排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
长文指南 | MEG/EEG信号的时间序列解码
长文指南 | MEG/EEG信号的时间序列解码
鹿鸣Cogn
2021-09-15
6414
按:本文介绍的是Tijl等人关于EEG/MEG时间序列解码(time-resolved decoding)的指南性综述。内容非常全面,相信读完可以对M/EEG时间序列解码和相关的扩展分析从理论上有一个比较清晰的了解。值得收藏~
多变量模式分析
(MVPA)的方法在fMRI研究中已经非常普遍 [参考:
用直观方式理解“多变量模式分析”(MVPA)
],但是在脑电(EEG)或脑磁(MEG)相关的基础研究中的应用还刚起步,本文作者对MVPA(尤其是
解码
decoding)在M/EEG中的应用进行了指南性的介绍。
首先对比一下fMRI和M/EEG的解码方法,fMRI的“多变量”指的是
“多体素”
,也就是在体素空间中观察不同条件下脑活动的模式;相比之下,M/EEG的“多变量”指的是
“多通道”
,如128个电极点就是128个通道。
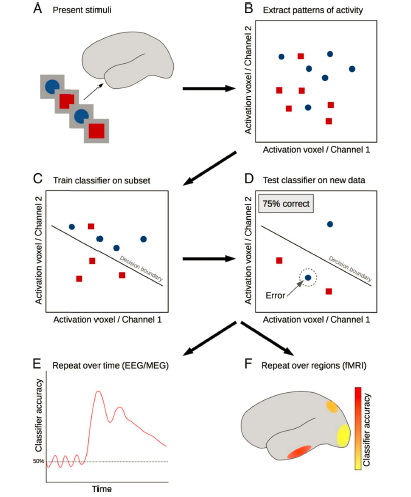
举个最简单的实验例子:让被试分别看
蓝色
和
红色
的物体(图1A),然后观察其脑活动模式。继续用最简化的情况:只观察两个体素(或两个通道)的活动,此时可以将这两个体素(或通道)的活动模式在一个平面中进行表示(图1B)。之后,用机器学习训练
分类器
将这两种条件分开(图1C),然后利用新的数据来测试这个分类器的表现(图1D),如果分类的正确率显著高于随机水平(50%),则可以说明我们观察的这部分脑区能够编码相关的信息(即区分红色和蓝色)。
在高时间分辨率的M/EEG中,我们可以在
每个时间点
都重复上述过程来训练分类器,这就被称为
“时间序列解码”
(time-resolved decoding;图1E),这种方法有助于我们推断大脑表征特定信息的时间动态;如果在fMRI上,我们则可以测试不同感兴趣脑区(ROI)的解码情况(图1F)。
图1 一般性的解码流程:比较fMRI和M/EEG
传统的M/EEG研究中,我们习惯平均叠加信号来得到事件相关活动(如脑电的
ERP
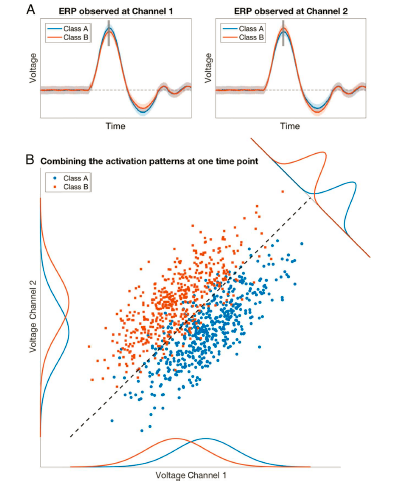
