GaussDB分布式版本的轻量级部署分为计算节点CN,存储节点DN,全局事务管理GTM,集群管理CM,以及存储集群配置信息的ETCD组成。每个CN都是无状态的,可以承担计算任务,而DN都是按组的,每个DN都有多个副本。
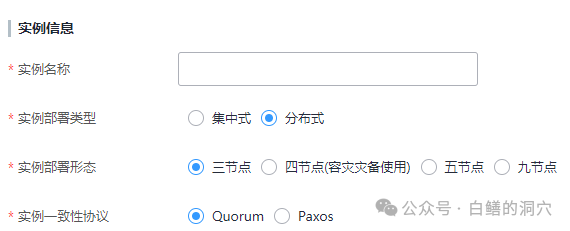
在TPOPS中的自动化部署,集群形态选项不多,只有四种。最为简单的是三节点,三节点的CN/DN/GTM配置为3:9:3,采用的分片数量为3,副本数量也是3。另外也可以增加一个容灾节点,变形为四节点。另外可以选择五节点或者九节点。不知道为什么跳过了七节点这种部署形态,难道7节点不配做分布式数据库吗?从下面的GaussDB分布式副本的特殊设计,我们可以看出其原因。
"encoding": "utf8",
"shardingNum": 4,
"replicaNum": 4,
"solution": "hws",
从五节点部署形态中我们看到使用的是4:16:4的配比模式,四个分片,4副本的模式。这种模式和我们的常规认知有些差别。五节点部署采用3 AZ,4副本的模式,所有副本均匀分布于AZ1/AZ2中,AZ3是一个用于仲裁的AZ,并不包含数据节点和计算节点。这个算法扩大到九节点,那么副本依然使用4副本,分片可以是8个或者4个。而七节点就比较尴尬了,如果使用4副本,在某些情况下副本无法实现均衡分配在6个节点上。
当然,上面这些都是工程化的典型配置,实际上GaussDB支持其他类型的部署模式,只是TPOPS的开发者偷了个懒,没有提供自定义部署模式供用户选择而已。从TPOPS的这个设计可以看出,GaussDB这种存算分离的分布式数据库,在CN/DN/GTM的配比,以及副本的设计方面都是十分复杂的,没有经验的使用者很可能因为不合理的部署架构而导致数据库存在不均衡的隐患,一旦数据量大了,就容易出现一些性能不稳定,负载不均衡的问题。
目前GaussDB还不支持严格意义上的多租户,因此集群规模也不建议搞得太大,否则会造成资源浪费。实际上在目前GaussDB的用户中,使用三节点集中式模式的比例可能是最高的,至少我所知道的用户那边,主要使用集中式模式。
GaussDB的生态很庞大,因为其同源核心的openGauss是开源的 ,基于openGauss核心有大量的商用数据库厂商。比较著名的有海量、神通、云和恩墨以及南大通用。南大通用虽然加入openGauss生态圈最晚,不过其产品最类似于GaussDB,提供集中式和分布式两种部署模式。海量则通过OEM了GaussDB分布式版本,也拥有了集中式和分布式两种形态的数据库。今天时间关系,对于openGauss生态的数据库产品我就不细说了,大家有兴趣的话可以根据我提供的第一张图去一一了解。
