




原作者:Volodymyr Mnih et al.
中文摘要:
我们提出了第一个使用强化学习直接从高维感官输入中学习控制策略的深度学习模型。该模型是一个卷积神经网络,用一个Q learning的变体训练,输入为原始像素,输出为估计未来回报的价值函数。我们将我们的方法应用于七个来自街机学习环境的Atari2600游戏,而不需要调整架构或学习算法。我们发现,它在六个游戏中的表现超过了之前所有的方法,并且在其中三个游戏中超过了人类专家。
英文摘要:
We present thefirst deep learning model to successfully learn control policies directly from high-dimensionalsensory input using reinforcement learning. The model is a convolutional neuralnetwork, trained with a variant of Q-learning, whose input is raw pixels andwhose output is a value function estimating future rewards. We apply our methodto seven Atari 2600 games from the Arcade Learning Environment, with noadjustment of the architecture or learning algorithm. We find that itoutperforms all previous approaches on six of the games and surpasses a humanexpert on three of them.
文献总结:

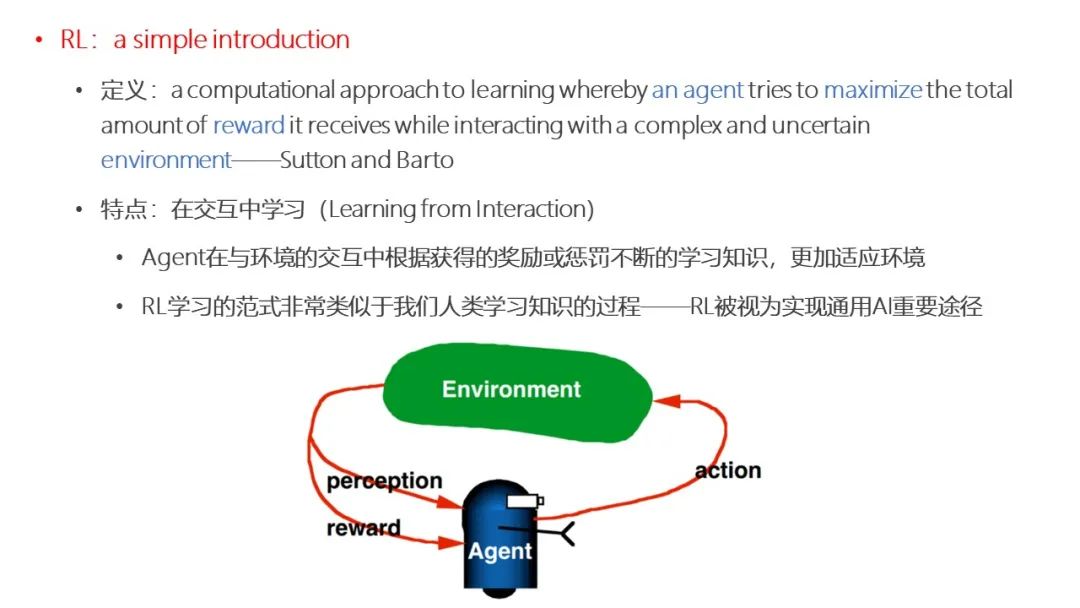






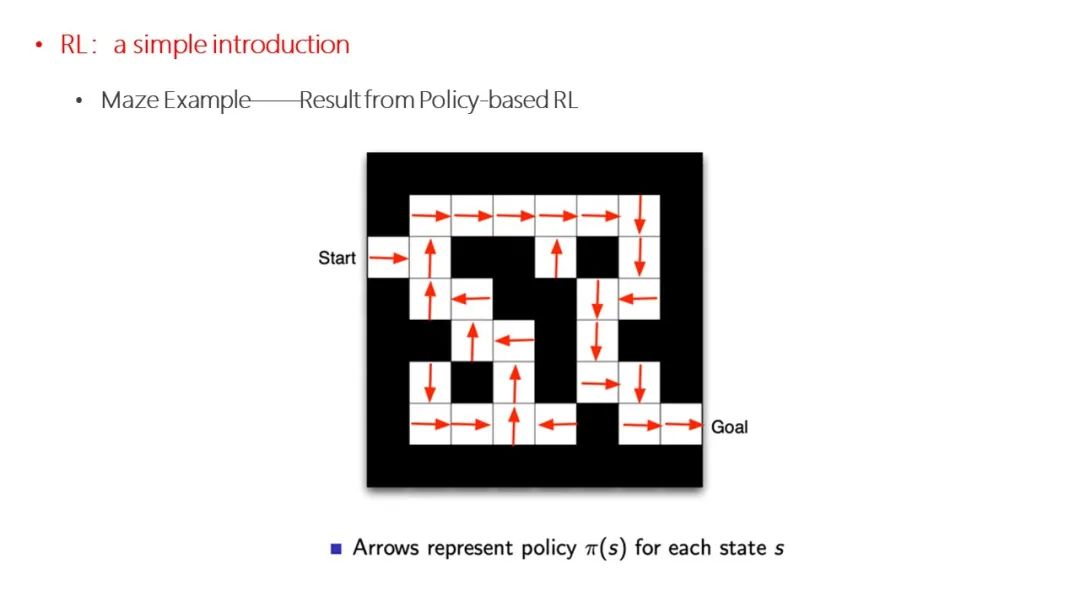
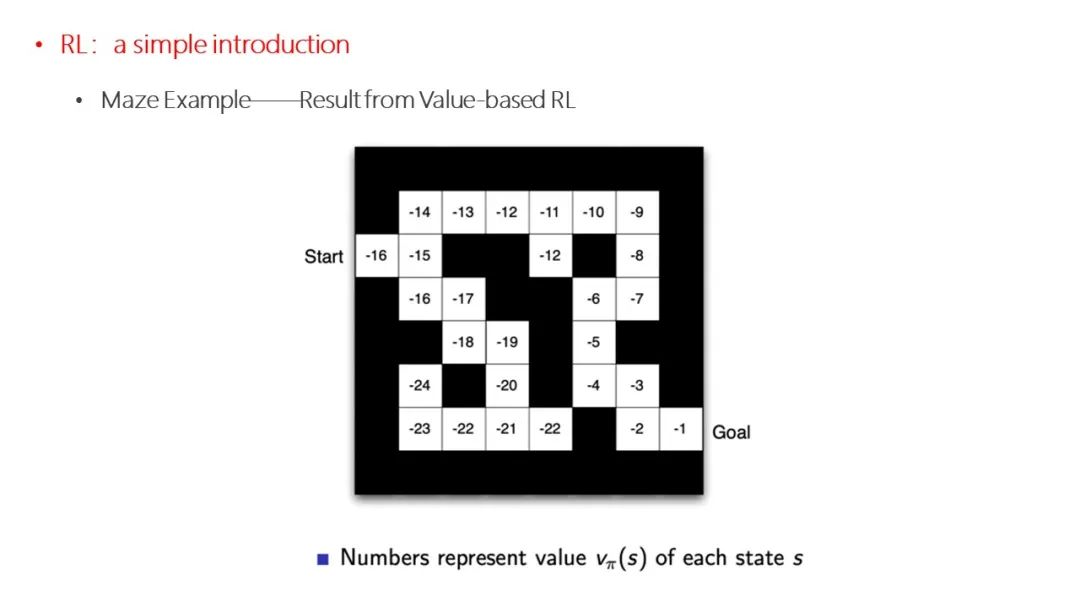









