




还是老规矩,申明一下这篇文章其实没啥技术含量,最后定位的原因也非常简单。只是过程当中产生了很多的曲折,弄得我较为狼狈。
事情开始是这样的,前端开发同事跑来求助,说他们一个生产的分页查询SQL语句要跑1分多钟,让看看怎么回事。我首先通过ASH抓取到了那个SQL,然后调取它的执行计划看看,发现其中一个16G的大表走了全扫,但是该SQL在SQLPLUS里面执行的时候,就直接秒杀了。
看到这里,他们自己瞬间也明白了怎么回事,那肯定是入参的类型和表字段类型不一致,导致无法走正确的索引了。实际上看到本文标题的大佬们,首先想到的也是这种最大的可能了。
这个SQL是通过XML文件进行封装,最后通过JAVA程序进行调用的,而入参在SQL代码中是以绑定变量的形式存在,一开始是这样的:
and (t2.t_fnh_tm between ? and ? and ...)
没错,就是一个简单的问号,我不是很懂XML和JS的结合,也没仔细问他们这个地方一开始是怎么封装的,总之就是这种原始的入参形式,传递进去的值是一个timestamp类型或者字符串类型,而字段t2.t_fnh_tm却是一个date类型,那么话就不多说了。然后他们就把封装的SQL内容改为了如下格式:
and (t2.t_fnh_tm between to_Date(#{TStartTm}, 'yyyy-mm-dd') and
