




赛题名称:校招简历项目技能匹配检测 赛题类型:自然语言处理
https://challenge.xfyun.cn/topic/info?type=skill-matching
赛事背景
讯飞高教人才培养业务线围绕新一代信息技术,与全国几十所高等院校开展深度合作,为了院校学生能更好地精准实习就业,学生的实习就业简历作为桥梁,就离不开老师们的精心指导,而指导耗时耗力,那如何降低人工指导的耗时,提高简历指导的效率成了老师们的迫切需求。简历指导如何智能化,学生如何精准实习就业,如何智能化判断简历应聘岗位与项目技能匹配度,成了亟待解决的问题。
赛事任务
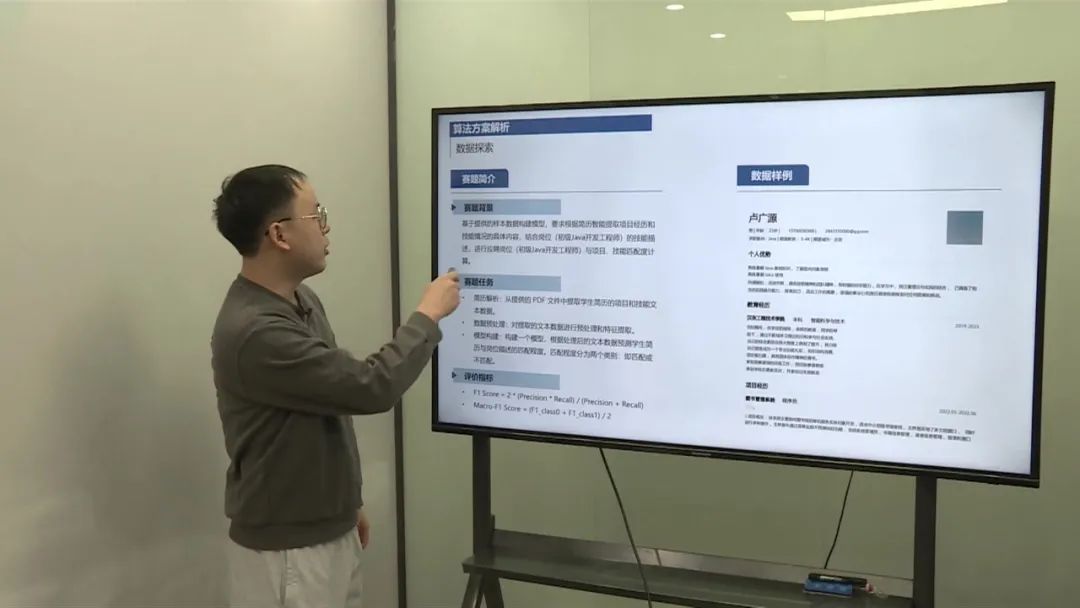
智能化判断简历应聘岗位与项目技能匹配度,需要明确岗位的技能描述,本赛题以初级Java开发工程师为目标岗位,提供脱敏后的学生中文简历数据集(pdf或docx格式)作为训练样本,学生简历均以初级Java开发工程师为应聘岗位,参赛选手需要基于提供的样本数据构建模型,要求根据简历智能提取项目经历和技能情况的具体内容,结合岗位(初级Java开发工程师)的技能描述,进行应聘岗位(初级Java开发工程师)与项目、技能匹配度计算。
主要任务如下:
简历解析:从提供的 PDF 文件中提取学生简历的项目和技能文本数据。 数据预处理:对提取的文本数据进行预处理和特征提取。 构建一个模型,根据处理后的文本数据预测学生简历与岗位描述的匹配程度。匹配程度分为两个离散的类别:即匹配或不匹配。
