




何谓逆向工程?
与大家所习惯的流程不同,逆向工程开发反其道而行之。逆向工程从已经存在的事物切入,去理解并推断其意图。逆向工程广泛应用于硬件,编程,数据库等开发实践中。本文着重讨论其在数据库的应用。
越来越多的人青睐数据库逆向工程(DBRE),那么它具体能做什么呢?
1. 明确需求
DBRE帮助寻找并明确需求
2. 利用遗留数据
3. 整合应用程序间的差异
4. 评估软件
5. 协助维护
6. 构建文档
下面我们看一些经典案例,以便更好的理解数据库逆向工程具体是如何实的。
逆向工程案例1 : WordPress
WordPress是一个值得我们关注的数据库逆向工程小案例,不仅仅是因为WordPress是一个知名应用,还因为WordPress拥有一个被填充了真实数据的数据库,这些数据均不是私有的。下面我们来按步骤进行我们的研究。
1. 从www.superdataguy.com导出MySQL数据库。如果你发现localhost.sql无法查看,不必惊讶。请继续进行下面的步骤。
2. 将sql代码导入本地MySQL数据库。
3. 从本地MySQL数据库导出元数据,导出的文件应该是可读的。
4. 手动编辑sql,你需要手工删去 ` , unsigned , COLLATE , KEY , UNIQUE KEY , ENGINE.
5. 使用数据库建模工具(如:Datablau)来对元数据执行反向工程。
初始化Datablau模型,如下图所示。

通过查询MySQL数据库,获得字段数目统计结果,如下。
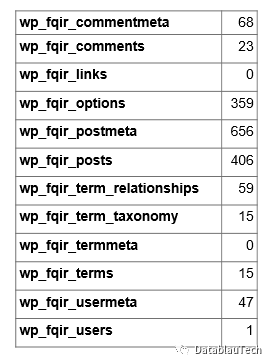