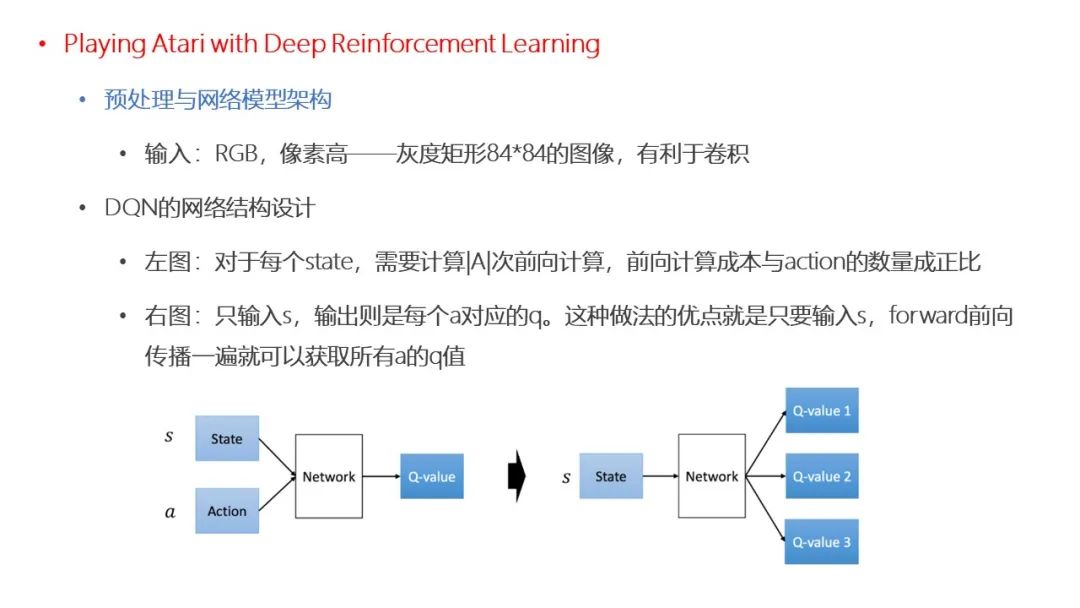
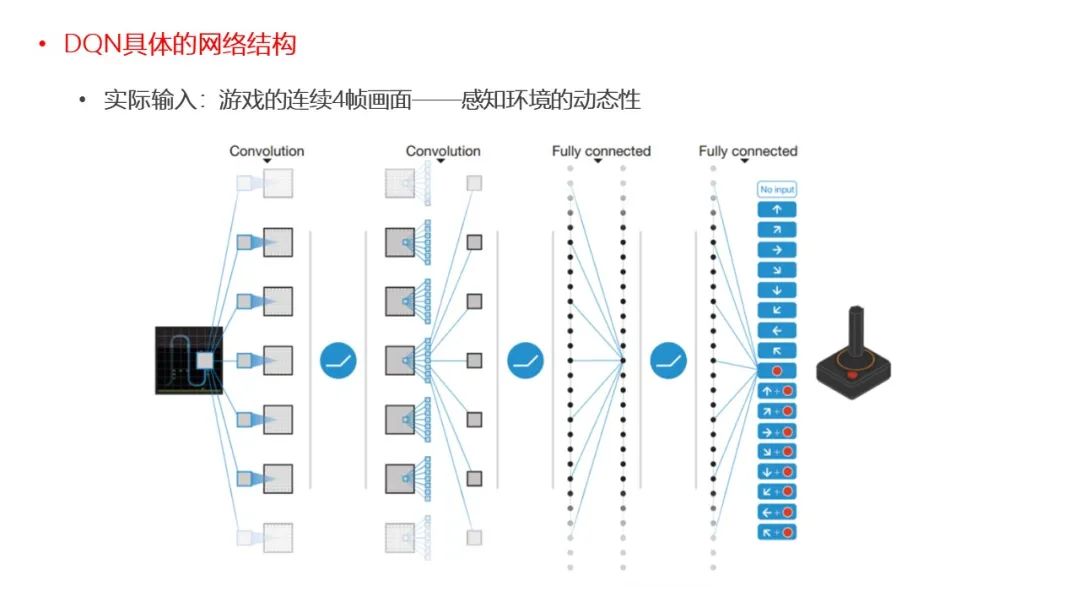

