




Stream Load是Doris用户最常用的数据导入方式之一,它是一个同步的导入方式,用户通过发送 HTTP 协议请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果,用户可直接通过请求的返回体判断本次导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。
Doris的导入(Load)功能就是将用户的原始数据导入到 Doris表中。Doris底层实现了统一的流式导入框架,而在这个框架之上,Doris提供了非常丰富的导入方式以适应不同的数据源和数据导入需求。Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式将CSV格式或JSON格式的数据批量地导入Doris,并返回数据导入的结果。用户可以直接通过Http请求的返回体判断数据导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。本文将从Stream Load的使用方法、执行流程、源码解析等方面对Stream Load的实现原理进行深入地解析。
一、如何使用
Stream Load 通过 HTTP 协议提交和传输数据。这里通过 curl
命令展示如何提交导入。用户也可以通过其他 HTTP client 进行操作。
使用方法如下:
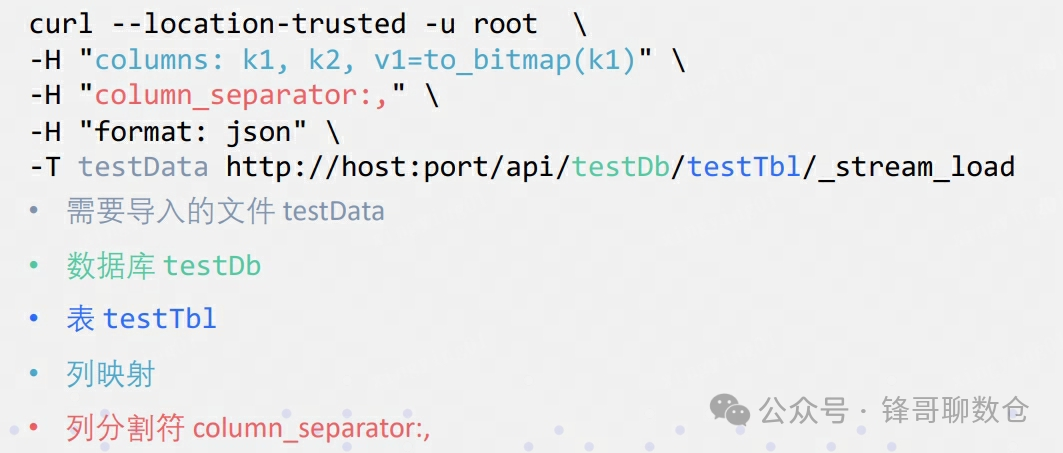
详细的使用方法可以参考官网:https://doris.aache.org/zh-CN/docs/data-operate/import/import-way/stream-load-manual/
了解了使用方法后,本文将从用户使用的角度来介绍Stream Load的整体流程。
二、整体流程
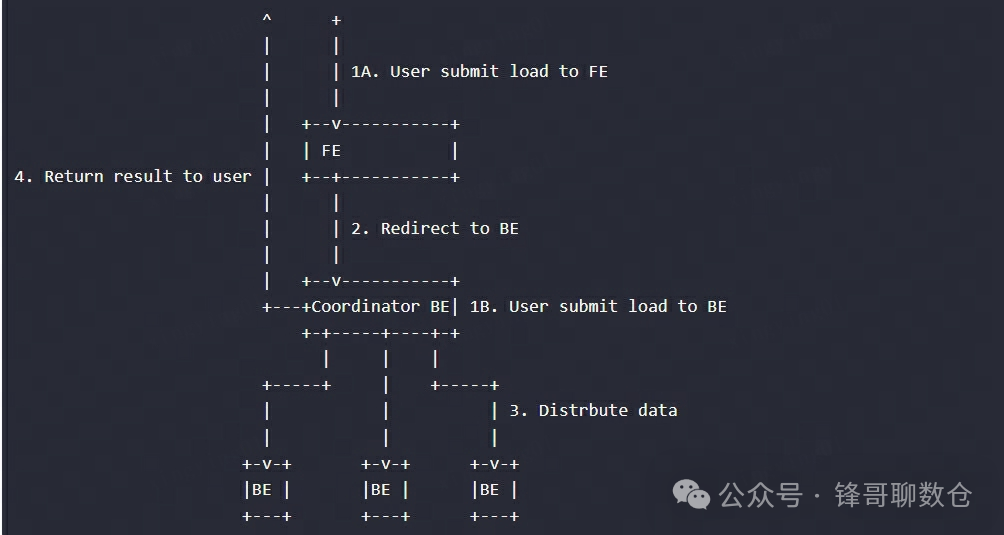
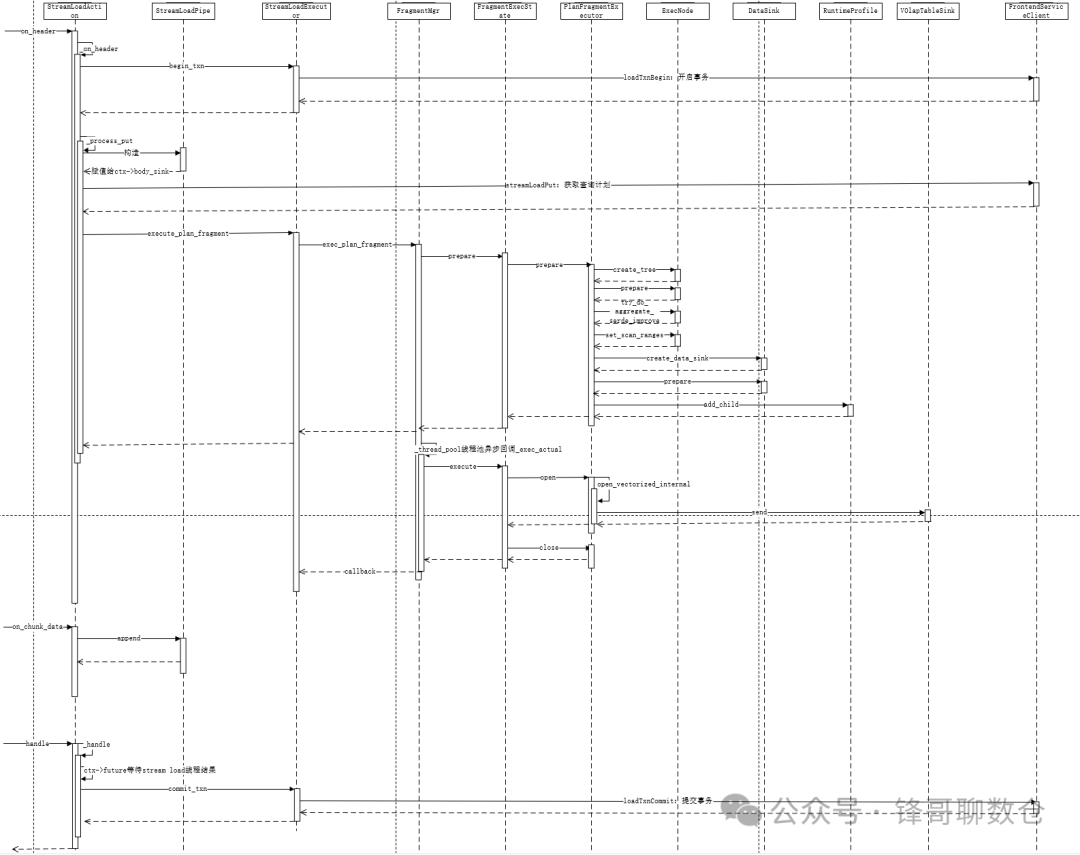
用户将Stream Load的Http请求提交给FE,FE会通过 Http 重定向(Redirect)将数据导入请求转发给某一个BE节点,该BE节点将作为本次Stream Load任务的Coordinator。在这个过程中,接收请求的FE节点仅仅提供转发服务,由作为 Coordinator的BE节点实际负责整个导入作业,比如负责向Master FE发送事务请求、从FE获取导入执行计划、接收实时数据、分发数据到其他Executor BE节点以及数据导入结束后返回结果给用户。用户也可以将Stream Load的Http请求直接提交给某一个指定的BE节点,并由该节点作为本次Stream Load任务的Coordinator。在Stream Load过程中,Executor BE节点负责将数据写入存储层。
下图展示了 Stream load 的主要流程,省略了一些导入细节。在Coordinator BE中,通过一个线程池来处理所有的Http请求,其中包括Stream Load请求。一次Stream Load任务通过导入的Label唯一标识。
三、原理解析
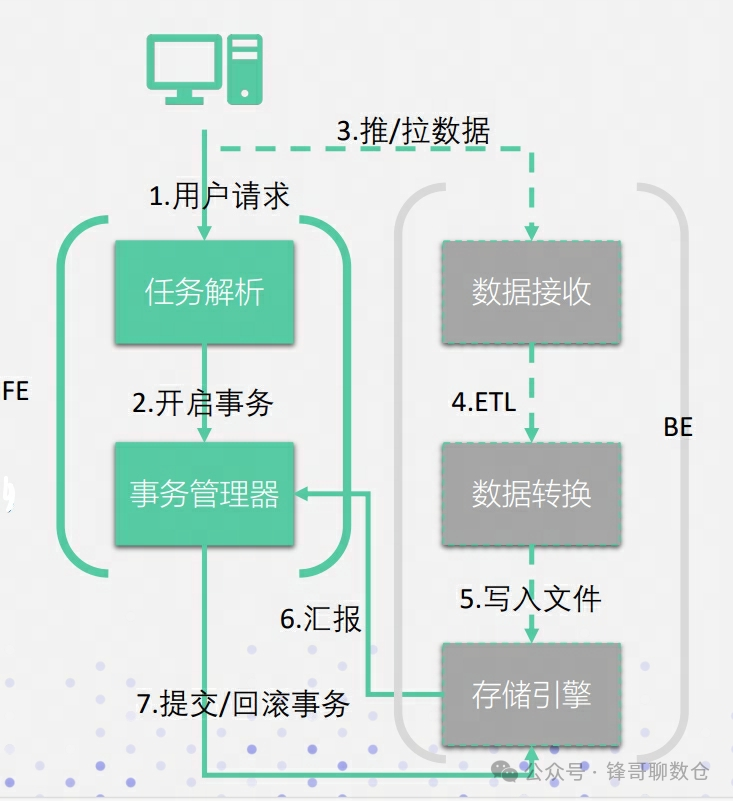
上文从用户使用的角度介绍了整体的执行流程。所谓源码面前了无秘密,接下来笔者将从源码实现的角度进行内核原理解析。为了方便介绍,笔者将Doris 中的数据导入功能分为以下几个模块:
• 任务解析模块(Analyzer) :FE会进行Http的Header解析(其中包括判断协议是否正确以及解析数据导入的库、表、Label等信息),然后进行用户鉴权,并生成相应的执行计划
• 事务管理器(Txn Manager) :对于Doris,每次导入都是一个事务。该模块负责事务开启、提交及回滚,保证这一批次导入数据的原子性生效。
• 数据接收与转换(Data Receiver, Extract & Transform) :类似于ETL过程中的E和T两个阶段。不同的导入方式也会有不同的数据接收方式,对于Stream Load是通过推送的方式,对于Routine Load是通过从源端主动拉取的方式。接收到数据之后会根据Schema以及用户定义的方式进行转换(例如Column列的转换函数及映射),转换之后会转换成Doris自己的内存结构。
• 存储引擎(Storage Engine):负责将ET之后的数据写入存储,并落到磁盘。
3.1、FE:任务解析模块(Analyzer)
该模块主要负责权限校验、重定向以及生成导入执行计划。
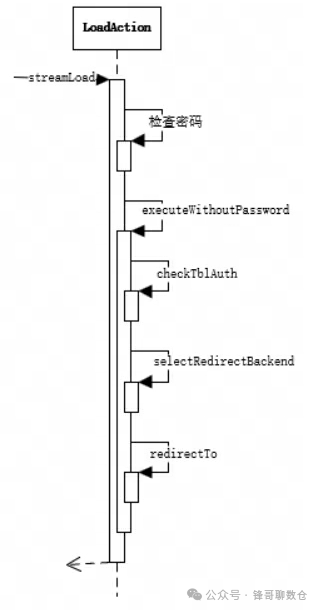
3.1.1、FE校验及重定向
FE会进行Http的Header解析(其中包括判断协议是否正确以及解析数据导入的库、表、Label等信息),然后进行用户鉴权。
大概步骤:
1. 检查用户名密码
2. 检查权限
3. 随机选择一个BE,Redirect到这个BE上
流程图:
源码调用栈:
streamLoad
|--> //检查密码
|--> executeCheckPassword(request, response)
|--> executeWithoutPassword
| |--> //检查权限
| |--> checkTblAuth
| |--> //随机选择一个BE
| |--> selectRedirectBackend
| |--> //Redirect到这个BE上
| |--> redirectTo
3.1.2、生成导入规划
在导入过程中,Coordinator BE节点去FE请求查询计划,然后这个Coordinator Be节点会基于这个导入计划进行执行并会向其他节点分发数据。具体的执行流程后文会进行介绍,这里主要阐述FE是如何生成执行计划的。
大概步骤:
1. 创建StreamLoadTask
2. 创建 StreamLoadPlanner
3. 创建 执行计划
• 构建tuple descriptor
• 创建 scan node
• 创建 sink nod
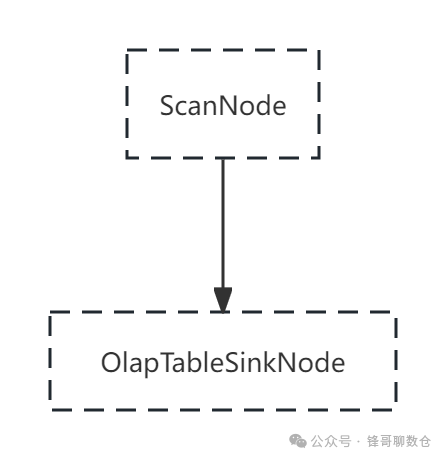
stream load的数据源只有一个,因此只有一个scan node,然后发送给本节点的olapTableSink,不需要exchange node来接受多个不同的scan node的数据。
源码调用栈:
//FE执行计划的入口
streamLoadPutImpl
|--> generatePlanFragmentParams
| |--> //1.根据be发过来的rpc request信息来创建StreamLoadTask
| |--> //StreamLoadTask是对request信息的重新封装,并且做了一些权限以及参数合法性的校验
| |--> streamLoadTask = StreamLoadTask.fromTStreamLoadPutRequest(request);
| |--> //2.创建 StreamLoadPlanner,用来生成执行计划