接下来,用Datablau的link功能建立外键,寻找相似的名称,并用数据分析来验证。
– SELECT * FROM wp_fqir_commentmeta
WHERE comment_ID NOT IN
(SELECT comment_ID FROMwp_fqir_comments);
-- 0 records
– SELECT * FROM wp_fqir_commentmeta
WHERE comment_ID IS NULL;
-- 0 records
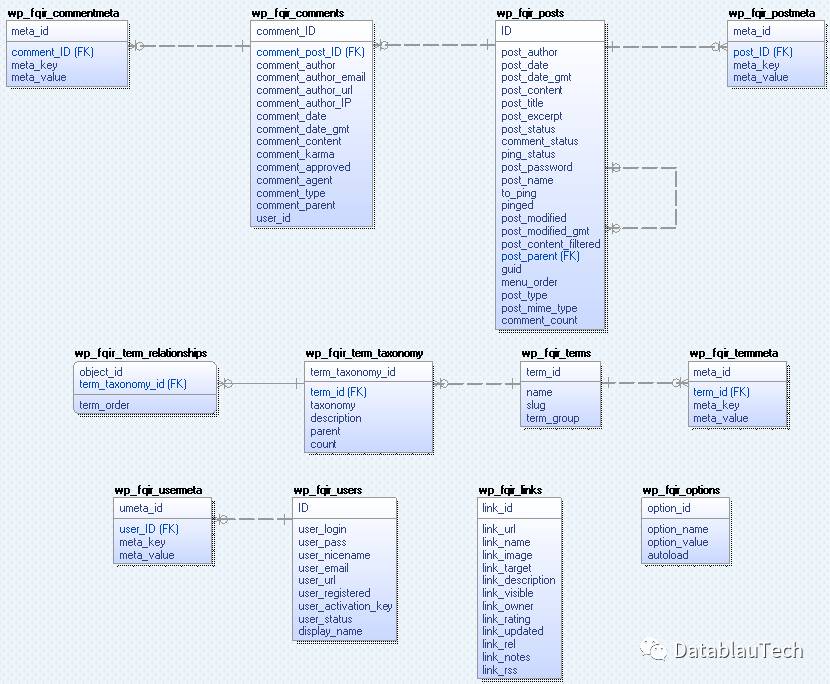
数据库逆向工程后的数据模型如下图所示
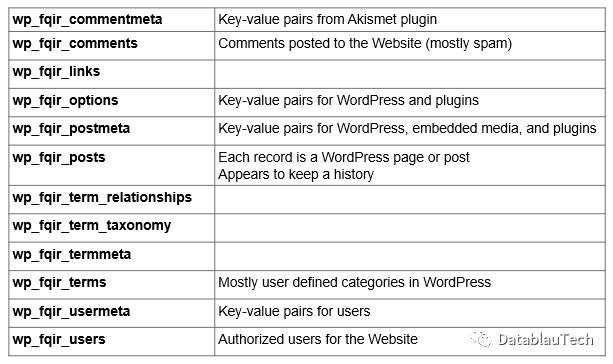
检查了各表的数据,我们获得了数据字典。
让我们再来回顾一下WordPress的逆向工程案例
WordPress拥有一个很小的数据库,它只有12张表。我们注意到它的表与表之间缺乏关联,在其他数据库中,通常表的关联性会高一些。通过逆向工程可以快速理解表的含义,及快速建立表与表之间的联系。之后就可以方便地对数据进行分析
逆向工程案例2:Adventure Works 2012
AdventureWorks 2012 是一个有趣的数据库逆向工程案例。
AdventureWorks 是一个由MSSQL Server提供的免费数据库,它同样已经填充好了数据,并且数据不是私有的。数据库拥有71张表,属于中等大小,完整性较好,只丢失了一个外键。下面我们开始进入分析流程。
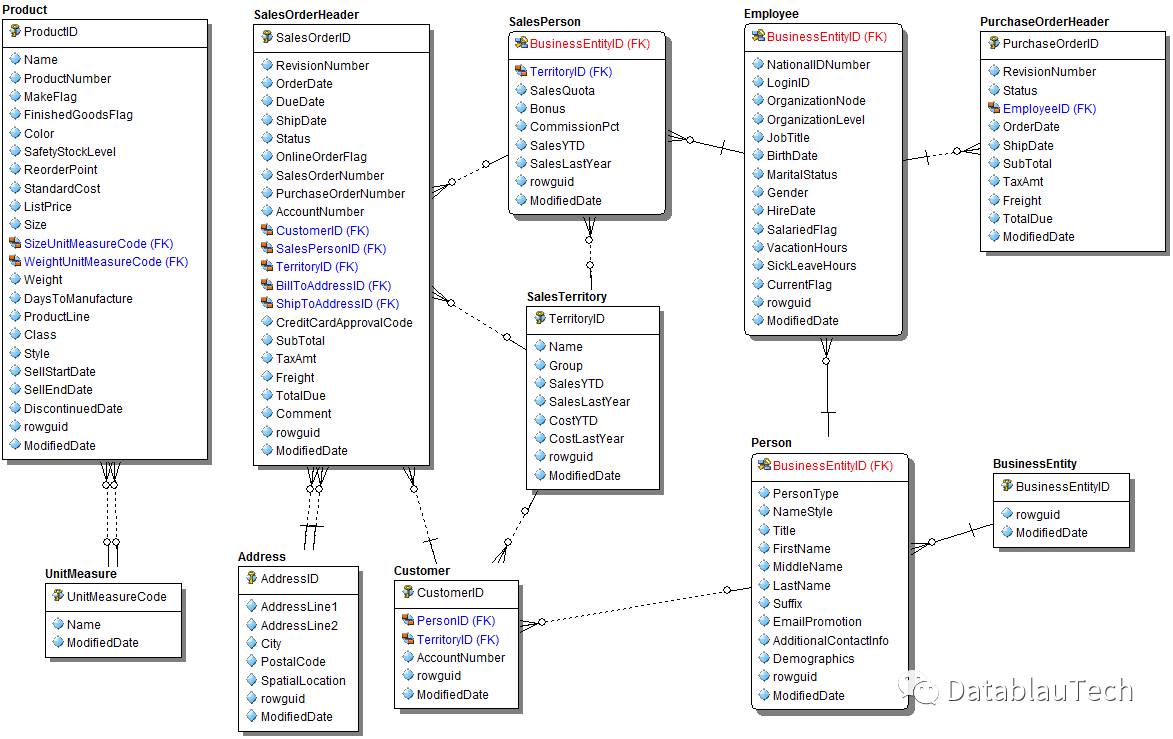