Java 初级软件开发工程师岗位任职技能描述如下:
JAVA基础扎实,理解JVM原理,有多线程、高并发系统开发经验者优先。 熟练掌握J2EE技术,熟悉Java Web开发常用开源框架(如 Spring、SpringMVC、SpringBoot、Mybatis)、类库以及组件(如 Redis,ActiveMQ,Zookeeper),能独立完成功能模块开发。 熟练使用Oracle、MySQL等至少一种大型关系数据库,熟练掌握SQL语句、存储过程,能对数据库进行操作,具有一定的数据库开发和使用经验。 熟悉HTML、CSS、Javascript、AJAX等Web前端技术。 熟悉Linux服务器相关操作,能独立部署应用服务;熟悉Tomcat/Nginx等服务器配置及使用。 熟悉Spring Cloud/Kubernates/Docker等技术优先;熟悉Vue/Angular/React等任一种前端框架优先。
数据说明
本次比赛为参赛选手提供的数据如下:脱敏后的学生简历数据集(pdf或docx格式)和Java软件开发工程师的岗位技能描述(txt格式)。为了保护学生隐私,本次训练数据提供脱敏后的数据集,共500份。
测试集对参赛选手不可见,由真实简历数据组成,共100余份。为了减轻选手对不同类型的文档的预处理工作,训练集全部为pdf格式。
