




前言
平时工作中主要用 YARN 模式,最近进行TPC测试用到了 Standalone 模式,便记录总结一下 Standalone 集群相关的配置。
集群管理类型
Spark 支持三种集群管理类型:
Standalone - Spark附带的一个简单的集群管理器,可以轻松地设置集群。
Apache Mesos - 一个通用的集群管理器,也可以运行HadoopMapReduce和服务应用程序。(已弃用)
Hadoop YARN - Hadoop 3中的资源管理器。
Kubernetes - 一个用于自动化容器化应用程序的部署、扩展和管理的开源系统。
官方文档:https://spark.apache.org/docs/latest/cluster-overview.html
官方文档
https://spark.apache.org/docs/latest/spark-standalone.html
安装包
因为TPC不支持 Spark3 ,所以用的 Spark2.4.8
https://archive.apache.org/dist/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
安装目录
解压到 opt/spark2
配置
记录主要配置
slaves
配置Worker节点
indata-192-168-1-1.indata.com
indata-192-168-1-2.indata.com
indata-192-168-1-3.indata.com
indata-192-168-1-4.indata.com
indata-192-168-1-5.indata.com
indata-192-168-1-6.indata.com
indata-192-168-1-7.indata.com
indata-192-168-1-8.indata.com
indata-192-168-1-9.indata.com
......
spark-env.sh
export JAVA_HOME=/usr/local/jdk
# export SPARK_LOG_DIR=/var/log/spark
# 设置 NVME 接口可提升性能
export SPARK_LOG_DIR=/indata/nvme_0/log/spark
# export SPARK_PID_DIR=/var/run/spark
# 设置 NVME 接口可提升性能
export SPARK_PID_DIR=/indata/nvme_0/run/spark
export HADOOP_HOME=${HADOOP_HOME:-/usr/hdp/3.1.0.0-78/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/usr/hdp/3.1.0.0-78/hadoop/conf}
# ssh端口
export SPARK_SSH_OPTS="-p 6233"
# Worker 的内存,默认使用节点总内存
export SPARK_WORKER_MEMORY=400G
# Worker 的 CPU 核数,默认使用节点总CPU数
#export SPARK_WORKER_CORES=100
export SPARK_DAEMON_JAVA_OPTS="-XX:+UseG1GC -XX:+PrintFlagsFinal -verbose:gc -XX:+PrintGCDetails -XX:+UseAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions"
## History Server UI 端口
export SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.ui.port=8080"
## 自定义添加配置,后面修改启动slave脚本时会用到
export HOST_NAME=`hostname -f`
# 设置NVME 接口可提升性能
export SPARK_WORKER_DIR=/indata/nvme_0/spark/work
export SPARK_LOCAL_DIRS=/indata/nvme_0/spark/tmp
start-slave.sh
修改 start-slave.sh,将
--webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@"
改为
--webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER -h "${HOST_NAME}"
这样修改的原因是默认情况下读取HDFS时数据本地性(Locality Level)都是 Any。原因是Spark 中 Worker Id和Address中都使用的IP地址作为Worker的标识,而HDFS集群中一般都以hostname作为slave的标识,这样,Spark从 HDFS中获取文件的保存位置对应的是hostname,而Spark自己的Worker标识为IP地址,两者不同,因此没有将任务的Locality Level标记为NODE_LOCAL,而是ANY。
历史服务 HistoryServer
官方文档:https://spark.apache.org/docs/latest/monitoring.html
开启历史服务,可以通过UI界面监控分析已经跑完的历史任务,便于我们分析及时发现和解决性能瓶颈。(在性能测试时,我们可以先开启历史服务,当调到最优参数时,可以先把历史服务相关的配置关掉,这样也许可以提升些许性能。)
在 spark-defaults.conf 中配置
客户端(Spark应用程序)
spark.eventLog.dir hdfs:///spark-history/
spark.eventLog.enabled true
通过上面的两个配置,运行Spark 程序时会将UI中显示的信息进行编码然后持久化存储中,存储路径为 hdfs:///spark-history/
服务端
# 只需要这一个参数即可正常使用,需要和客户端路径一致,其他参数属于调优,根据实际情况配置
spark.history.fs.logDirectory hdfs:///spark-history/
spark.history.store.path /var/lib/spark/shs_db
spark.history.fs.cleaner.enabled true
spark.history.fs.cleaner.interval 7d
spark.history.fs.cleaner.maxAge 90d
#spark.history.ui.acls.enable false
#spark.history.ui.admin.acls yarn,spark,hdfs,hbase,hive
#spark.history.kerberos.enabled
#spark.history.kerberos.keytab
#spark.history.kerberos.principal
#...