首先,我们从数据库中抽取元数据,从而获得核心模型。这个过程类似于浏览一本书,我们的目标是在不损失关键信息的前提下缩小模型的规模。开展抽取元数据这项工作后,我们会迅速加深对元数据的理解。
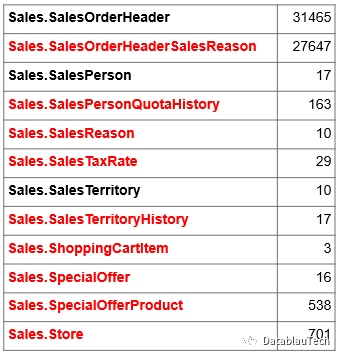
通过查询MySQL数据库,获得字段数目统计结果,如下。
计数记录部分的表征了表的目的。

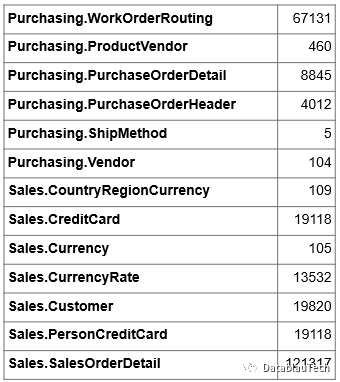
接下来我们对元数据进行分析
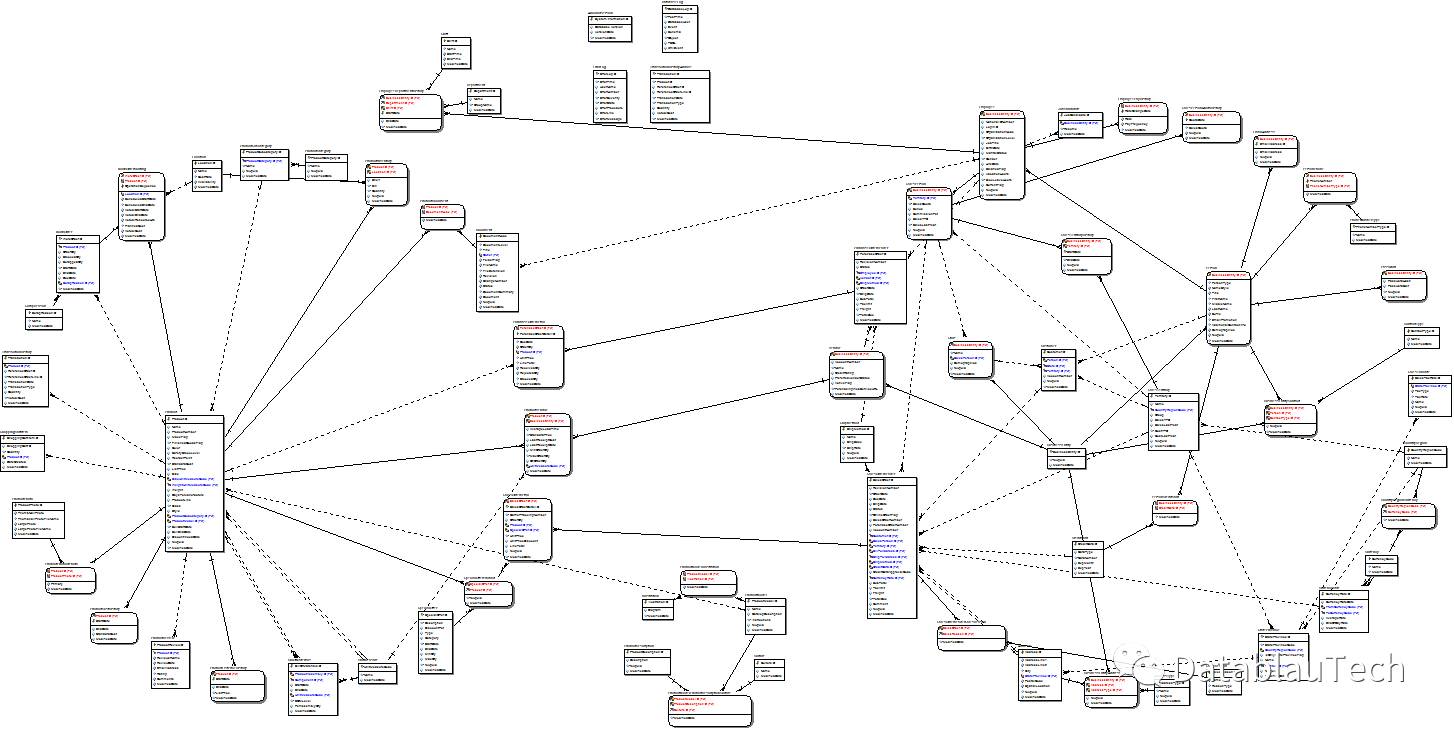
接下来删除所有拥有0个或1个连接的表。
然后删除拥有少量(小于3个)连接的表。
最终得到的表如下图所示。黑色名称表示存留的表,红色名称表示删去的表。

数据库逆向工程获取外键关系。为找到核心信息,我们删除拥有0个和1个连接的表,只会损失很少的信息。而对于拥有少量(我们采用3个以下)连接的表的删除是试探性的。
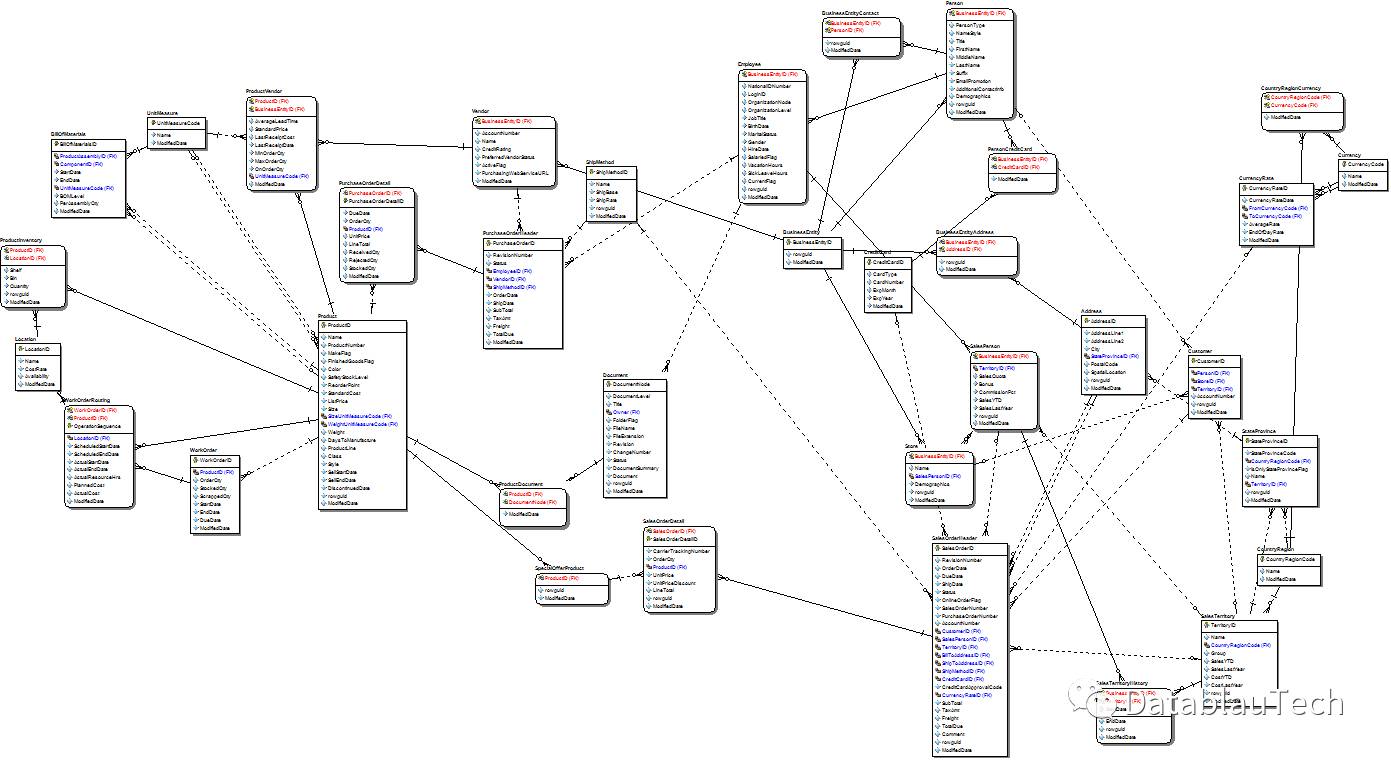
另外,父类和子类的关系(如BusinessEntity之于Employee, Vendor, Person, Store)是很复杂的。接下来我们来梳理一下父类和子类之间的关系,如下所示。
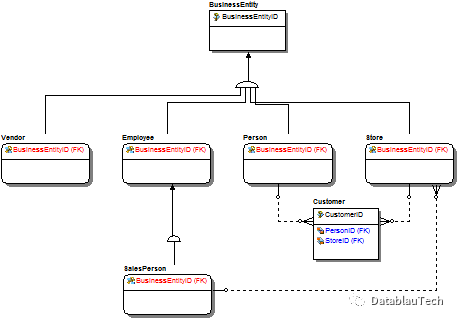
最终,我们通过对逆向工程的结果梳理,快速定位核心数据和关系。
数据库逆向工程案例3:Core DBRE