| |--> planner = new StreamLoadPlanner(db, table, streamLoadTask)
| |--> //3.创建执行计划
| |--> //导入计划会生成两个节点,一个scan_node和一个sink node。整体上跟查询执行计划没有区别,唯一的区别是普通的执行计划将结果输出到客户端,而导入是将结果写到文件里面。
| |--> planner.plan(streamLoadTask.getId(), multiTableFragmentInstanceIdIndex);
| | |--> //3.1 创建tuple description
| | |--> //用来描述目标表的结构和数据类型,例如表里有多少列以及列的类型以及内存中的组织方式,是否有NULL值等
| | |--> scanTupleDesc = descTable.createTupleDescriptor("ScanTuple");
| | |--> for (Column col : destTable.getFullSchema())
| | |--> slotDesc.setColumn(col);
| | |--> scanSlotDesc.setColumn(col);
| | |--> //loop end
| | |--> scanTupleDesc.setTable(destTable);
| | |--> //3.2 创建scan node
| | |--> //主要负责读取源数据,并且会转化为查询框架所需要的内存结构,
| | |--> //以及会进行谓词的过滤以及数据的转换,之后会发送给olapTableSink
| | |--> //stream load的数据源只有一个,
| | |--> //因此只有一个scan node,然后发送给本节点的olapTableSink,
| | |--> //不需要exchange node来接受多个不同的scan node的数据
| | |--> scanNode.init(analyzer)
| | | |--> initParamCreateContexts
| | | |--> /*loop for scanProviders*/
| | | |--> createContext
| | | | |--> //3.2.1 初始化扫描范围
| | | | |--> params = new TFileScanRangeParams();
| | | | |--> setFileAttributes(ctx.fileGroup, fileAttributes);
| | | | | |--> //3.2.2 初始化行列分隔符
| | | | | |--> textParams.setColumnSeparator
| | | | |--> //3.2.3 初始化列映射
| | | | |--> initColumns(ctx, analyzer);
| | | | | |--> initColumns
| | | | | | |--> //重写表达式:展开中间变量
| | | | | | |--> rewriteColumns
| | | | | | |--> //如果没有指定列,会根据schema填充列
| | | | | | |--> initColumns
| | | | | | |--> //解析表达式
| | | | | | |--> analyzeAllExprs
| | | |--> //3.2.4 初始化where条件
| | | |--> initAndSetPrecedingFilter
| | | |--> initAndSetWhereExpr
| | | |--> setDefaultValueExprs
| | | |--> this.contexts.add(context);
| | | |--> /*end loop for scanProviders*/
| | |--> scanNode.finalize(analyzer)
| | |--> //3.3 创建sink node
| | |--> //主要用来接收来自scan node的数据,
| | |--> //然后根据导入表的信息(partition、bucket等)发送给不同的be节点,
| | |--> //这些be节点最终会完成数据的写入
| | |--> olapTableSink = new OlapTableSink
| | |--> olapTableSink.init
| | |--> olapTableSink.setPartialUpdateInputColumns
| | |--> olapTableSink.complete
3.2、FE:事务管理(Txn Manager)
3.2.1、技术背景
由于一次数据导入涉及到FE节点以及多个BE节点的协调及交互,需要考虑以下两个问题:
3.2.1.1、数据完整性问题
如果数据导入过程中异常中断了,则Doris集群可能存在没有完全导入的数据。这样用户读取:
1. 可能只能够读到一部分数据即脏读的情况;
2. 如果业务侧有重试机制,则可能会出现重复数据的情况。

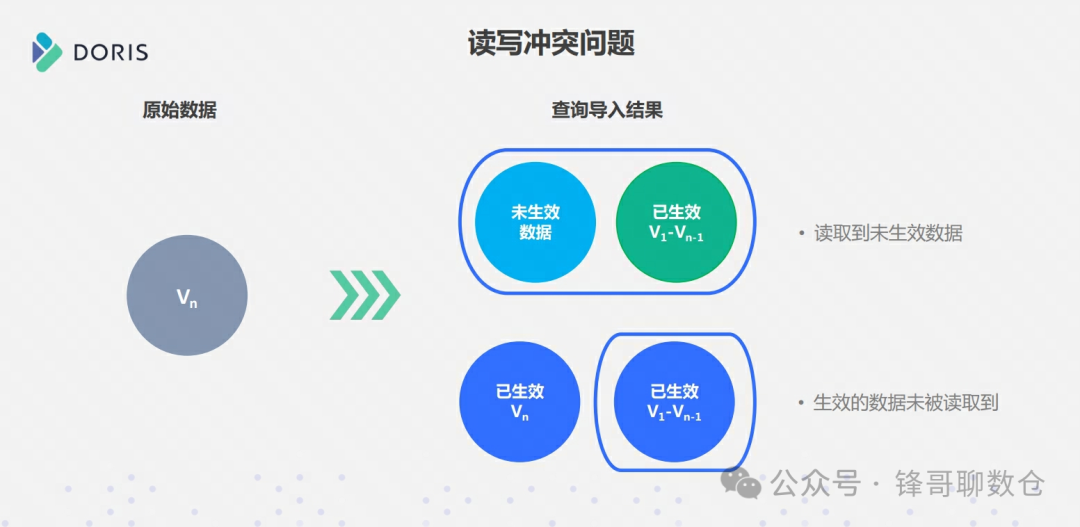
3.2.1.2、读写冲突问题
在同时存在写入和读取的Doris集群里面,需要关注读写冲突问题:
1. 未生效的数据被读取,即读到了脏数据;
2. 已经生效的数据没有被读到,即产生了读的延迟;
3.2.2、事务管理分析
为了解决以上问题,Doris通过事务(Transaction)来保证数据导入的原子性,一次Stream Load任务对应一个事务,并通过两阶段提交机制来保证分布式系统的一致性。
两阶段提交将一个事务的过程分为两个阶段,一个是投票一个是事务提交。
• FE充当协调者:Stream Load的事务管理由FE负责,FE通过FrontendService接收Coordinator BE节点发送来的Thrift RPC事务请求
• BE充当参与者:负责具体的任务执行,并会向FE发送Thrift RPC事务请求
事务请求类型包括Begin Transaction、Commit Transaction和Rollback Transaction。Doris的事务状态包括:PREPARE、COMMITTED、VISIBLE和ABORTED。
3.2.2.1、第一阶段提交
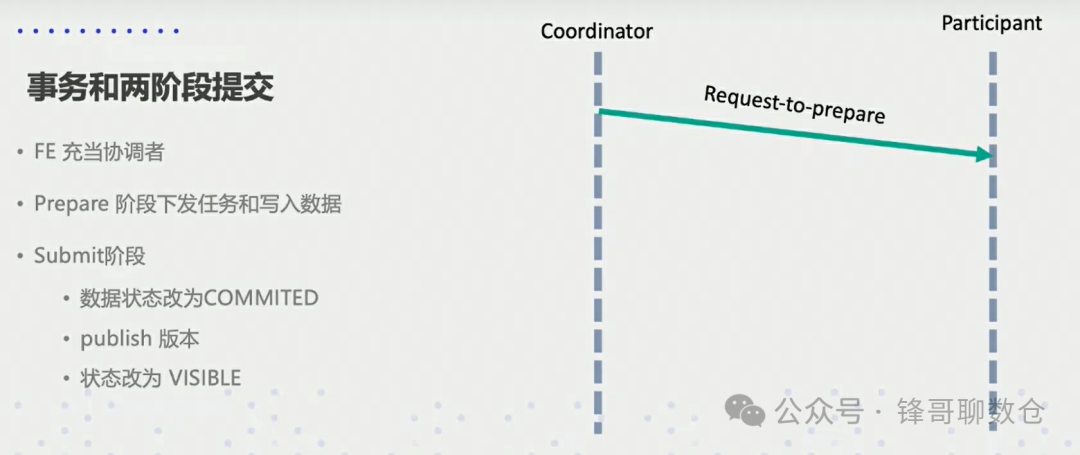
FE作为协调者会查看整个集群中的参与者能否正常工作,协调者向参与者发送事务的执行请求,并等待参与者的事务执行结果。
参与者提交请求后,事务开始执行,执行完以后BE不能直接提交,而是将BE的执行情况反馈给协调者,同时阻塞等待协调者的后续操作指令。
3.2.2.2、第二阶段提交
经过第一阶段的协调,各个参与者执行完对应的导入任务后,都会向FE回复自己的执行情况,这个时候存在3种情况:
1. 所有参与者正确执行事务