),这种单变量的方法虽然有时同样能够看到效应,但相比多变量解码的方法而言存在一些不足。如图2A所示,我们利用传统方法得到的两个ERP波形表明,两种实验条件在这两个电极点的平均活动强度都是没有区别的。
但是当我们使用多变量的方法(图2B),在二维空间中观察这两个电极点的活动模式,可以发现尽管两种条件下的平均活动没有差异,但是其分布特点很明显是可分离的,可以利用一条直线将两种活动的模式区分开来,即可以解码条件信息。
图2 多变量方法的优势
接下来,
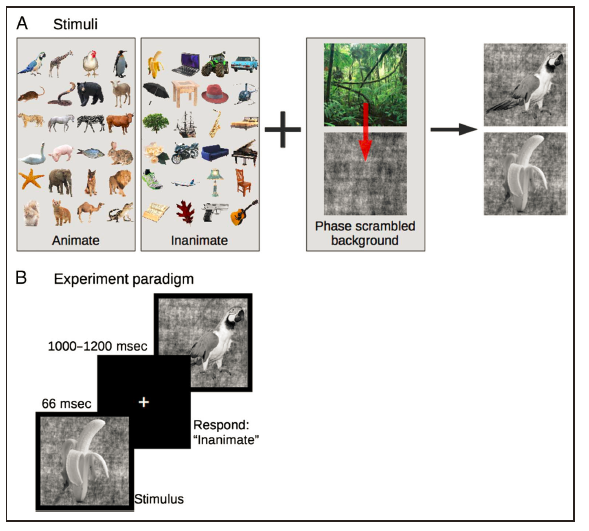
作者利用一个现成的MEG实验例子,来演示如何进行M/EEG的时间序列解码
(要注意这并不是所有分析的标准,只是演示,具体分析细节要根据实际实验设计等情况而定)。这个实验材料是给被试看两种类型的图片(图3),一类是
有生命的
(animate)图片24张,另一类是
无生命的
(inanimate)图片24张;每张图片呈现32次。研究目的是探索被试看不同类型图片时大脑活动是否有差异。
图3 实验材料和范式
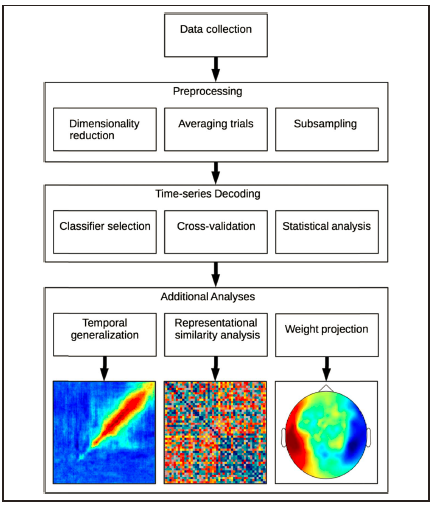
整个分析的流程见图4,主要包括了
预处理
,
时间序列解码
,以及
额外的三种进阶分析
(
跨时域解码、表征相似性分析、权重投射
)。作者在这里也给出了标准流程分析后的时间序列解码的结果图片呈现(图5)。接下来,作者对每一步进行了较详细的介绍。
图
4
分析流程
图
5
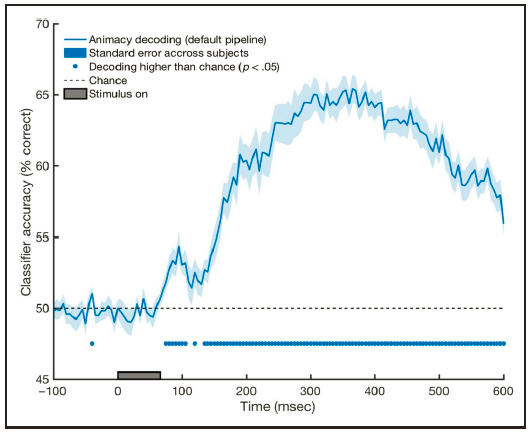
时间序列解码的结果呈现(横坐标是时间,纵坐标是分类正确率,当正确率显著高于50%时就表明在编码条件信息。下方蓝色的点/线表示达到显著的时间点)
1、预处理
预处理的原因简单来说就是提高神经信号的信噪比。
预处理的一个标准步骤是
降维
(dimentionality reduction)。一些分类器要求样本数量多于特征数量,当输入的特征维数过多,训练的分类器会出现过拟合的现象。比如MEG一般有160个以上的记录通道,这就有很多冗余信息,需要对其进行降维。
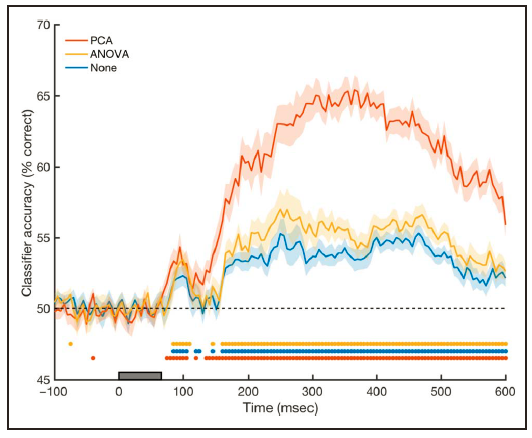
作者主要对比了两种方法对数据进行降维,其一是利用方差分析(ANOVA)找出贡献最大的通道进行分析,其二是使用
主成分分析(PCA)