需要提前创建文件夹 hdfs:///spark-history/
环境变量
vi /etc/profile.d/spark.sh
export SPARK_HOME=/opt/spark2
export PATH=$SPARK_HOME/bin:$PATH
source /etc/profile.d/spark.sh
传输到其他节点
配置完成后将整个 spark 文件夹传输到其他节点相同目录下,保证每个节点配置相同
启动
sbin/start-all.sh
sbin/start-history-server.sh
Spark master和 history server可以在不同节点。比如master的默认端口是8080,而我配置history server的端口也是8080。这是因为我们环境做了端口限制,只开放了有限的几个端口。这样利用不同节点的8080端口既可以访问master UI也可以访问 history server UI。
停止
sbin/stop-all.sh
sbin/stop-history-server.sh
UI 界面
UI 默认端口及其对应配置参考官网:https://spark.apache.org/docs/latest/security.html
Spark Master
Spark master UI界面 默认端口 8080,可以通过 SPARK_MASTER_WEBUI_PORT (spark-env.sh) 和 spark.master.ui.port (spark-defaults.conf)修改,其中 spark.master.ui.port 优先级最高,具体逻辑在源码:org.apache.spark.deploy.master.MasterArguments
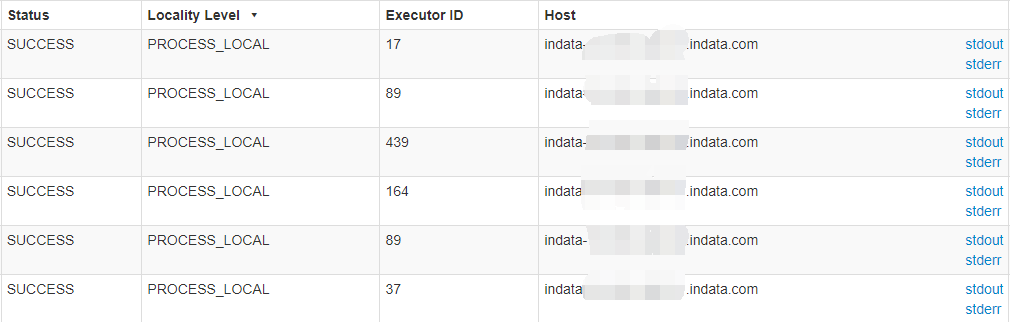
这里对比一下上面说的数据本地性
默认启动脚本:
Worker Id和Address中都使用的IP地址作为Worker的标识