2. 1个或者多个参与者执行失败
3. 协调者等待超时
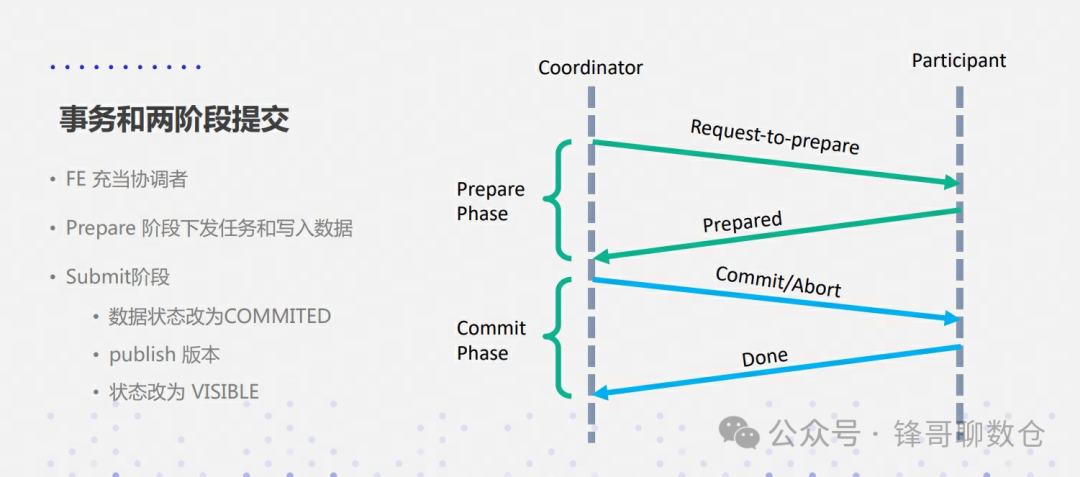
对于第一种情况,Coordinator BE节点会向协调者FE发送Commit Transaction请求,FE收到Commit Transaction请求之后会执行Commit Transaction以及Publish Version两个操作。首先,FE会判断每一个Tablet成功写入数据的副本数量是否超过了Tablet副本总数的一半,如果每一个Tablet成功写入数据的副本数量都超过Tablet副本总数的一半(多数成功),则Commit Transaction成功,并将事务状态设置为COMMITTED;否则,向Coordinator BE返回Commit Transaction失败的信息。COMMITTED状态表示数据已经成功写入,但是数据还不可见,需要继续执行Publish Version任务,此后,事务不可被回滚。
FE会有一个单独的线程对Commit成功的Transaction执行Publish Version,FE执行Publish Version时会通过Thrift RPC向Transaction相关的所有Executor BE节点下发Publish Version请求,Publish Version任务在各个Executor BE节点异步执行,将数据导入生成的Rowset变为可见的数据版本。当Executor BE上所有的Publish Version任务执行成功,FE会将事务状态设置为VISIBLE,并向Coordinator BE返回Commit Transaction以及Publish Version成功的信息。如果存在某些Publish Version任务失败,FE会向Executor BE节点重复下发Publish Version请求直到之前失败的Publish Version任务成功。如果在一定超时时间之后,事务状态还没有被设置为VISIBLE,FE就会向Coordinator BE返回Commit Transaction成功但Publish Version超时的信息(注意,此时数据依然是写入成功的,只是还处于不可见状态,用户需要使用额外的命令查看并等待事务状态最终变为VISIBLE。)
对于后两种情况,协调者通常认为参与者无法正常的执行事务,即无法保证数据的一致性,Coordinator BE节点会向FE发送Rollback Transaction请求,执行事务回滚。FE收到事务回滚的请求之后,会将事务的状态设置为 ABORTED,并通过Thrift RPC向Executor BE发送Clear Transaction的请求,Clear Transaction任务在BE节点异步执行,将数据导入生成的Rowset标记为不可用,这些Rowset在之后会从BE上被删除。状态为COMMITTED的事务(Commit Transaction成功但Publish Version超时的事务)不能被回滚。
3.3、BE:数据接收与转换
导入请求进入BE以后,BE内部有一套流式处理框架,用来处理一个标准http请求过程。其中主要的处理逻辑都实现在StreamLoadAction中:
• StreamLoadAction.on_header :进行协议解析,向fe申请事务处理以及执行计划。on_header函数会调用到StreamLoadAction,并进行_on_header和_process_put方法的调用
• StreamLoadAction.process_put :调用到execute_plan_fragment函数将任务加入到线程池_thread_pool中;
• StreamLoadAction.on_chunk_data :进行导入数据的append;
• StreamLoadAction.handle :通过ctx->future等待stream load线程结束,并进行收尾工作
• Plan Executor:负责执行计划的执行
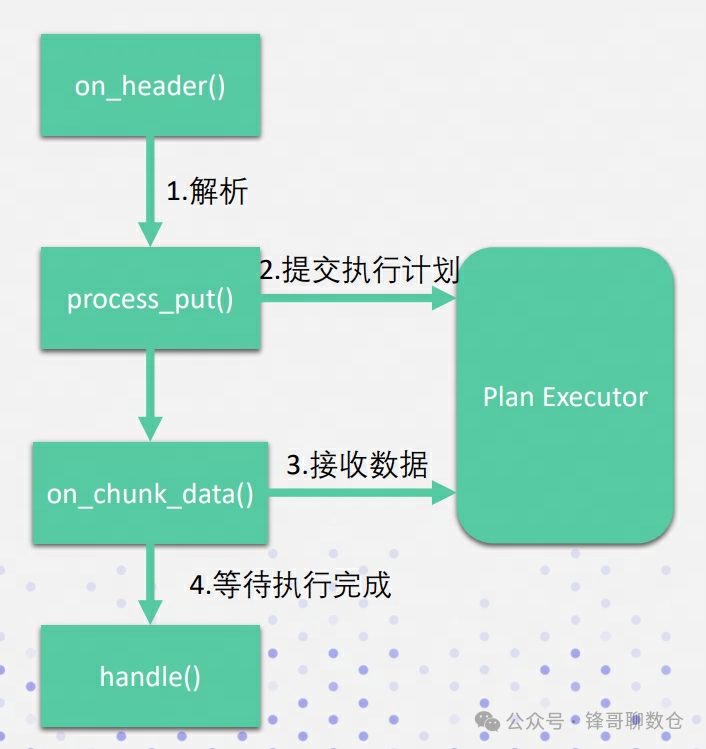
源码结构:
3.3.1、on_header
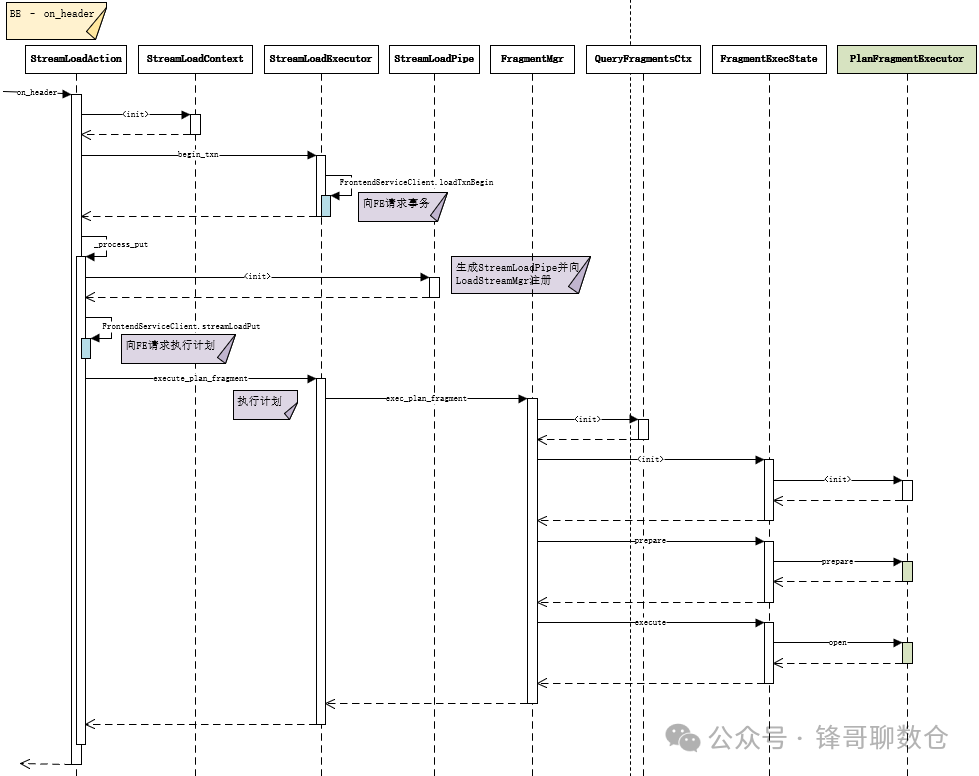
on_header作为BE的入口函数发生在http请求的header解析阶段,会处理以下逻辑:
1. 生成一个 StreamLoadContext 对象,用来保存StreamLoad执行的上下文类
2. 调用_on_header,进行权限校验以及协议检查,并向FE发送开启事务的rpc
3. 调用_process_put,生成StreamLoadPipe并向LoadStreamMgr注册,向FE请求执行计划,最后调用到execute_plan_fragment函数将任务加入到线程池_thread_pool中;
其中StreamLoadPipe是数据通路,主要是read和append两个方法:
• BE通过on_chunk_data接收数据时调用append方法;
• ScannerScheduler::_scanner_scan函数使用NewOlapScanner对象进行数据读取时调用read方法,从 StreamLoadPipe中读取数据并进行相应的ETL;
源码调用栈:
doris::StreamLoadAction::on_header
|--> //生成一个 StreamLoadContext 对象 ctx
|--> //ctx包含此次导入的标签、trx_id、是否为两阶段提交等
|--> ctx = std::make_shared<StreamLoadContext>(_exec_env)
|--> StreamLoadAction::_on_header
| |--> //会做一些权限检查
| |--> //parse_basic_auth
| |--> //会检查http协议的输入是否规范,并基于http协议构造结构体
| |--> //开启事务
| |--> StreamLoadExecutor::begin_txn(ctx)
源码结构:
3.3.2、_process_put
该模块主体逻辑如下:
1. 生成并注册一个 StreamLoadPipe
2. 向 FE 请求一个执行计划
3. 开始执行计划
• 构建QueryFragmentsCtx
• 构建FragmentExecState,并于其中构建PlanFragmentExecutor
• 执行FragmentExecState.prepare,并执行PlanFragmentExecutor.prepare
• 执行FragmentExecState.execute,并执行PlanFragmentExecutor.open
源码调用栈:
|--> StreamLoadAction::_process_put
| |--> //1. 生成并注册一个 StreamLoadPipe
| |--> pipe=std::make_shared<io::StreamLoadPipe>(io::kMaxPipeBufferedBytes)