评估指标
由于测试集采用真实数据,同时为了避免作弊,要求选手提交代码文件(含测试文件),能够在测试集上进行测试(测试输出结果保存为CSV文件,见模板)。本模型依据提交的结果文件,采用macro-F1 score进行评价。
优胜方案
第一名






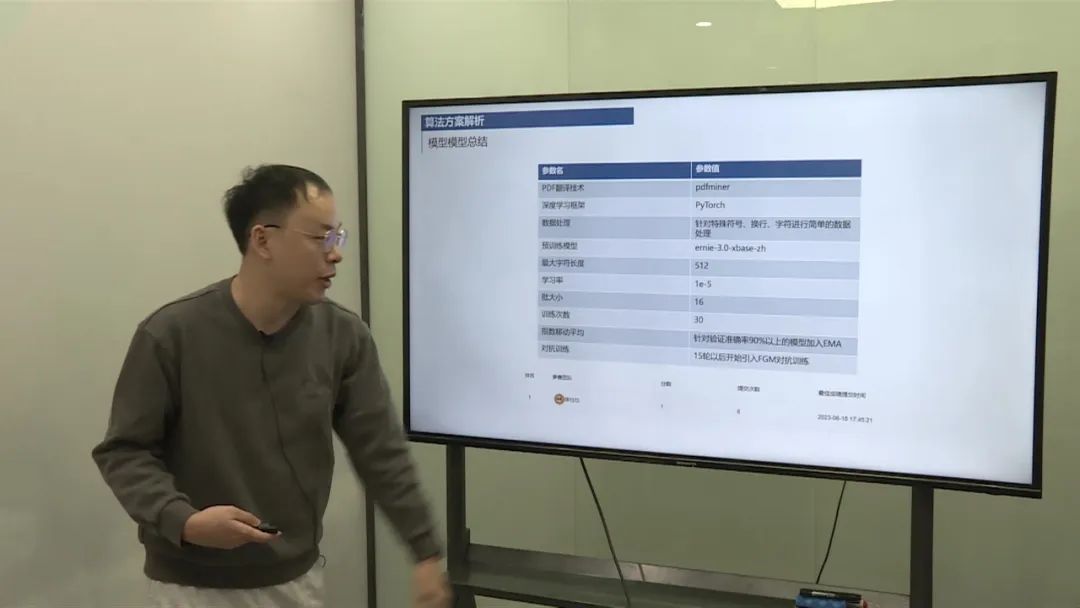


PDF解析: 使用开源工具PDFMiner对PDF文档进行解析,转换为自然语言文本。 数据存在一定的质量问题,因此进行了简单的噪音去除和换行处理。 数据预处理: 对解析后的文本进行质量问题处理,包括符号去除和换行压缩。 针对技能部分进行提取,压缩数据以适应模型输入限制。 模型构建: 初版采用了记忆学习方式,利用TF-IDF等简单特征进行匹配判断,但分数不高,因此没有提交。 第二版采用了预训练模型(如BERT),并尝试了不同的配置和模型大小进行训练和调优,最终选择了Early模型。 硬件资源消耗: 使用了10代CPU进行数据处理和模型训练。 采用了T4和A100等GPU卡进行模型训练,对于较大模型,使用了A100进行训练,但实际测试发现显存消耗并不大,建议使用3090或V100也可满足需求。
流程和操作过程