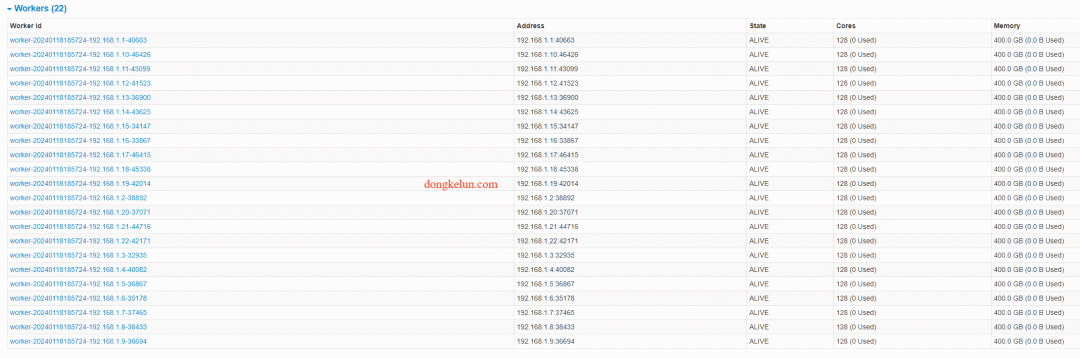
造数阶段是正常的PROCESS_LOCAL
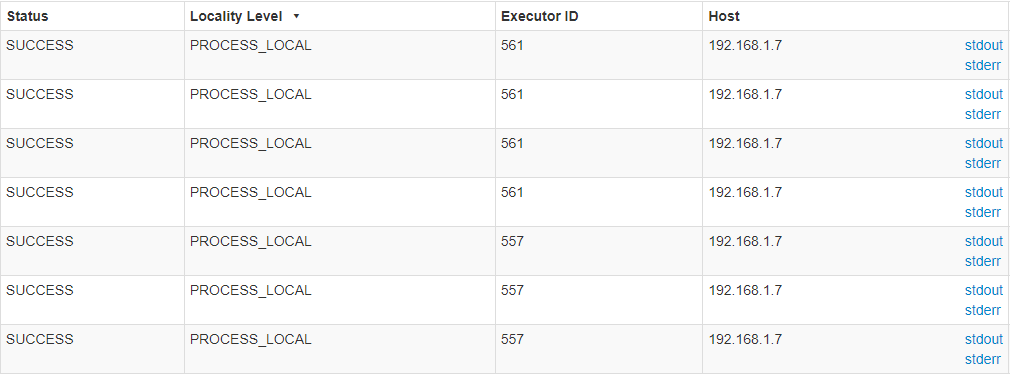
但是读取HDFS数据阶段都是ANY
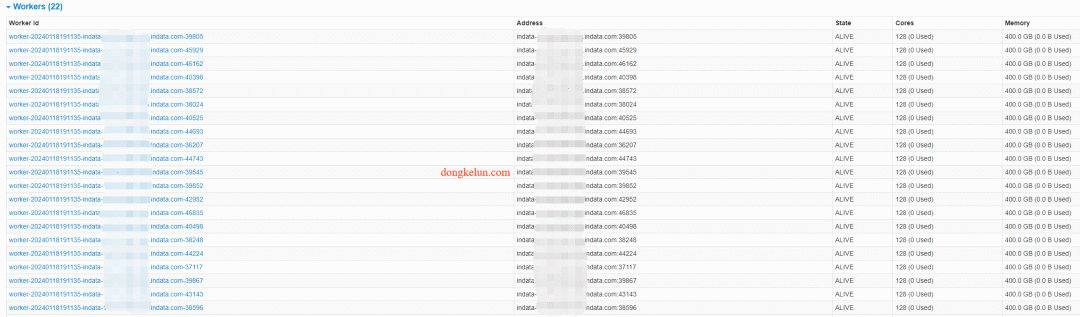
修改启动脚本后:
Worker Id和Address中改为使用hostname作为Worker的标识
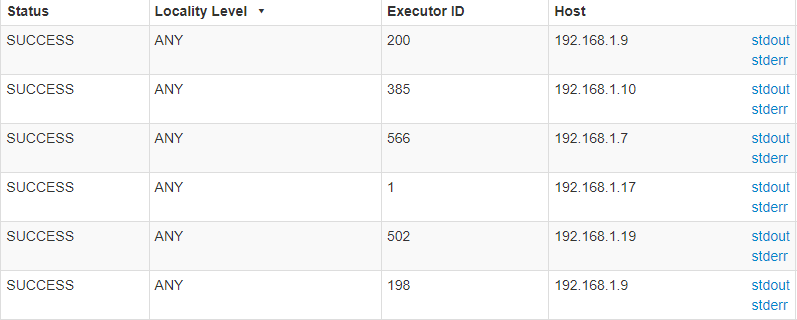
读取HDFS数据时改为正常的PROCESS_LOCAL
Spark Worker
默认端口 8081,可以通过 SPARK_WORKER_WEBUI_PORT (spark-env.sh) 和 spark.worker.ui.port (spark-defaults.conf)修改,其中 spark.worker.ui.port 优先级最高,具体逻辑在源码:org.apache.spark.deploy.worker.WorkerArguments
Application
默认 4040,可以通过 spark.ui.port 修改
Spark History Server
默认端口 18080,可以通过 spark.history.ui.port 修改。(在spark-env.sh 中通过 SPARK_HISTORY_OPTS 配置,在spark-defaults.conf 配置不生效)

Standalone 对比 YARN
优点
1、提交时间短,在TPC测试打榜时差几秒差距就很大。
2、可以单独配置每个节点的CPU核数和内存大小,比较灵活。比如对于HDFS NAME NODE 节点,可能HDFS用的 CPU 和 内存相比其他节点要多,这样剩余可用资源就会少一些。我们可以单独修改对应节点上的 spark-env.sh 。比如将内存改为360G:export SPARK_WORKER_MEMORY=360G。