| |--> //构造request
| |--> request.db = ctx->db;
| |--> request.tbl = ctx->table;
| |--> //2. 向 FE 请求一个执行计划
| |--> client->streamLoadPut(ctx->put_result, request)
| |--> //判断能否执行,例如如果fe没有找到tablet则会报错
| |--> Status plan_status(Status::create(ctx->put_result.status))
| |--> //3. 开始执行计划:用于提交一个导入的执行计划到线程池中执行
| |--> StreamLoadExecutor::execute_plan_fragment(ctx)
| | |--> FragmentMgr::exec_plan_fragment(params,exec_fragment)
| | | |--> //做一些执行器的准备工作
| | | |--> PlanFragmentExecutor::prepare
| | | | |--> //解析执行计划,生成执行计划树
| | | | |--> ExecNode::create_tree
| | | | | |--> ExecNode::create_tree_helper
| | | | | | |--> vectorized::NewFileScanNode::init
| | | |--> //将任务提交到线程池执行
| | | |--> _thread_pool->submit_func(_exec_actual(fragment_executor, cb))
| | | | |--> FragmentMgr::_exec_actual
| | | | | |--> PlanFragmentExecutor::execute
| | | | | |--> exec_fragment(fragment_executor->runtime_state(), &status);
| | | | | | |--> //返回状态
| | | | | | |--> ctx->promise.set_value(*status);
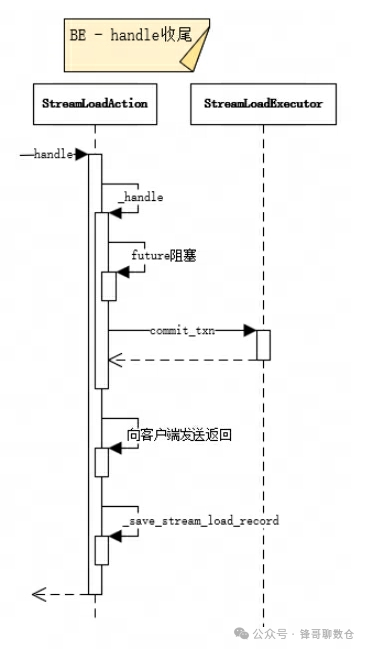
3.3.3、handle
该模块主要用于数据处理的收尾阶段,主体逻辑如下:
• 首先future.get()阻塞,等待on_header中对future进行解除
• 如果执行成功则调用StreamLoadExecutor.commit_txn进行提交
• 向客户端发送StreamLoad的相关统计信息
• 记录StreamLoad相关信息
源码调用栈:
doris::StreamLoadAction::handle
|--> //data receiving begins in StreamLoadAction::_handle
|--> StreamLoadAction::_handle
| |--> //执行到_handle()时说明用户的源数据已经发送完毕,这里会finish streamloadpipe
| |--> ctx->body_sink->finish()
| |--> //wait stream load finish
| |--> //等待导入结束
| |--> RETURN_IF_ERROR(ctx->future.get());
| |--> //提交事务
| |--> _exec_env->stream_load_executor()->commit_txn
| |--> //记录StreamLoad相关信息
| |--> StreamLoadAction::_save_stream_load_record
源码结构:
3.3.4、on_chunk_data
BE的Stream Load处理线程会按块(chunk)接收通过Http传输的实时数据并append写入StreamLoadPipe中。
• 会以4M的buffer 不断的读取的数据,然后调用append方法将数据写到StreamLoadPipe里面去
• 这里可以理解为数据是生成者,后文提到的_scanner_scan是数据的消费者。
• 如果StreamLoadPipe数据生产速度大于消费速度,那么写入就会变阻塞
源码调用栈:
//1.接受数据
//2.写入StreamLoadPipe
void StreamLoadAction::on_chunk_data(HttpRequest* req) {
std::shared_ptr<StreamLoadContext> ctx =
std::static_pointer_cast<StreamLoadContext>(req->handler_ctx());
struct evhttp_request* ev_req = req->get_evhttp_request();
auto evbuf = evhttp_request_get_input_buffer(ev_req);
//1.不断的读取数据
while (evbuffer_get_length(evbuf) > 0) {
auto bb = ByteBuffer::allocate(128 * 1024);
auto remove_bytes = evbuffer_remove(evbuf, bb->ptr, bb->capacity);
bb->pos = remove_bytes;
bb->flip();
//2.写入StreamLoadPipe
//StreamLoadPipe::append
auto st = ctx->body_sink->append(bb);
ctx->receive_bytes += remove_bytes;
}
}
源码结构:
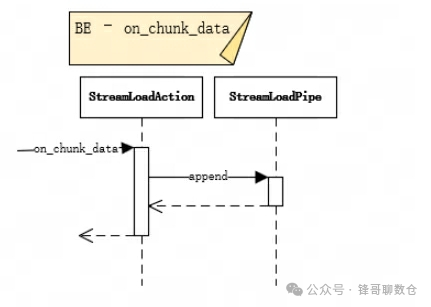
3.3.5、Plan Executor:执行计划的执行
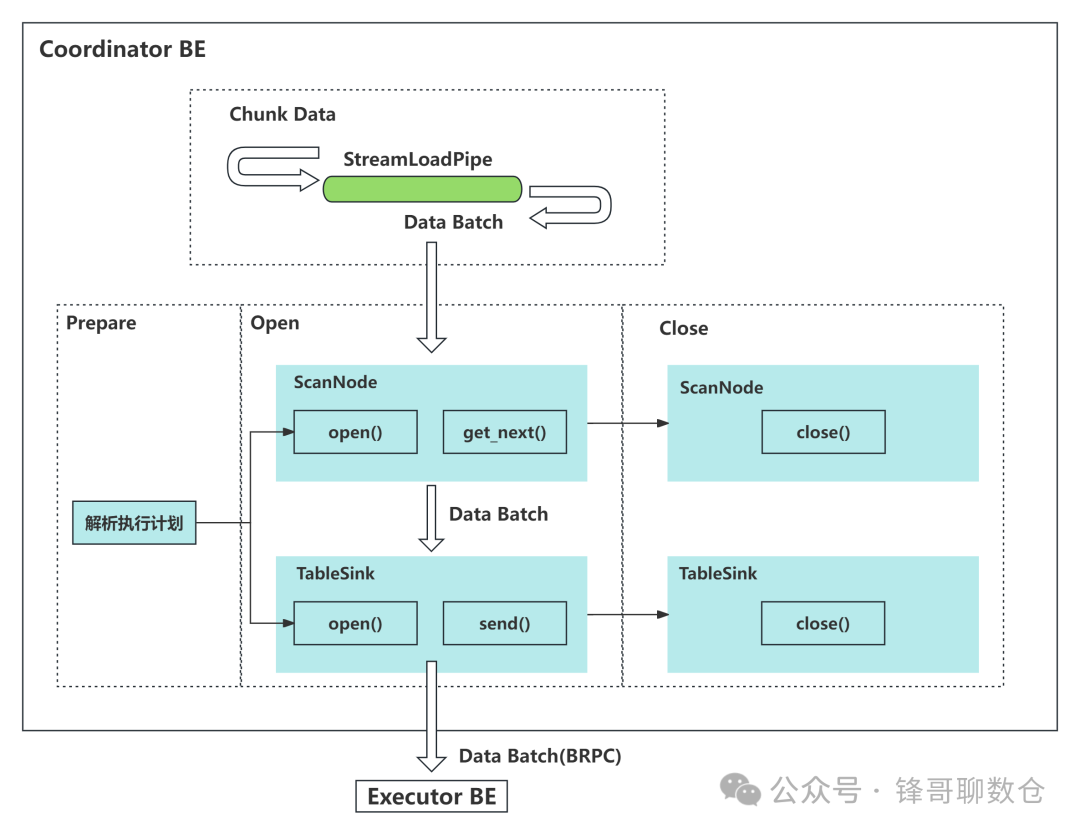
_process_put将任务提交到线程池后,开始异步的执行。在Doris的BE中,所有执行计划由FragmentMgr管理,每一个导入计划的执行由PlanFragmentExecutor负责。BE从FE获取到导入执行计划之后,会将导入计划提交到FragmentMgr的线程池执行。Stream Load 的导入执行计划只有一个Fragment, 其中包含一个ScanNode 和 一个 OlapTableSink。ScanNode负责实时读取流式数据,并将 CSV 格式或JSON格式的数据行转为 Doris 的Tuple格式;OlapTableSink 负责将实时数据发送到对应的Executor BE节点,每个数据行对应哪个Executor BE节点是由数据行所在的Tablet存储在哪些BE上决定的,可以根据数据行的 PartitionKey和DistributionKey确定该行数据所在的Partition和Tablet,每个Tablet及其副本存储在哪台BE节点上是在Table或Partition创建时就已经确定的。