to_Date(#{TEndTm}, 'yyyy-mm-dd') and ...)
然后就顺利的跑起来了,速度也可以程序秒杀了。原以为事情就这么结束了,哪儿知道第二天他们又来反馈说,这个情况又出现了,SQL还是需要跑1分多钟,于是我再次调取了SQL的执行计划,发现了个很明显的性能点:
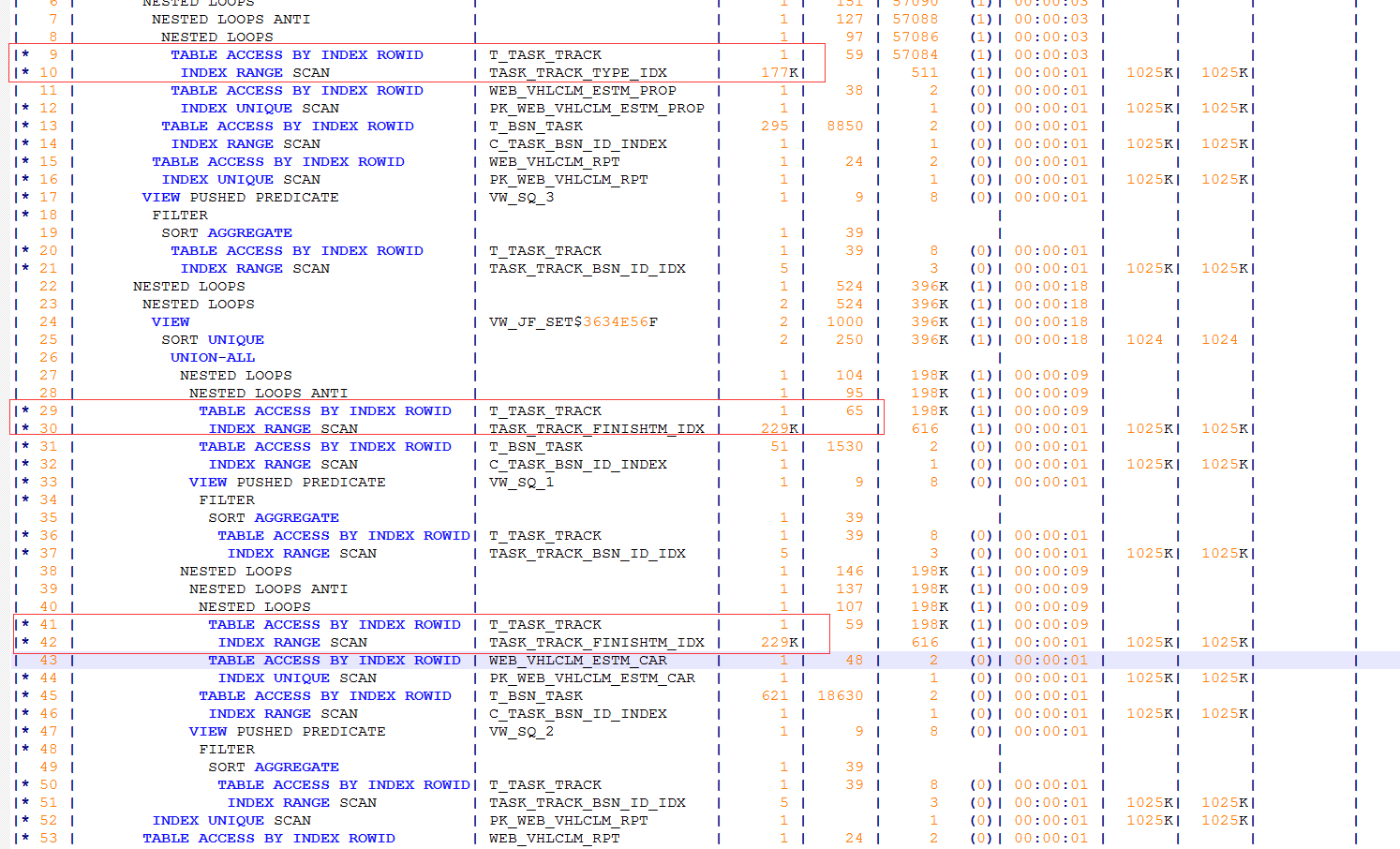
没错,就是大量的回表导致的。采用实际的执行计划跟踪也发现这个三个地方都需要回个二十万次的表,一共有三个地方,加起来就是近70多万次的回表,这些都是很容易解决的地方。
这个SQL的代码我就不贴了,总之就是一个三个SELECT语句做UNION的操作。而且这三个SELECT的地方,都是同一张表T_TASK_TRACK (16GB)和其它另外不同的表做连接,最后三个部分的连接结构做UNION,而且更令人开心的是,这个大表在三个SELECT部分的过滤形式都是一样的,区别就是过滤的具体值不一样而已,但是这完全不妨碍采用联合索引的方式进行优化。最终联合索引建好之后,通过手工执行观察,执行计划变成了我们期待的样子:
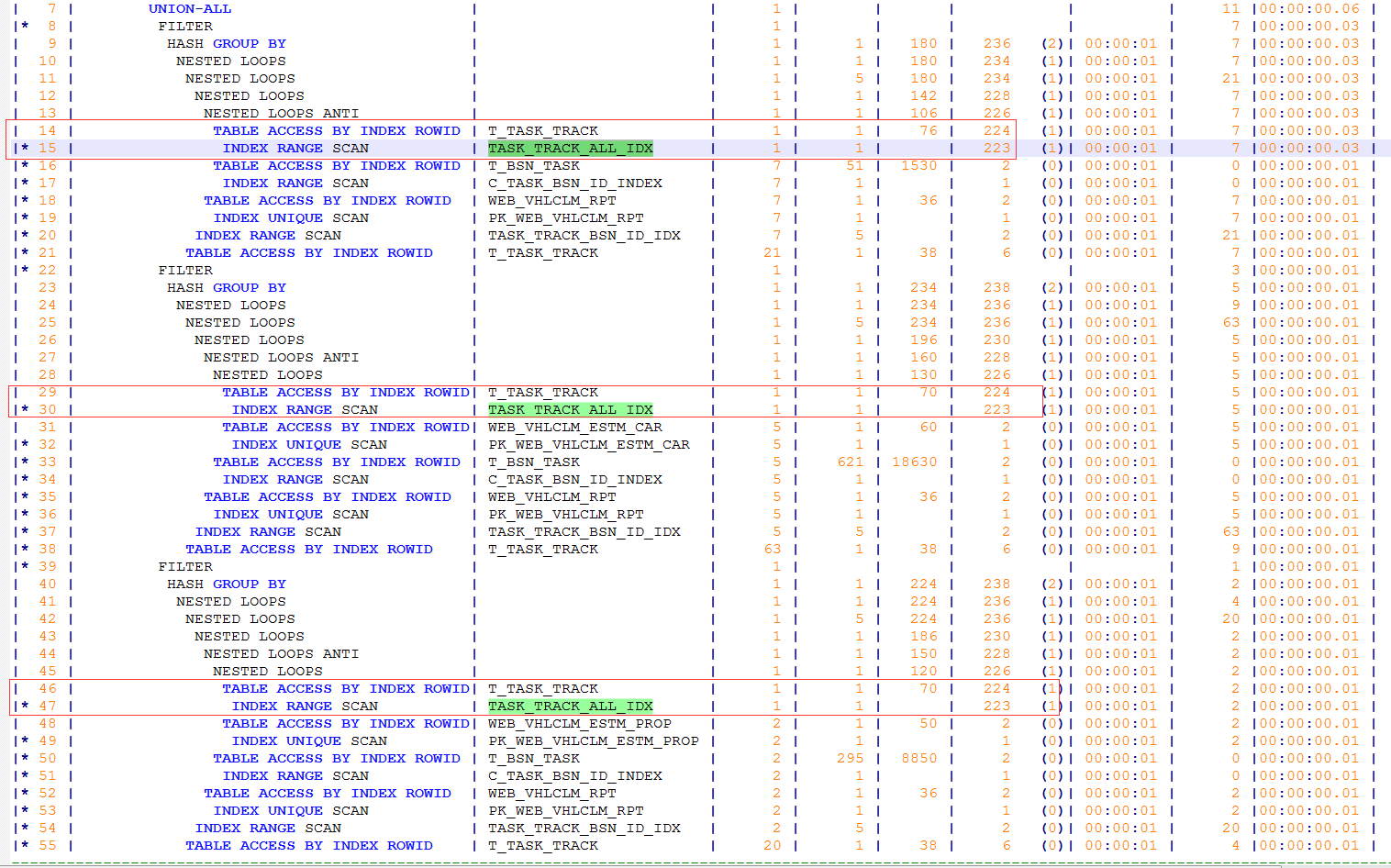
秒杀!