进行降维。还有一种基于源重建的方法本文未太涉及。结果显示(图6),
PCA降维对分类器的表现提高明显
,未进行降维和利用ANOVA降维的表现不佳。
图
6
不同降维方式对分类器表现的影响
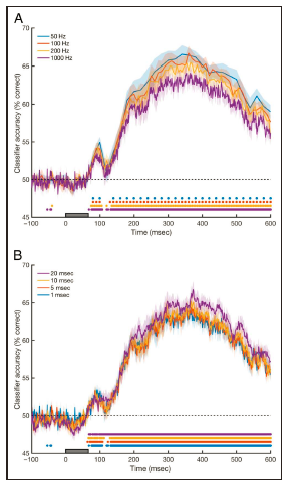
此外,由于MEG原始采样率高,会携带高频噪音。因此可以利用
降采样
(subsampling)或者
滑动窗口的方法
(sliding window approach)来进行改善。这两种方法的区别在于滑动窗口法可以用到每一个点的信息(特征数量增加),而降采样使用的是平均值(每个时间点的特征数不变)。不过对于示例数据而言,两种方法对分类器的表现提高作用都有限(图7),但是降采样比滑动窗口法节约计算时间。
图
7
(A)降采样、(B)滑动窗口法对分类器表现的影响
需要注意的是,在传统EEG研究中我们会对伪迹进行校正(如利用ICA去除眼电和肌电),并对坏导进行插值等操作。但作者认为
这些伪迹剔除步骤在这里的解码分析中并不需要
,因为这些伪迹包含的信息量很少,不会影响分类效果。相反,分类器可以利用噪声信息优化分类结果,这是传统分析所不具备的优势。但是也需要说明,如果这种伪迹在不同条件中具有明显差异,则需要考虑剔除这些伪迹。
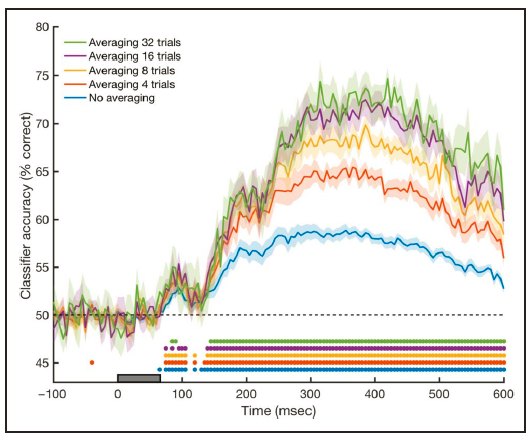
此外,提高信噪比还可以通过在解码之前
平均相同条件的试次
来实现,进行平均会使解码表现提高,且图形特征(最值、起始点等)更加明显。但是平均多少试次是一种
权衡
(trade-off),比如如果我们将32个试次全部平均,相当于每个条件只剩1个试次,这会增加分类器的变异性,不利于分类。在示例数据中,平均4个试次能够达到提高信噪比和保留试次数量最佳的权衡(图8),但对于不同数据,这个数字是会变化的。
图
8
平均不同数量试次对分类器表现的影响
2、解码
总结而言,在预处理过程中,研究者把数据降采样到200 Hz,并根据刺激出现时间将信号从-100ms到600ms进行分段(epoch),同时利用4个试次平均的方法来提高信噪比,即相当于目前每个条件有8个虚拟试次。接下来就进行分类器的训练和测试了。
首先,
分类器有多种不同选择
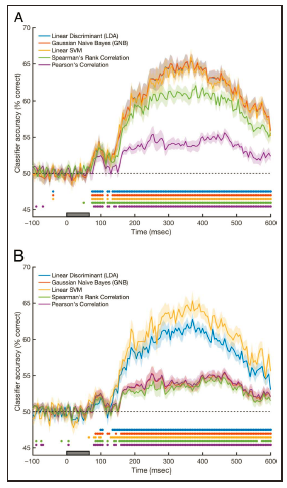