导入执行计划提交到FragmentMgr的线程池之后,Stream Load线程会按块(chunk)接收通过Http传输的实时数据并写入StreamLoadPipe中,ScanNode会从StreamLoadPipe中批量读取实时数据,OlapTableSink会将ScanNode读取的批量数据通过BRPC发送到Executor BE进行数据写入。所有实时数据都写入StreamLoadPipe之后,Stream Load线程会等待导入计划执行结束。
PlanFragmentExecutor执行一个具体的导入计划过程由Prepare、Open和Close三个阶段组成。
• 在Prepare阶段,主要对来自FE的导入执行计划进行解析;
• 在Open阶段,会打开ScanNode和OlapTableSink,ScanNode负责每次读取一个Batch的实时数据,OlapTableSink负责调用BRPC将每一个Batch的数据发送到其他Executor BE节点;
• 在Close阶段,负责等待数据导入结束,并关闭ScanNode和OlapTableSink。
Stream Load的导入执行计划如下图所示。
源码调用栈:
PlanFragmentExecutor::prepare流程如下:
|--> FragmentMgr::exec_plan_fragment(params,exec_fragment)
| |--> //1. 在Prepare阶段,主要对来自FE的导入执行计划进行解析;
| |--> //做一些执行器的准备工作
| |--> PlanFragmentExecutor::prepare
| | |--> //解析执行计划,生成执行计划树
| | |--> ExecNode::create_tree
| | | |--> ExecNode::create_tree_helper
| | | | |--> vectorized::NewFileScanNode::init
| | | | | |--> VScanNode::init
| | | | | | |--> //为父类成员进行初始化
| | | | | | |--> ExecNode::init
| | | | | | |--> //注册runtime filter
| | | | | | |--> //在数据读取之前,Doris会将where条件及runtime filter中的谓词下推到数据源读取过程中,
| | | | | | |--> //从而充分利用索引减少需要读取的数据量。
| | | | | | |--> RuntimeFilterConsumer::init
| | | | | | | |--> RuntimeFilterConsumer::_register_runtime_filter
| | |--> //_plan->prepare
| | |--> NewFileScanNode::prepare
| | | |--> VScanNode::prepare
| | |--> DataSink::create_data_sink
| | | |--> VOlapTableSink::init
| | | | |--> AsyncWriterSink::init
| | |--> AsyncWriterSink::prepare
| | | |--> DataSink::prepare
| |--> //将任务提交到线程池执行
| |--> _thread_pool->submit_func(_exec_actual(fragment_executor, cb))
| | |--> FragmentMgr::_exec_actual
| | | |--> PlanFragmentExecutor::execute
| | | |--> exec_fragment(fragment_executor->runtime_state(), &status);
| | | | |--> //返回状态
| | | | |--> ctx->promise.set_value(*status);
PlanFragmentExecutor::execute流程如下:
doris::ThreadPool::dispatch_thread-->_Function_handler
|--> doris::FragmentMgr::_exec_actual
| |--> PlanFragmentExecutor::execute
| | |--> //2. 在Open阶段,会进行具体的执行
| | |--> PlanFragmentExecutor::open
| | | |--> PlanFragmentExecutor::open_vectorized_internal
| | | | |--> //_plan->open
| | | | |--> //打开ScanNode
| | | | |--> VScanNode::open
| | | | | |--> ExecNode::open()
| | | | | | |--> VScanNode::alloc_resource
| | | | | | | |--> VScanNode::_prepare_scanners
| | | | | | | | |--> //为每个需要scan的tablet创建一定数量用于数据读取的NewOlapScanner对象,
| | | | | | | | |--> //然后调用NewOlapScanner::prepare函数执行运行前的准备。
| | | | | | | | |--> NewOlapScanNode::_init_scanners
| | | | | | | | | |--> NewOlapScanner::prepare
| | | | | | | | | | |--> VScanner::prepare
| | | | | | | | |--> //启动数据读取过程
| | | | | | | | |--> VScanNode::_start_scanners
| | | | | | | | |--> //初始化ScannerContext对象
| | | | | | | | |--> ScannerContext::init
| | | | | | | | |--> //将ScannerContext对象提交到ScannerScheduler中的pending队列中,等待被调度
| | | | | | | | |--> ScannerScheduler::submit
| | | | |--> //打开OlapTableSink
| | | | |--> AsyncWriterSink::open()
| | | | | |--> VTabletWriter::open()