接下来问题就开始变得奇奇怪怪的了,上了生产之后,这个SQL死活还是要跑一分多钟,然后我们再次抓取了上生产之后的执行计划,发现和手工执行的时候,执行计划是一模一样的,这就让人难以理解了,这怎么可能呢?
事情经过了一番波折之后,他们把XML里面的封装代码改为了如下形式:
and (t2.t_fnh_tm between to_Date('${TStartTm}', 'yyyy-mm-dd') and to_Date('${TEndTm}', 'yyyy-mm-dd') and ...)
对XML完全不了解的我,不太明白这个地方把“#”变成“$”,然后两边打上单引号,这之间有啥区别,大意是说,#表示站位,相当于变量,而$符号表示预处理还是啥的。总之就这么上生产之后,就可以秒杀了,因为执行时间太短,没抓到具体的SQL_ID然后看看计划啥的,总之就这么弄了。但是他们告诉我,这种封装形式,很容易产生SQL注入的风险,指不定哪天就会变成一个巨大的炸弹。虽然他们提前有做验证处理啥的,可以避归这个风险,但这始终是一种隐患。
走投无路的我,甚至跑去问ChatGPT,额。。这个这个吧,大家都在探索这个,我就问问也没啥的吧,然后得到的答案也不能说不对,只能说没打中我的痒处:

别问我咋连上的,我找的朋友帮忙问的。在大语言模型开始轰炸的时代,这类方法的探索我们将来是避免不了的,但是一定要注意安全,莫要把自家的生产代码胡乱的去往里面贴,切记!!!另外,GPT是很厉害,但是自身的硬实力才是永恒的!
到了第二天,我始终心心念念着这个问题,并且在诊断过程当中,发现这个SQL昨天跑的慢的时候,执行一次它的IO消耗居然高达3个多G,这又让我感觉莫名其妙的,一个返回几条数据的代码,全部走的索引,有这么夸张?我的第一反应就是,莫不是走了错误的索引?我昨天实际上看花眼了?