因为我们集群配置比较充足,有22个节点,每个节点的内存有512G,分给Spark的只有400G(仅示例,非实际测试配置;测试数据量只有1T,远小于集群总内存),剩下100G给HDFS足够了, 所以不用单独配置。而对于资源不充足的集群,这样配置也许能提升性能。
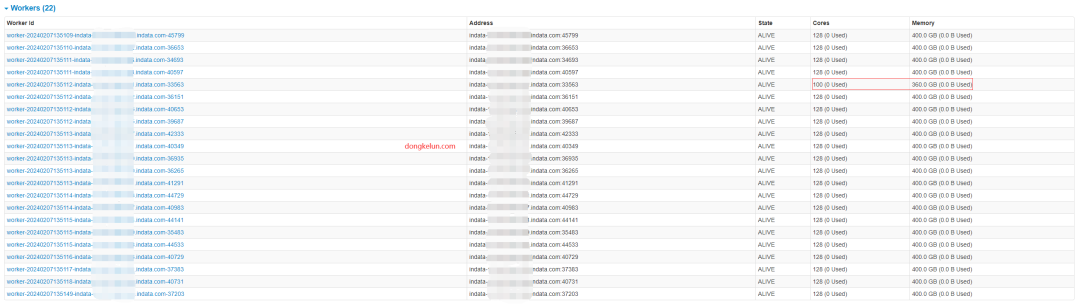
不同
通过参数 spark.executor.instances 或者 --num-executors
来配置程序的 executor 的数量是不管用的。Standalone 模式下 executor的数量 是看 CPU 和 内存哪个先到上限决定的,也就是默认情况下,根据先进先出顺序,尝试使用集群所有可用的资源。
executor_num = min(SPARK_WORKER_MEMORY/spark.executor.memory, SPARK_WORKER_CORES/spark.executor.cores)。另外可以通过 spark.cores.max 配置程序的最大cpu数,即 executor_num = spark.cores.max/spark.executor.cores,严格说 executor_num = min(SPARK_WORKER_MEMORY/spark.executor.memory, min(SPARK_WORKER_CORES, spark.cores.max)/spark.executor.cores)。还可以通过 spark.deploy.defaultCores 来设置没有配置 spark.cores.max 的应用程序的默认值。
缺点
不支持kerberos认证等
TPC测试结果
恭喜我们团队(InspurCloud Data Cloud Platform)在 TPCx-HS 1T 测评 中取得第一名的好成绩,后面还会继续进行 TPCx-BB 和 TPCx-HS 3T 的测评打榜。

🧐 分享、点赞、在看,给个3连击呗!👇