| | | | | | |--> VTabletWriter::_init
| | | | | | | |--> IndexChannel::init
| | | | | | | | |--> /*loop for tablets*/
| | | | | | | | |--> channel->add_tablet(tablet)
| | | | | | | | |--> channels.push_back(channel)
| | | | | | | | |--> _channels_by_tablet.emplace(channels);
| | | | | | | | |--> /*end loop for tablets*/
| | | | | | | | |
| | | | | | | | |--> /*loop for _node_channels*/
| | | | | | | | |--> VNodeChannel::init
| | | | | | | | |--> /*loop for _node_channels*/
| | | | | | |
| | | | | | |--> /*loop for _node_channels*/
| | | | | | |--> VNodeChannel::open
| | | | | | | |--> VNodeChannel::_open_internal
| | | | | | | |--> RPC-->tablet_writer_open
| | | | | | |--> /*end loop for _node_channels*/
| | | | | | |--> //创建后台线程,定期扫描channel中数据并发送
| | | | | | |--> bthread_start_background(periodic_send_batch)
| | | | | | | |--> VTabletWriter::_send_batch_process
| | | | | | | | |--> /*loop*/
| | | | | | | | |--> //遍历所有的channel
| | | | | | | | |--> IndexChannel::for_each_node_channel
| | | | | | | | |--> VNodeChannel::try_send_and_fetch_status
| | | | | | | | |--> //将发送任务丢到线程池
| | | | | | | | |--> thread_pool_token->try_send_pending_block
| | | | | | | | | |--> //将数据丢到Block,并进行压缩
| | | | | | | | | |--> Block::serialize
| | | | | | | | | | |--> BlockCompressionCodec::compress
| | | | | | | | | |--> //如果有其他be需要传输在,则走http逻辑
| | | | | | | | | |--> tablet_writer_add_block_by_http
| | | | | | | | | |--> //如果不需要传输,则本地执行写入逻辑
| | | | | | | | | |--> PInternalServiceImpl::_tablet_writer_add_block
| | | | | | | | | | |--> //将写入任务放到线程池
| | | | | | | | | | |--> _heavy_work_pool->_tablet_writer_add_block
| | | | | | | | | | | |--> //执行正在的写入逻辑
| | | | | | | | | | | |--> LoadChannelMgr::add_batch
| | | | | | | | | | | | |--> //1. 通过load_id获取channel结构体
| | | | | | | | | | | | |--> _get_load_channel(channel, is_eof, load_id, request)
| | | | | | | | | | | | |--> //2. 检查内存是否超限制
| | | | | | | | | | | | |--> MemTableMemoryLimiter::handle_memtable_flush
| | | | | | | | | | | | |--> //3. 向load channel中添加batch
| | | | | | | | | | | | |--> LoadChannel::add_batch
| | | | | | | | | | | | | |--> //a. 获取channel
| | | | | | | | | | | | | |--> _get_tablets_channel
| | | | | | | | | | | | | |--> //b. 将block添加到channel
| | | | | | | | | | | | | |--> TabletsChannel::add_batch
| | | | | | | | | | | | | | |--> //将数据反序列化
| | | | | | | | | | | | | | |--> Block::deserialize
| | | | | | | | | | | | | | |--> write_tablet_data
| | | | | | | | | | | | | | | |--> DeltaWriter::write
| | | | | | | | | | | | | | | | |--> MemTableWriter::write
| | | | | | | | | | | | | |--> //c. 处理一些收尾工作
| | | | | | | | | | | | | |--> LoadChannel::_handle_eos
| | | | | | | | | | | | | | |--> TabletsChannel::close
| | | | | | | | | | | | |--> //4. 处理收尾工作
| | | | | | | | | | | | |--> LoadChannelMgr::_finish_load_channel
| | | | | | | | |--> /*end loop*/
| | | | |--> PlanFragmentExecutor::get_vectorized_internal
| | | | | |--> ExecNode::get_next_after_projects
| | | | | | |--> //调用VScanNode::get_next函数读取数据
| | | | | | | |--> func->doris::vectorized::VScanNode::get_next