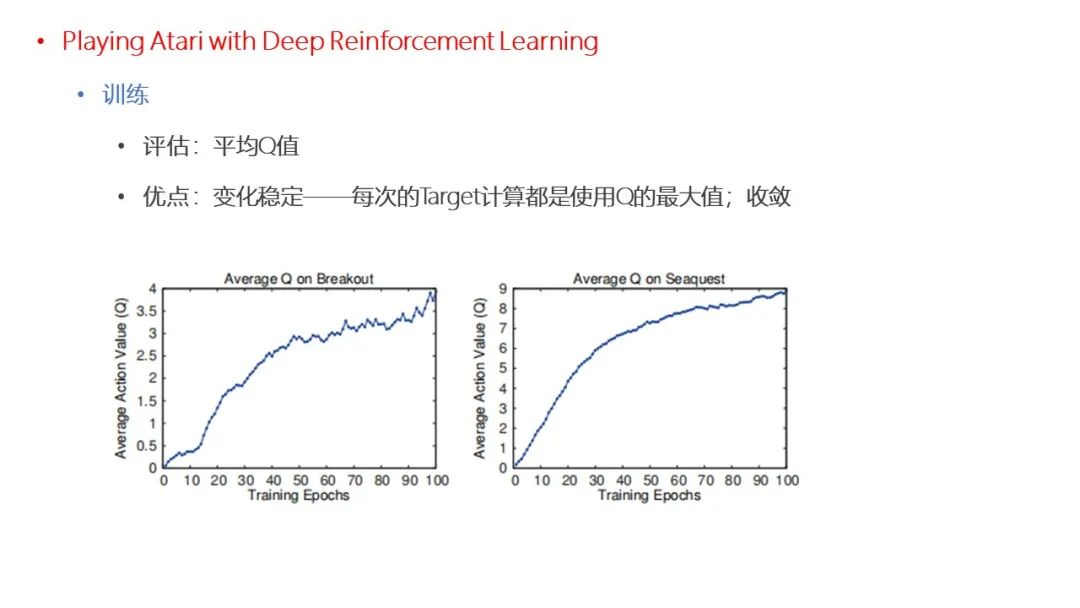


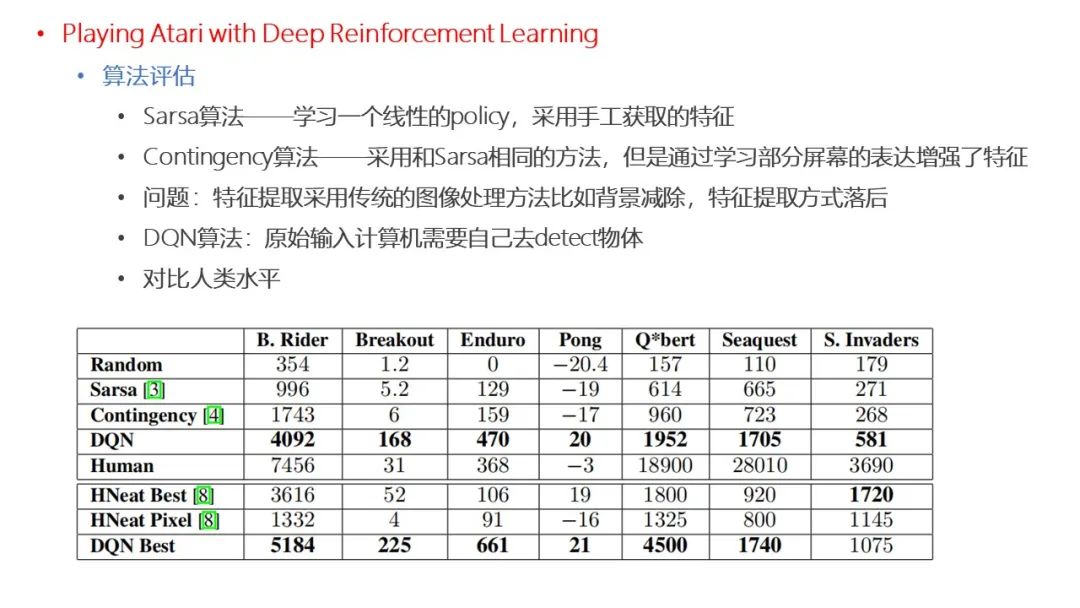

点击“阅读原文”,了解论文详情!