PDF解析: 使用PDFMiner工具对PDF文档进行解析,转换为文本数据。 数据预处理: 对文本数据进行质量处理,去除噪音和不必要的符号。 压缩换行,统一格式。 模型构建: 初版采用了简单的特征和判断方式,但效果不佳。 第二版采用了预训练模型,如BERT,进行模型训练和调优。 尝试不同的模型配置和大小,选择适合的模型版本。 硬件资源消耗: 使用CPU和GPU进行数据处理和模型训练。 根据模型大小和需求选择合适的GPU卡进行训练,确保资源利用最优化。
第二名


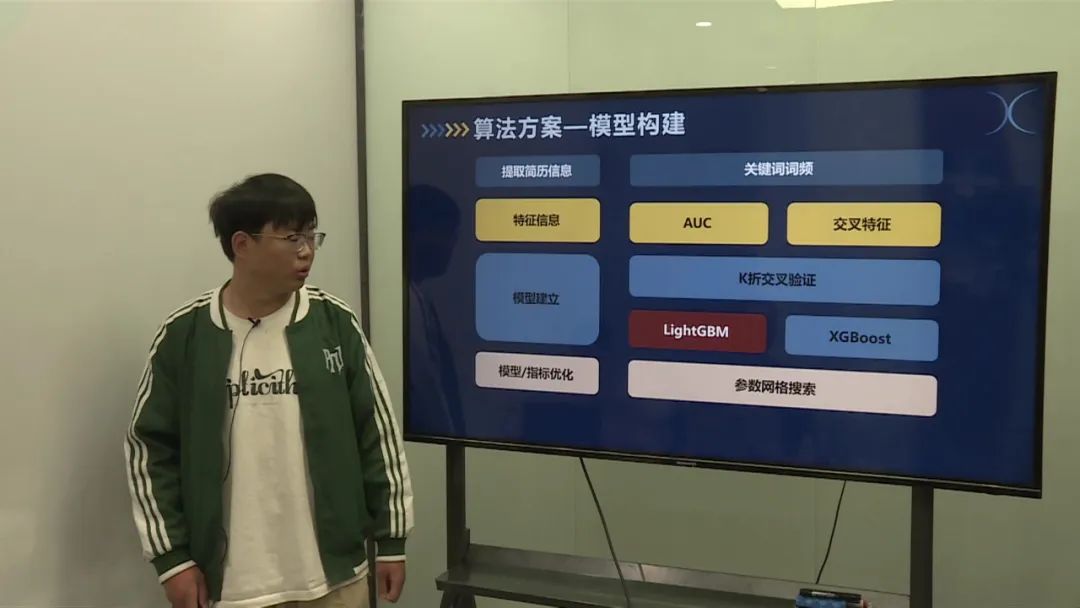




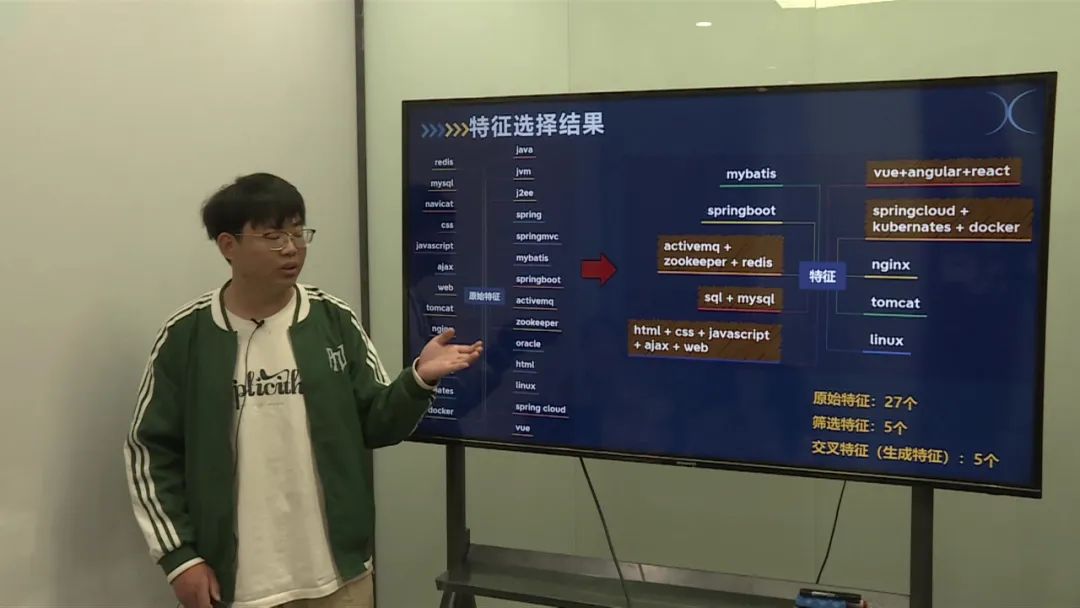

人工指导减力效率低,需要智能化判断减力应聘岗位与项目匹配度。 主要任务包括简历解析、数据处理和模型构建。
简历解析
使用Python中的PDFI库将PDF文件转换为文本字符串。 通过对文本的分析和提取关键词,识别应聘者的技能和项目经历等信息。
数据处理
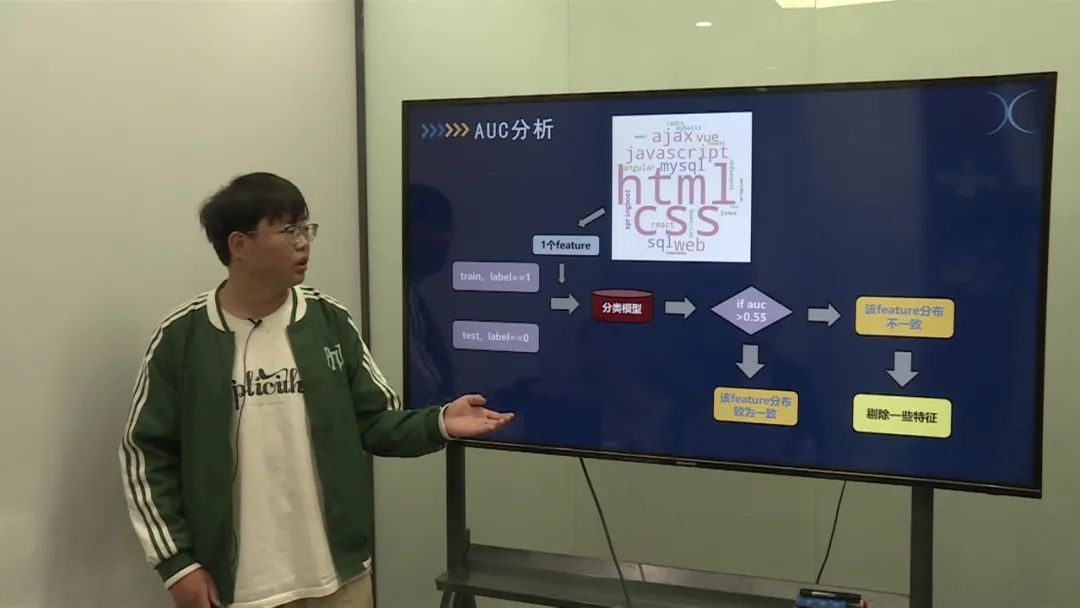
对提取的特征进行AUC分析和交叉特征处理,筛选出具有较高相关性的特征。 剔除不相关的特征,构建训练集和验证集。
模型构建
采用K折交叉验证,选择了两种模型:LightGBM和XGBoost。 通过参数网格搜索,优化模型参数,选择最佳模型。
模型优势和特点