这个项目建立了一个巨大的数据仓库,拥有100个事实表和200个维度表,拥有8500张表。这是个巨大的项目,笔者也处于学习理解的过程中,在此基于我已经理解的部分来进行案例分析。
为了应用数据,我们有以下输入
1.一个数据字典
2.主键定义
3.外键定义
对于这样的大型项目,我们的研究会面临一些困难。回忆一下前两个项目,我们首先将数据库结构自动抽取建模工具,然后开始分析,但是8500张表太多了,不适合手工梳理。我们试着找出那些紧密连接的表,我们期待发现一个更小,但仍然有用的模型。我们假设紧密相连的表是最重要的表。
这里简单介绍一下图像式分析的步骤。首先建立一张反映主键与外键关联的元表,源表中的外键指向目标表中的主键。
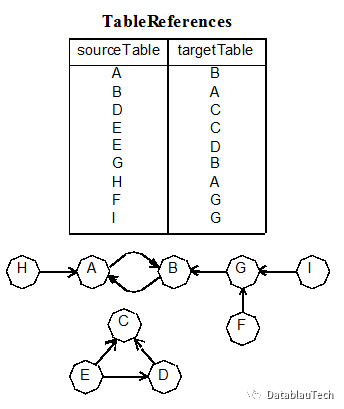
接下来来删除那些拥有0个或1个外键连接的表,从而留下那些拥有多重连接的表。
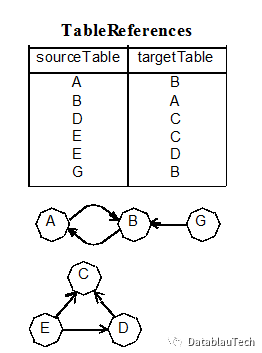
重复进行上述操作,直至表关联结构不再发生变化。
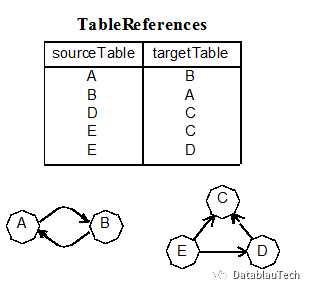
我们使用了以下代码来删减外键很少(0或1)的表,以查找核心表。
DELETE FROM TableReferences AS T3
WHERE EXISTS (
SELECT T1.sourceTable
FROM TableReferences AS T1
WHERE NOT EXISTS (
SELECT *
FROM TableReferences AS T2
WHERE T1.sourceTable = T2.targetTable)
AND T3.sourceTable = T1.sourceTable