碰到这个问题之前,我刚刚完成了一个11个T大库的DG搭建,弄了一整天眼睛都发麻了,因为前两天一套生产备库发生了更夸张的故障,一个存储的LUN,莫名其妙的就不见了,然后备库就自动DOWN掉了,存储那边说他们在存储阵列里面甚至一点儿都找不到这个LUN曾经存在过的痕迹,但是备库服务器这边连这个LUN的WWID号都还摆在配置文件那儿,正在闪闪发光呢,难不成这一年多这套备库一直是被天上的神仙姐姐给撑起来的?我大概是全国最倒霉的DBA,一天尽碰到这些问题,到现在存储厂商都没能给我一个答案,这要是发生在生产主库那边,第一个死的肯定是我,因为备库的性能我实在没底儿他能撑得起来。
唉,还是回到这个问题吧,然后白天的时候,我让前端的同事,在代码里面加了一个/*+ gather_plan_statistics */ ,并将代码的封装改回去重新在跑一次,然后再次抓取了A-Time的执行计划,格老子的这次我就一行一行的比对,我就不信了,终于。。。
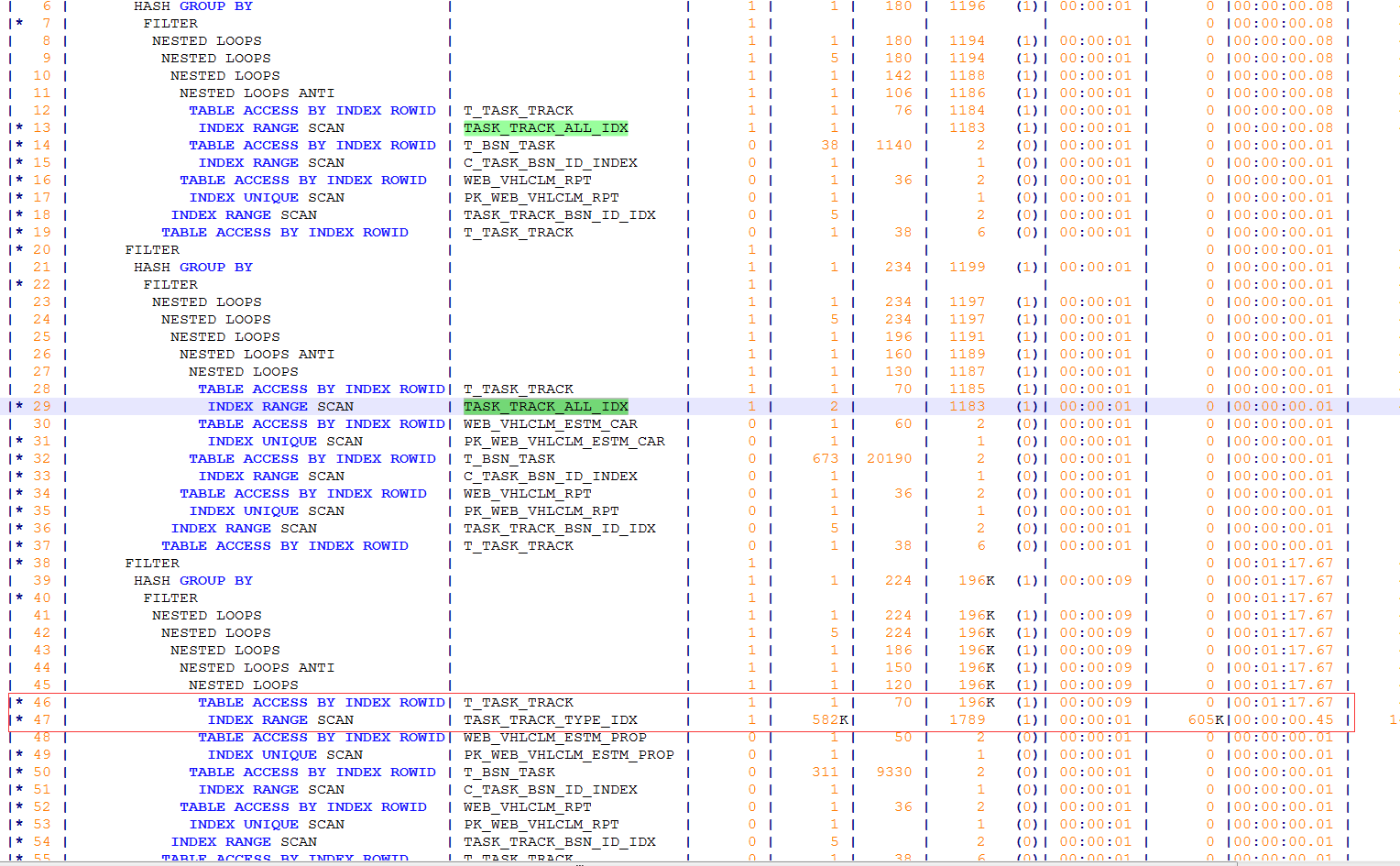
没错,事情就是这么简单!第三部分的SELECT语句走错了索引,没有走我们期待的联合索引,产生了大量的回表。咱不是说,昨天的时候生产的执行计划和手工执行计划是一样的么?额,这个这个吧,我不说了嘛我碰到这问题之前,搭建了一整天的DG,正处于头晕脑胀的巅峰时期呢!实际上是不一样的,各位可以发现,今天的这张计划截图和我们手工执行的计划截图,他们两几乎就是一对儿双胞胎,长的极其相似,被我给看漏了。问题发发现了,我也懒得去看什么10053为啥这部分它没有走对索引,几个大表那么多索引,密密麻麻的一大片,头皮发麻,让他们加个hint提示完事儿。
对于本文标题所示的这种情况,我个人觉得哈,问题极易出现在两个地方:1. SQL的入参类型不对;2. 走错了执行计划。这是我们DBA首先应该要想到并且进行排查的两个可能原因。至于GPT给的答案,我个人比较倾向于,在我们把屎盆子扣其它地方之前,先尽量把自己的屁股擦干净再说,除非有很明显的证据能立刻证明其它地方有问题。
唉,我们DBA最需要的是什么?是休息啊!!!这篇文章我就是来赚墨值的,摩天轮上面有很多好东西呀!