,不同选择会影响分类结果。一般在认知神经科学研究中会选择线性分类器,这一方面是避免过拟合的线性,另一方面是为了使结果便于解释和可视化。常见的分类器有:
支持向量机(SVM)、线性判别法(LDA)、高斯朴素贝叶斯(GNB)
、斯皮尔曼等级相关、皮尔逊相关等(可参考:
R语言机器学习 | 7 支持向量机
;
R语言机器学习 | 6 朴素贝叶斯
;
R语言机器学习 | 4 线性判别分析 (LDA)
)。
作者比较了这些分类器的效果,总体上
SVM、LDA和GNB的效果都不错
(图9)。另外,作者比较了是否降维对这些分类器表现的影响,进一步说明预处理对结果的可能影响。
图
9
不同分类器的表现,上图是标准预处理的数据,下图是没有经过PCA的数据。
分类器的表现需要通过
交叉验证
(cross validation)来评估,一般使用k-fold交叉验证。用一个简单的例子(4-fold)来说明这种方法,如果将样本分为四组,每次用三个组作为训练集,另一组作为测试集,轮流四次之后将四个分类器的正确率平均即可得到总的分类正确率。可见,“k-fold”的k是可以自定的,如果k等于样本数,就是所谓留一法交叉验证(leave-one-out CV)的方法。
交叉验证示意图 (Carlson et al., 2019)
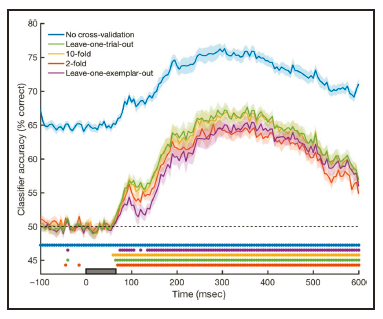
作者在这里比较了不同k对于分类表现的影响,结果发现差异不大(图10)。需要注意的是,
如果没有经过交叉验证,得到的正确率会虚高,且在刺激出现前就显著高于随机水平
,这是因为训练集和测试集不独立导致的。
图
10
不同fold数交叉验证的结果比较
训练完分类器后,要
评估分类效果
,并进行
组水平的统计
(之前的分析都是在单个被试身上进行的)。一般而言,结果会使用
分类正确率
(accuracy)来进行衡量。但对于不平衡的数据(不同组别的trial数差别较大),使用无偏的指标如
辨别力
(d')会更合适,或者将准确率进行平衡也是可以的。
对于检验分类效果是否显著高于机会水平,也有一些常见方法。非参数的
符号秩次检验
是本文用的方法,因为它对数据的分布做了最少的假设。此外,
t检验
也是常用的手段。另一种流行的方法是
置换检验
,这种方法在对零分布没有任何假设的时候特别管用,但是运行时间比较长。
最后自然还要考虑
多重比较问题
(参考:
多重比较问题:为什么fMRI里放条死鱼也能发现脑激活?