GROUP BY T1.sourceTable
HAVING COUNT(*)=1 );
中间的sql短语用于查找具有一个源引用的表。最内层的查询将单源表这一限定条件进一步限制为不是任何其他源的目标的表。外层查询执行删除操作。
在分析之前,该工程拥有8500张表,数千个外键定义,854张表有外键列,254张表通过外键被引用。经过分析计算,最终我们得到了553张核心表。
数据库逆向工程案例4:企业数据模型
经过以上3个案例的分析,相信各位已经对数据库逆向工程有了一定理解。下面介绍基于逆向工程构建企业数据模型的真实案例。
一位客户,是一家金融软件供应商,该供应商是由五家独立的公司融合而成。可想而知,先前的五家公司已有的应用程序是非常不同的,分别由不同的团队建立、运营
。
我们的目标是构建企业数据模型,为企业整合应用程序提供帮助,以帮助新公司加强其品牌价值。我们尝试了完整的逆向工程方法,但是没有得到满意的结果,因为最终的模型是如此的不同于预期。我们接下来尝试了核心逆向工程方法,但模型的结果仍然不能令人意。最后,我们决定对每张表的外键引用进行计数,找到被引用最多的表作为核心实体,这种方式奏效了。
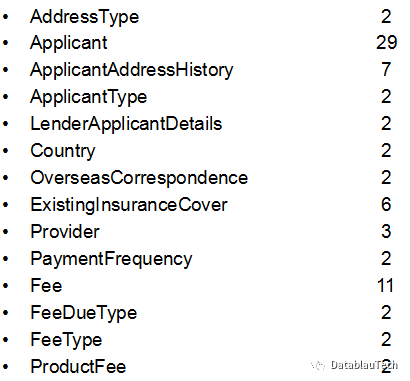
我们一起来看看分析结果。
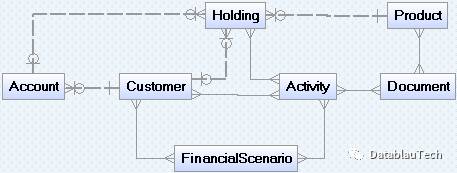

数据库 -- 技术人员视角
数据库架构 --工程师视角
物理数据模型 –架构师视角
逻辑数据模型-- 业务管理视角
概念数据模型 –高管执行层视角
这是非常复杂的企业数据模型梳理的一个实践。
