




原标题:Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
作者:Shuai Li, Wanqing Li, Chris Cook, Ce Zhu, Yanbo Gao
原文链接:https://arxiv.org/abs/1803.04831
中文摘要:递归神经网络(RNN)已被广泛用于处理顺序数据。但是,由于众所周知的梯度消失和爆炸问题,RNN通常很难训练,并且很难学习长期模式。开发了长短期记忆(LSTM)和门控循环单元(GRU)来解决这些问题,但是使用双曲线正切和S型作用函数会导致层上的梯度衰减。因此,构建有效可训练的深度网络具有挑战性。此外,RNN层中的所有神经元都纠缠在一起,其行为难以解释。为了解决这些问题,本文提出了一种新型的RNN,称为独立递归神经网络(IndRNN),其中同一层中的神经元彼此独立并且跨层连接。我们已经表明,可以轻松调节IndRNN,以防止梯度爆炸和消失的问题,同时允许网络学习长期依赖关系。此外,IndRNN可以与非饱和激活功能(例如relu(整流线性单元))一起使用,并且仍需经过严格培训。可以堆叠多个IndRNN,以构建比现有RNN更深的网络。实验结果表明,所提出的IndRNN能够处理非常长的序列(超过5000个时间步长),可用于构建非常深的网络(实验中使用的21层),并且仍然经过严格训练。与传统的RNN和LSTM相比,使用IndRNN可以在各种任务上实现更好的性能。
英文摘要:Recurrent neural networks (RNNs) have been widely used for processing sequential data. However, RNNs are commonly difficult to train due to the well-known gradient vanishing and exploding problems and hard to learn long-term patterns. Long short-term memory (LSTM) and gated recurrent unit (GRU) were developed to address these problems, but the use of hyperbolic tangent and the sigmoid action functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep network is challenging. In addition, all the neurons in an RNN layer are entangled together and their behaviour is hard to interpret. To address these problems, a new type of RNN, referred to as independently recurrent neural network (IndRNN), is proposed in this paper, where neurons in the same layer are independent of each other and they are connected across layers. We have shown that an IndRNN can be easily regulated to prevent the gradient exploding and vanishing problems while allowing the network to learn long-term dependencies. Moreover, an IndRNN can work with non-saturated activation functions such as relu(rectified linear unit) and be still trained robustly. Multiple IndRNNs can be stacked to construct a network that is deeper than the existing RNNs. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (21 layers used in the experiment) and still be trained robustly. Better performances have been achieved on various tasks by using IndRNNs compared with the traditional RNN and LSTM.
论文总结:
RNN在动作识别,语言处理,机器翻译,情感分析等问题中已经获得了广泛的应用,并且效果显著。但是RNN也存在一些问题。由于梯度消失和梯度爆炸问题,导致普通RNN通常很难训练,并且很难学习长期模式。长短期记忆(LSTM)和门控循环单元(GRU)引入了门单元来解决这些问题,但是它们都使用tanh和sigmoid函数作为激活函数,这会导致层上的梯度衰减。因此,构建有效可训练的深度网络具有挑战性。并且RNN中的隐藏单元都相互作用,这就使得解释隐藏单元的行为变得困难。
本文提出了一种新型的循环神经网络-独立循环神经网络(IndRNN)。在IndRNN中,循环输入用 Hadamard 乘积处理为:
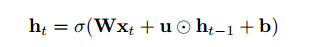
其中递归权重u是向量,而 代表Hadamard乘积。每一层中的每个神经元都彼此独立,并且神经元之间的连接可以通过堆叠两层或多层IndRNN来实现。对于第n个神经元,隐藏状态可以通过下式获得:
代表Hadamard乘积。每一层中的每个神经元都彼此独立,并且神经元之间的连接可以通过堆叠两层或多层IndRNN来实现。对于第n个神经元,隐藏状态可以通过下式获得:
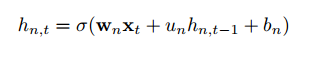
每一个隐藏状态只从它的当前输入以及上一个时间步中的该隐藏状态中接收信息。也就是说,每一个神经元独立的处理一种类型的时空模式。不同神经元之间的相关性可以通过堆叠多层网络来实现。在这种情况下,下一层的神经元处理上一层所有神经元的输出。
IndRNN中的反向传播:
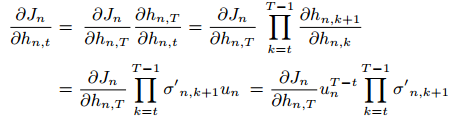
这里忽略了偏差bn。可以看出,梯度仅涉及易于调节的标量值un的指数项,而激活函数的梯度通常限制在一定范围内。为了解决梯度消失和梯度爆炸问题,只需要将下面这个式子调整到适当的范围:
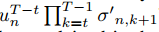
即:
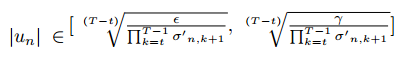

对于relu激活函数,其导数小于等于1,并且考虑到短期记忆对于网络的性能也很重要,上述约束条件可以放宽到:
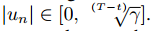
当递归权重为0时,神经元仅使用当前输入的信息,而不会保留过去的任何内存。此处提出的调节原则上将梯度保持在适当的范围内,而不会影响通过该神经元反向传播的梯度。
IndRNN架构
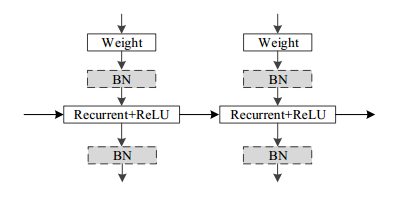
IndRNN 基本架构如图所示,其中「weight」和「Recurrent+ ReLU」表示以 relu 作为激活函数的每个步骤的输入处理和循环处理。通过堆叠此基本架构,可以构建深度 IndRNN 网络。
实验
(1)加法问题。输入为两个序列,seq1是一串(0,1)之间的数字,seq2是同等长度的数值为0/1的一串数字,并且只有两个数字为1,要求数输出与seq2中两个数字1对应的seq1中的两个数字的和。实验的序列长度为100,500,1000。用均方误差作为目标函数。实验结果如下图:
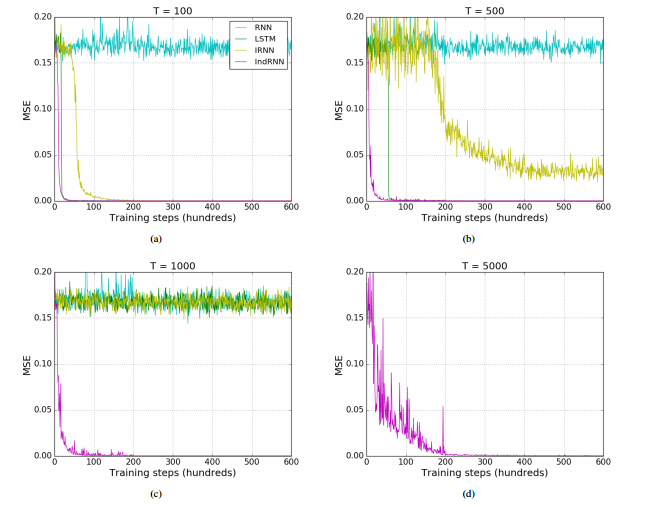
从图中可以看出,对于短序列(T = 100),大多数模型(具有tanh的RNN除外)表现良好,因为它们都收敛到很小的误差。当序列长度增加时,IRNN和LSTM模型难以收敛,而当序列长度达到1000时,只有本文IndRNN仍然可以很快收敛到一个小的误差。为了进一步评估IndRNN模型的长期记忆,文章对长度为5000的序列进行了实验,可以看出,IndRNN仍然可以很好地对其进行建模。这表明IndRNN可以有效解决随时间变化的梯度爆炸和消失问题,并保持长期记忆。
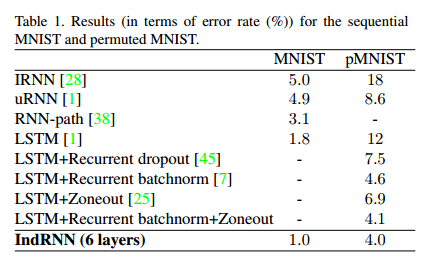
(2)顺序MNIST分类问题。使用六层IndRNN,每层有128个神经元。为了加快训练速度,在每层之后插入批量归一化。表中数据显示,IndRNN性能优于现有的RNN模型。
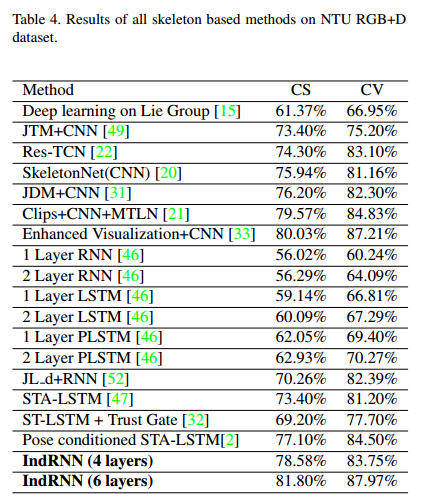
(3)动作识别。使用NTU RGB + D数据集进行基于骨骼的动作识别。分别测试了具有512个隐藏神经元的四层IndRNN和六层IndRNN。批次大小为128,并且使用Adam优化,初始学习率为2 * 10-4,一旦评估精度不增加,就降低10。在每个IndRNN层之后应用Dropout 。实验结果如下表。
结论
在本文提出了一个独立的递归神经网络(IndRNN),其中一层中的神经元彼此独立。解释了IndRNN通过时间过程的梯度反向传播,并开发了一种调节技术来有效解决梯度消失和爆炸问题。与现有的RNN模型(包括LSTM和GRU)相比,IndRNN可以处理更长的序列。基本的IndRNN可以堆叠以构建深度网络,尤其是与层上的剩余连接结合使用时,可以对深度网络进行可靠的训练。此外,每一层神经元之间的独立性可以更好地解释神经元。在多个基本任务上的实验已经证明了所提出的IndRNN优于现有RNN模型的优势。