特征工程采用关键词持平方式,将文本转化为向量,提高模型准确性。 LightGBM能够有效处理异常值和提高模型泛化能力,运行速度快。 未来展望包括利用深度学习网络模型进一步提升模型性能,增加样本量丰富特征表达,将分类问题转化为回归问题等。
第三名



问题考虑:
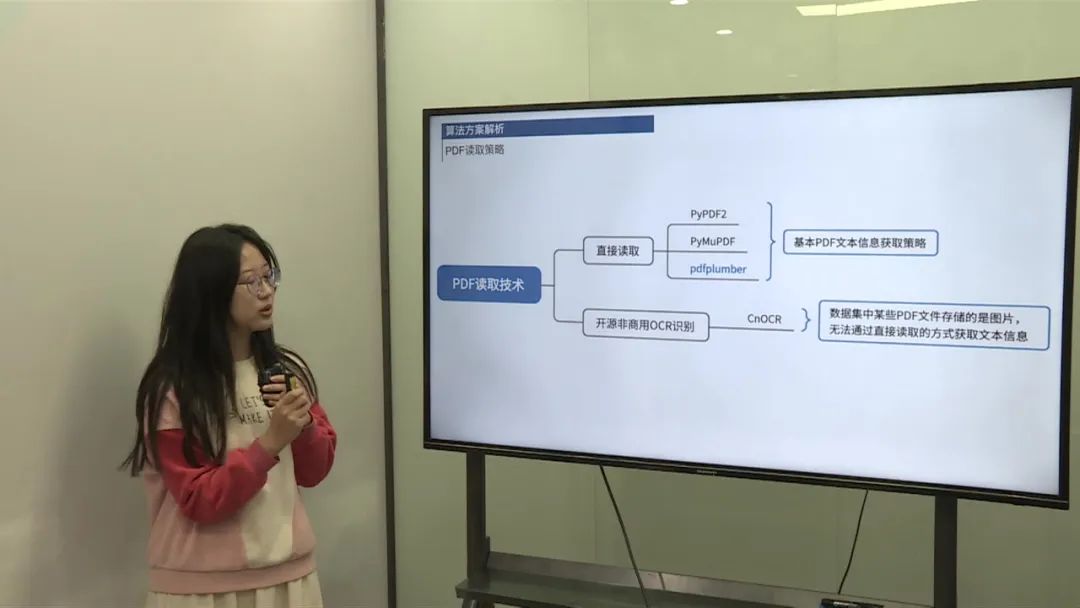
非文本PDF的文本信息提取。 不同结构简历的语序保持问题。 解决方案:
考虑了直接读取和开源OCR识别两种方案。 由于部分PDF存储为图片而非文本,加入OCR识别进行补充。
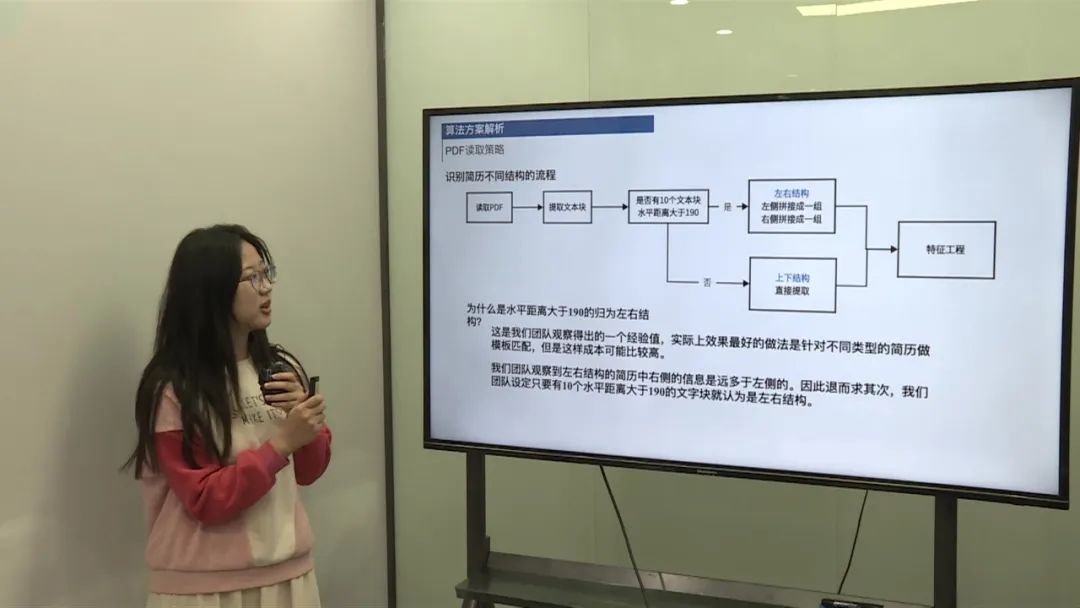
简历结构识别流程
读取PDF,提取文本块。 判断是否为左右结构简历:水平距离大于190的文本块数量是否超过10个。 如果是左右结构,将左侧文本和右侧文本分别拼接。 如果是上下结构,直接提取文本。
特征工程
技术特征:
提取赛题职位描述中的关键词,划分为九个类别。 文本匹配统计每个类别出现的次数作为技术特征。 编程语言特征:
整理常用编程语言列表,计算求职者使用的编程语言数量作为特征。 候选岗位特征:
划分Java相关和非Java相关岗位,进行岗位匹配筛选简历。 模型选择:
尝试了LightGBM和CatBoost,最终选择LightGBM版本提交。
算法性能和资源消耗:
使用默认参数进行模型训练,成本低,耗时较少。 未尝试预训练模型等更复杂的模型,未进行参数调优。