),在本文示例中作者使用的是
FDR校正
,但这种方法的局限在于没有包含时间点之间的关系。另一种方法是
cluster-based多重比较校正
,即测试一组时间点是否显著高于概率水平,从而提高对持久但相对较小效应的敏感度。
3、额外的分析
上文已经介绍了M/EEG基于时间序列的解码,之后作者还进一步介绍了三种额外的常用分析。
首先是
跨时域解码
(cross-temporal decoding),这种方法本质是对分类器泛化能力的检验,所以也交
temporal generalization method
。简单而言,
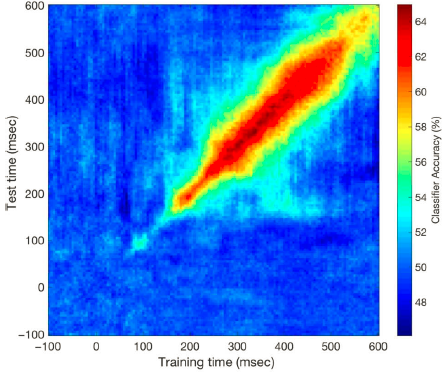
如果在一个时间点上训练的分类器能够成功地对其他时间点数据进行分类时,就表明在这两个时间点上,大脑表征方式是相似的
;反之,这说明表征方式已经发生了变化(即使两个时间点都可以解码条件信息)。所以这种方法很有用,可以观察表征的动态变化。
如图11所示,这就是一个常见的跨时域解码的图片。一般来说,因为对角线上的时间点是一致的,对角线一般都是可预测的。但如果出现了对角线外的显著更高的分类准确率(如图中的150~200ms、300~500ms),则说明在这些时间点上,大脑的表征方式是类似的。
图
11
跨时域解码的示意图
第二种额外分析方法是
表征相似性分析(RSA)
。解码分析揭示了大脑模式是否表征了特定类别的信息。跨时间解码则开始揭示分类器使用的模式信息的底层表征结构。RSA则进一步提供了一个框架,来检验关于信息结构的假设。
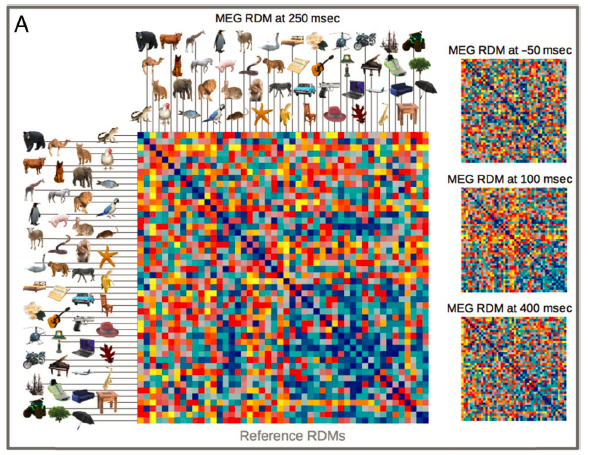
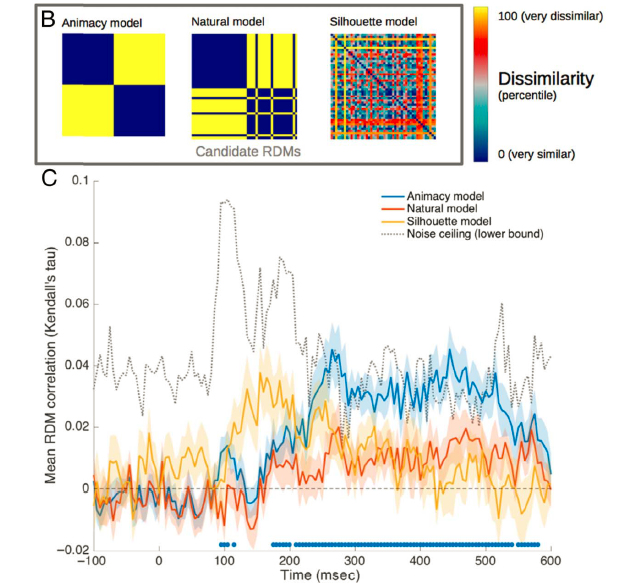
RSA基于这样一个假设,即神经表征越相似的刺激越难解码,差别越大的越好解码。所以RSA的中心思想是通过比较所有可能的成对刺激组合的可解码性(decodability),构建
表征不相似性矩阵
(RDM),如图12A。
图
12 (A)RDM示例。矩阵的每个格子代表两个刺激(行&列)的不相似性;对于高时间精度的MEG,可以在每个时间点计算一系列的RDM,从而探索表征的时间动态。
之后,可以将
实际神经数据的RDM
和
理论假设的RDM