| | | | | | | |-->//从队列中取出block,然后将空block调用ScannerContext::return_free_block函数放回队列
| | | | | | | |--> vectorized::ScannerContext::get_block_from_queue
| | | | | | | | |--> //将ScannerContext对象提交到ScannerScheduler中的pending队列中,等待被调度
| | | | | | | | |--> ScannerScheduler::submit
| | | | | | | | | |--> blocking_put(ScannerContext)
| | | | | | | | |--> //Wait for block from queue
| | | | | | | | |--> _blocks_queue_added_cv.wait_for(l, 1s);
| | | | |--> AsyncWriterSink::send()
| | | | | |--> VTabletWriter::append_block
| | | | | | |--> VNodeChannel::add_block
| | |--> //3. 在Close阶段,负责等待数据导入结束,并关闭ScanNode和OlapTableSink。
| | |--> PlanFragmentExecutor::close
| |--> //cb是从StreamLoadExecutor::execute_plan_fragment传进来的
| |--> cb(fragment_executor->runtime_state(), &status);
| | |--> //返回状态
| | |--> ctx->promise.set_value(*status);
3.3.5.1、ScanNode
Doris使用基于队列和io线程池的方式异步地进行scan操作,能够在避免io过程堵塞执行线程的同时对读取过程进行调度和管理。在执行读取操作时,Doris一方面会将谓词进行下推,另一方面会根据表的类型对原始记录进行聚合或去重,从而减少不必要的中间结果,提升读取性能。
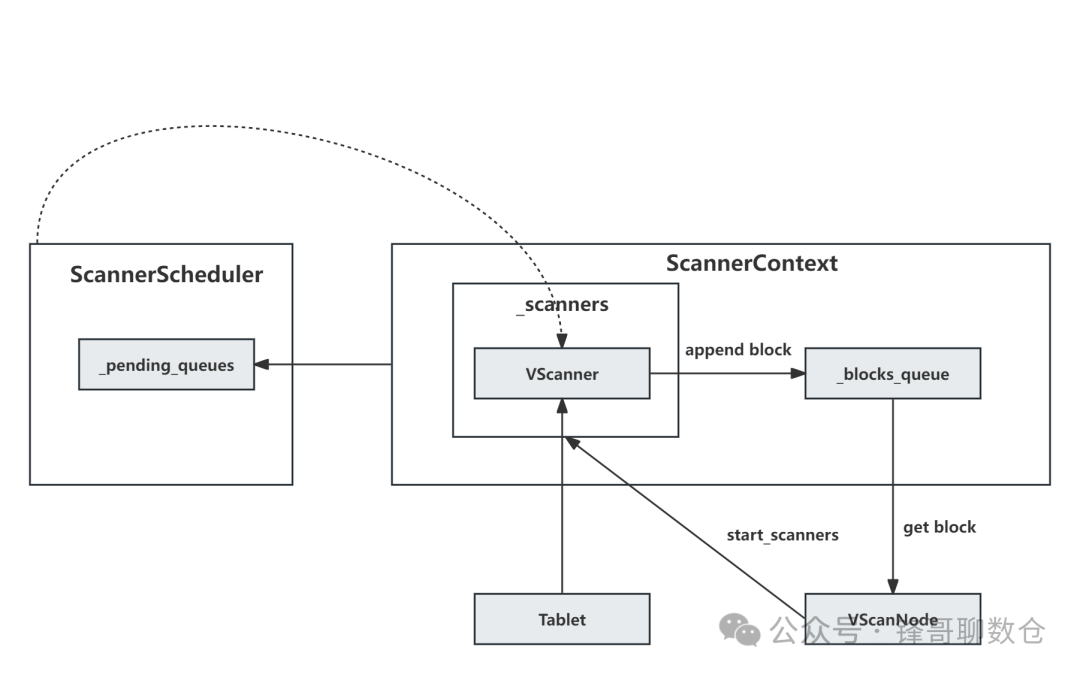
ScanNode算子的实现主要包含以下3部分:
• VScanNode::open() : 负责申请资源,并启动后台scanner线程
• VScanNode::get_next() : 负责从ScannerContext中的block队列中读取数据。
• VScanner : 包含了后台scanner线程,负责对tablet中的一部分数据进行读取,并将结果添加到ScannerContext中的block队列
任务发起(VScanNode::open)
PlanFragmentExecutor::open
|--> PlanFragmentExecutor::open_vectorized_internal
| |--> //_plan->open
| |--> //打开ScanNode
| |--> VScanNode::open
| | |--> ExecNode::open()
| | | |--> VScanNode::alloc_resource
| | | | |--> VScanNode::_prepare_scanners
| | | | | |--> //为每个需要scan的tablet创建一定数量用于数据读取的NewOlapScanner对象,
| | | | | |--> //然后调用NewOlapScanner::prepare函数执行运行前的准备。
| | | | | |--> NewOlapScanNode::_init_scanners
| | | | | | |--> NewOlapScanner::prepare
| | | | | | | |--> VScanner::prepare
| | | | | |--> //启动数据读取过程
| | | | | |--> //scanner线程后台执行
| | | | | |--> VScanNode::_start_scanners
| | | | | |--> //初始化ScannerContext对象
| | | | | |--> ScannerContext::init
| | | | | |--> //将ScannerContext对象提交到ScannerScheduler中的pending队列中,等待被调度
| | | | | |--> ScannerScheduler::submit
任务消费(VScanNode::get_next)
该模块是_blocks_queue 队列的消费者。
VScanNode::get_next函数读取数据,该函数会调用ScannerContext::get_block_from_queue函数从队列中取出block,然后将空block通过调用ScannerContext::return_free_block函数放回队列。
|--> PlanFragmentExecutor::get_vectorized_internal
| |--> ExecNode::get_next_after_projects
| | |--> //调用VScanNode::get_next函数读取数据
| | |--> func->doris::vectorized::VScanNode::get_next
| | | |-->//从队列中取出block,然后将空block调用ScannerContext::return_free_block函数放回队列
| | | |--> vectorized::ScannerContext::get_block_from_queue
| | | | |--> //Wait for block from queue
| | | | |--> //等待从_blocks_queue中获取数据
| | | | |--> _blocks_queue_added_cv.wait_for(l, 1s);
任务生产(VScanner)
该模块是_blocks_queue 队列的生成者。VScanner 模块会调度后台scanner线程,从 StreamLoadPipe中读取数据并进行相应的ETL,并将结果添加到ScannerContext中的block队列。其中主要的处理逻辑在ScannerScheduler::_scanner_scan。
ScannerScheduler::_scanner_scan函数负责使用NewOlapScanner对象进行数据读取,处理流程如下:
1. 如果当前NewOlapScanner对象为初次读取,则调用NewOlapScanner::open函数对其进行初始化