进行拟合,从而验证特定理论假设的正确性。如图12B所示,这里有三个假设模型,第一是大脑表征有生命vs无生命的物体(Animacy模型),第二是表征的天然物体vs人造物体(Natural模型),第三是按照视觉相似性构建的模型。利用相关分析可以画出图12C的曲线,即RSA模型评估。这里的结果表明,Animacy模型比Natural模型表现更好,视觉相似性模型在早期表现较好,因为这反映了早期视觉加工。可见,RSA可以帮助我们评估不同的竞争假设,在“分类”的基础上更进一步。
图
12 (B)理论RDM的构建;(C)模型评估
最后一种分析是
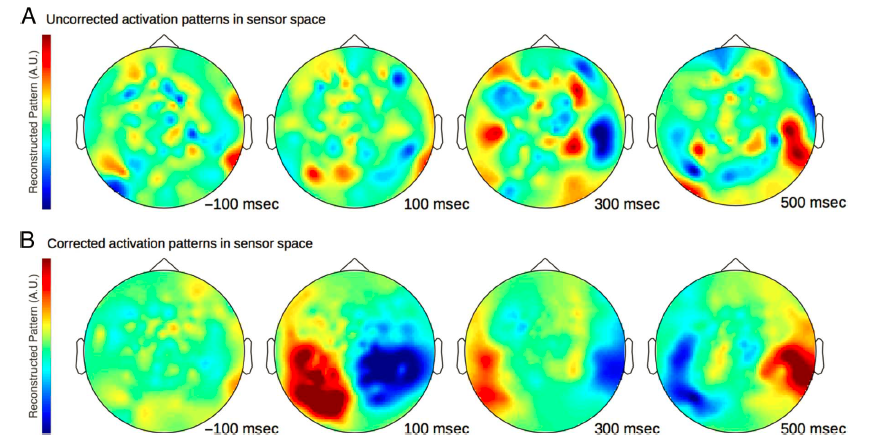
权重投射
(weight projection),简单而言就是想看到底是
哪些脑区(通道)对成功分类做出了更大的贡献
。文章主要介绍了Haufe等人2014年的工作,即通过一定的转换和校正得到权重激活模式。如图13B所示,利用这种方法可以看到随着时间变化,贡献最大的脑区从初级视觉皮层的枕叶逐渐扩散到颞叶区域,提示了随时间动态变化的脑区参与差异。
图
13 分类器的权重投射(上图是未校正的,下图是校正后的)
综上,本文比较详细的介绍了M/EEG时间序列解码的原理,当然原文很长,这里还是择要点来介绍,如果有兴趣可以参见原文。另外,对于代码实现,Matlab或Python都有很好的平台。同时也推荐路同学的推文,可以实现这里提到的绝大多数分析(指路:
免费,完全开源,重新修订 | Python脑电数据处理中文手册
)。
论文原文:Grootswagers, T., Wardle, S. G., & Carlson, T. A. (2017). Decoding Dynamic Brain Patterns from Evoked Responses: A Tutorial on Multivariate Pattern Analysis Applied to Time Series Neuroimaging Data. J Cogn Neurosci, 29(4), 677-697. doi:10.1162/jocn_a_01068
相关阅读:Carlson, T. A., Grootswagers, T., & Robinson, A. K. (2019). An introduction to time-resolved decoding analysis for M/EEG.
感谢支持!欢迎点赞、转发、分享!
数据库
文章转载自
鹿鸣Cogn
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