2. 调用VScanner::try_append_late_arrival_runtime_filter函数将延迟到达的runtime filter合并到谓词集合中。
3. 重复执行如下流程进行数据读取:
4.
1. 调用ScannerContext::get_free_block函数获取一个空闲的block。
2. 然后调用VScanner::get_block函数将数据读入该block,读取完成后将block放入集合中。
5. 调用ScannerContext::append_blocks_to_queue函数将block集合放入队列中等待拉取,然后调用ScannerContext::push_back_scanner_and_reschedule函数将当前NewOlapScanner对象放回等待下一次调度。
ScannerScheduler::_scanner_scan
|--> scanner->init
|--> //对父类成员进行初始化
|--> scanner->open
|--> //将延迟到达的runtime filter合并到谓词集合中
|--> scanner->try_append_late_arrival_runtime_filter
|--> //重复执行如下流程进行数据读取
|--> /*loop*/
|--> //获取一个空闲的block
|--> ScannerContext::get_free_block
|--> VScanner::get_block
| |--> VFileScanner::_get_block_impl
| | |--> NewJsonReader::get_next_block
| | | |--> //忽略一些堆栈
| | | |--> StreamLoadPipe::read_one_message
| | | | |--> StreamLoadPipe::_read_next_buffer
| | | | |--> FileReader::read_at
| | | | | |--> StreamLoadPipe::read_at_impl
| | | | | | |--> while (*bytes_read < bytes_req)
| | | | | | |--> _get_cond.wait(l);
|--> //将block集合放入队列中等待拉取
|--> ctx->append_blocks_to_queue(blocks);
| |--> _blocks_queue.push_back
|--> /*end loop*/
3.3.5.2、SinkNode
OlapTableSink负责Stream Load任务的数据分发。Doris中的Table可能会有Rollup或物化视图,每一个Table及其Rollup、物化视图都称为一个Index。数据分发过程中,IndexChannel会维护一个Index的数据分发通道,Index下的Tablet可能会有多个副本(Replica),并分布在不同的BE节点上,NodeChannel会在IndexChannel下维护一个Executor BE节点的数据分发通道,因此,OlapTableSink下包含多个IndexChannel,每一个IndexChannel下包含多个NodeChannel
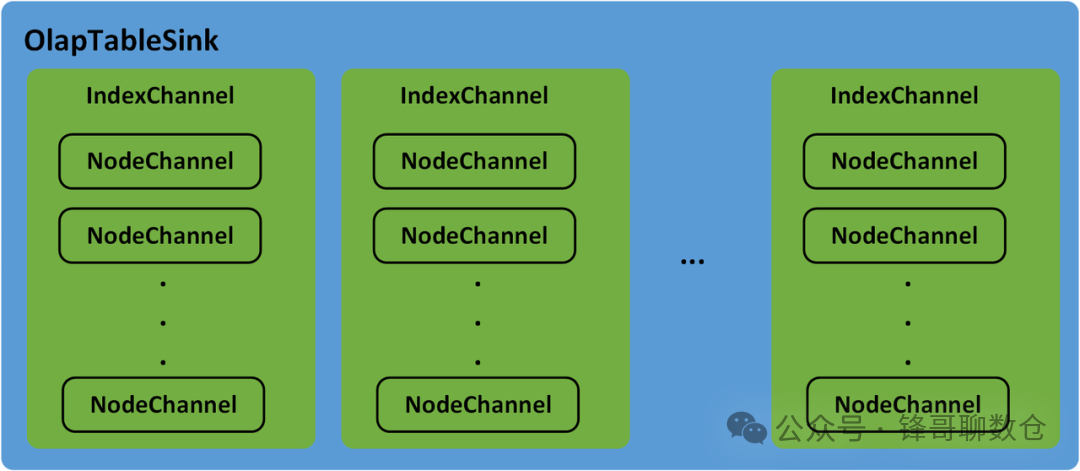
OlapTableSink分发数据时,会逐行读取NewOlapScanNode获取到的数据Batch,并将数据行添加到每一个Index的IndexChannel中。可以根据 PartitionKey和DistributionKey确定数据行所在的Partition和Tablet,进而根据Tablet在Partition中的顺序计算出数据行在其他Index中对应的Tablet。每一个Tablet可能会有多个副本,并分布在不同的BE节点上,因此,在IndexChannel中会将每一个数据行添加到其所在Tablet的每一个副本对应的NodeChannel中。每一个NodeChannel中都会有一个发送队列,当NodeChannel中新增的数据行累积到一定的大小就会作为一个数据Batch被添加到发送队列中。OlapTableSink中会有一个固定的线程依次轮训每一个IndexChannel下的每一个NodeChannel,并调用BRPC将发送队列中的一个数据Batch发送到对应的Executor BE上。Stream Load任务的数据分发过程下图所示。
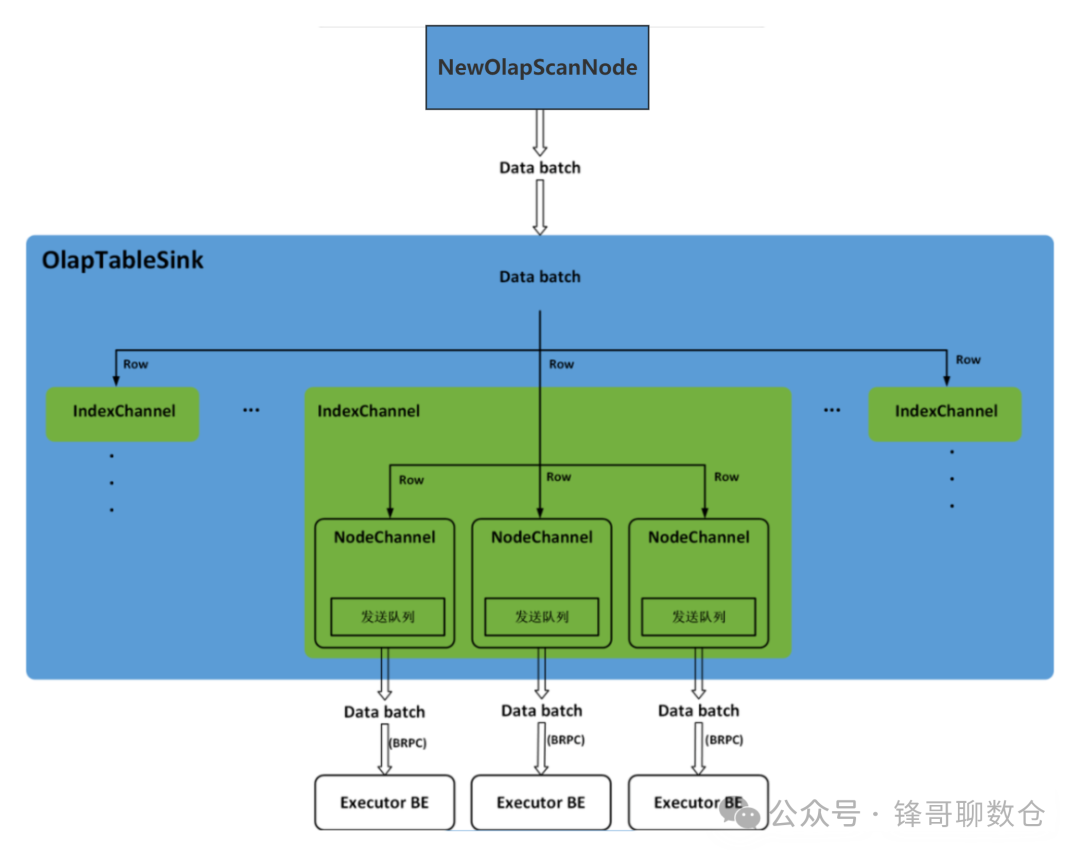
代码调用如下:
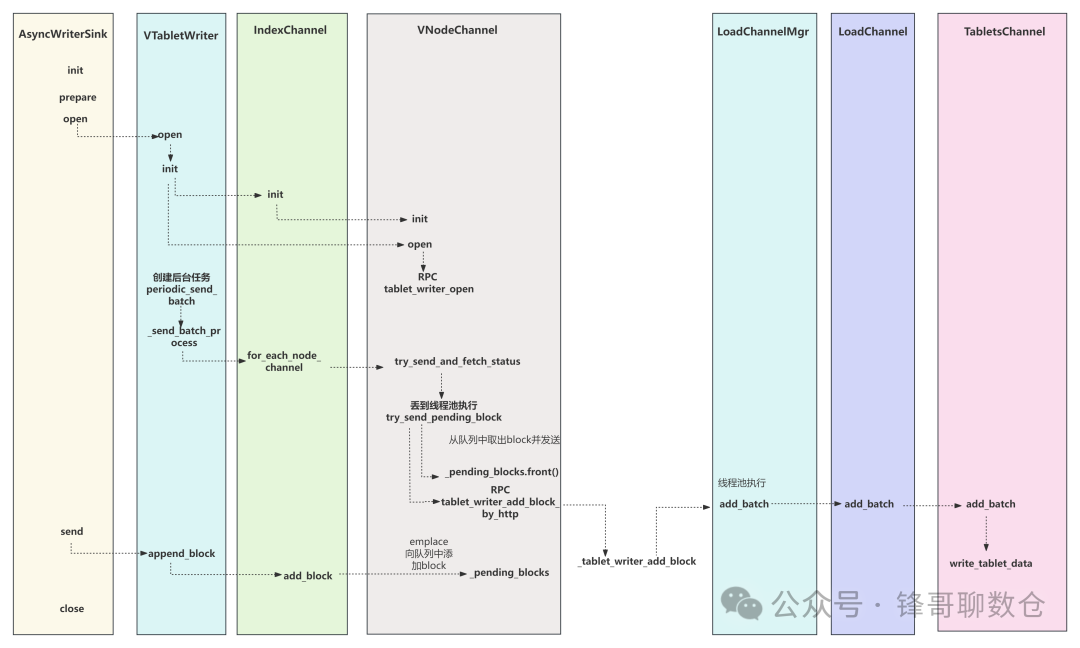
定期发送的后台线程:
doris::vectorized::IndexChannel::for_each_node_channel(const std::function<…> &) vtablet_writer.h:433
doris::vectorized::VTabletWriter::_send_batch_process vtablet_writer.cpp:959
doris::vectorized::periodic_send_batch vtablet_writer.cpp:1000
bthread::TaskGroup::task_runner(long) 0x00005555865e9da5
bthread_make_fcontext 0x00005555865dbb31
<unknown> 0x0000000000000000
3.4、BE:存储引擎(Storage Engine)
数据在经过清洗过滤后,会通过Open/AddBatch请求分批量将数据发送给存储层的BE节点上。在一个BE上支持多个LoadJob任务同时并发写入执行。LoadChannelMgr负责管理这些任务,并对数据进行分发。该章节可以参考 Doris Stream Load原理解析
四、总结
本文从Stream Load的执行流程、事务管理、导入计划的执行、数据写入等方面对Stream Load的实现原理进行了深入地解析。Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式批量地将数据导入Doris,并返回数据导入的结果。用户可以直接通过Http请求的返回体判断数据导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。
五、参考文档
关于作者
隐形(邢颖) 网易资深数据库内核工程师,毕业至今一直从事数据库内核开发工作,目前主要参与 MySQL 与 Apache Doris 的开发维护和业务支持工作。
作为 MySQL 内核贡献者,为 MySQL 上报了 60 多个 Bugfix 及优化patch,多个提交被合入 MySQL 8.0 版本。从 2023 年起加入 Apache Doris 社区,Apache Doris Active Contributor,已为社区提交并合入数十个 Commits。
