




原文题目:
Understanding Hidden Memories of Recurrent Neural Networks
原文链接:
https://ieeexplore.ieee.org/document/8585721
摘要:Recurrent neural networks (RNNs) have been successfully applied to various natural language processing (NLP) tasks and achieved better results than conventional methods. However, the lack of understanding of the mechanisms behind their effectiveness limits further improvements on their architectures. In this paper, we present a visual analytics method for understanding and comparing RNN models for NLP tasks. We propose a technique to explain the function of individual hidden state units based on their expected response to input texts. We then co-cluster hidden state units and words based on the expected response and visualize co-clustering results as memory chips and word clouds to provide more structured knowledge on RNNs’ hidden states. We also propose a glyph-based sequence visualization based on aggregate information to analyze the behavior of an RNN’s hidden state at the sentence-level. The usability and effectiveness of our method are demonstrated through case studies and reviews from domain experts.
这篇文章是一篇关于RNN解释的文章,这篇文章和前面一篇关于LSTMVis的文章类似,也是开发了一个解释RNN隐藏状态的可视化系统。
RNN解释的挑战:
首先,RNN维护类似于内存的数组,称为隐藏状态,该数组存储从长输入序列中提取的信息,例如,文本或音频。当进来一个输入时,将使用由数百万个参数指定的非线性函数来更新数百或数千个隐藏状态单元。隐藏状态和参数的大小给分析RNN的行为带来了困难。随着模型变得越来越复杂,参数的数量将进一步增加。其次,RNN主要处理顺序数据,例如文本和音频。嵌入文本中的复杂顺序规则(例如语法,语言模型和社交语言代码)本质上难以解释和分析。第三,隐藏状态中的语义信息是高度分布的,即每个输入词通常都会导致几乎每个隐藏状态单元的变化。类似地,每个隐藏状态单元可以高度响应一组单词。隐藏状态单元和单词之间的多对多关系进一步阻碍了研究人员理解RNN隐藏状态中嵌入的信息。
针对以上问题,文章作者开发了一个称为RNNVis的通用视觉分析系统,供深度学习从业人员理解和诊断RNN并探索其隐藏记忆的行为。受卷积神经网络启发,文章引入了一种技术,该技术使用来自输入空间的每个高度相关的词来解释每个隐藏状态单元的功能。在给定单词作为输入的情况下,使用隐藏状态单元的预期更新来测量隐藏状态单元与单词之间的相关性。为了了解RNN中隐藏状态单元的功能是如何组合在一起的,文章将隐藏状态和单词之间的关系建模为二部图,其中隐藏状态单元和单词被视为通过加权边连接的两种类型的节点。为了对具有大量隐藏状态的RNN进行可扩展的可视化分析,文章将二部图安排到多个共聚体中。然后,将隐藏状态簇和单词簇可视化为存储芯片和单词云,以便于探索和分析。基于共簇可视化,使用隐藏状态的聚合统计信息,通过基于字形的可视化检查RNN的语句级行为。还提供了丰富的交互功能,供用户探索和比较不同模型的隐藏行为。
系统需求分析
R1:清楚地解释隐藏状态捕获的信息。
R2:提供隐藏状态下的整体信息分布。
R3:在序列级别探索隐藏状态机制。
R4:检查各个隐藏状态的详细统计信息。
R5:比较模型的学习结果。
系统设计
对于一个softmax输出
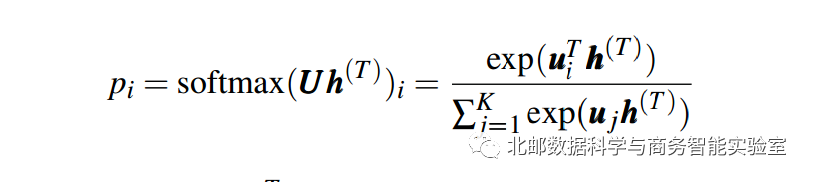
文章首先将分子分解为因子乘积(h(0)=0)
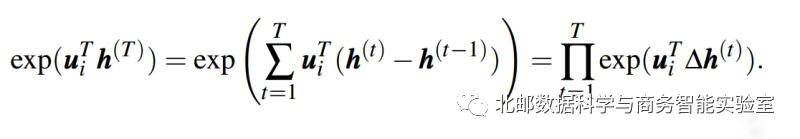
在这个式子中:
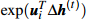 :可以解释为单词t对于类别i的预测概率的乘积贡献
:可以解释为单词t对于类别i的预测概率的乘积贡献
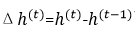 :可以解释为模型对于输入词t的响应值,即模型的隐藏状态受到输入单词的影响程度。t时步隐藏状态向量h(t)受到h(t-1)和x(t)的影响,所以Δh(t)受到h(t-1)和x(t)的影响,当给定单词x(t)时,就可以根据h(t-1),利用下面这个式子来求Δh(t)的期望:
:可以解释为模型对于输入词t的响应值,即模型的隐藏状态受到输入单词的影响程度。t时步隐藏状态向量h(t)受到h(t-1)和x(t)的影响,所以Δh(t)受到h(t-1)和x(t)的影响,当给定单词x(t)时,就可以根据h(t-1),利用下面这个式子来求Δh(t)的期望:
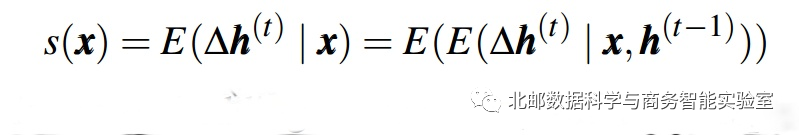
当数据量足够大和好的时候就可以下面这个式子来估计期望反应值。
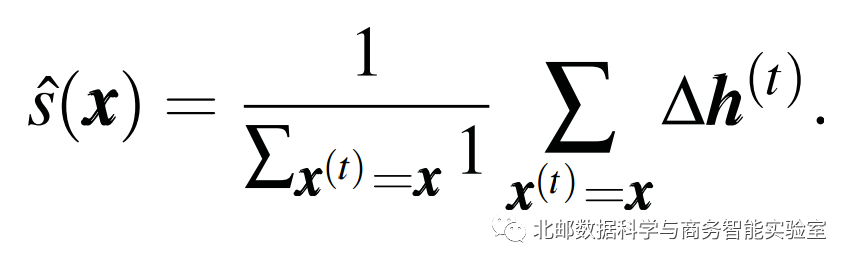
建立二分图
通过前面的式子计算出每一个隐藏状态对每一个单词的响应值,然后建立一个二分图来表示多对多关系:
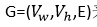
其中
 :词节点的集合
:词节点的集合
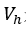 :隐藏状态节点的集合
:隐藏状态节点的集合
E:加权边,表示隐藏状态对词的期望反映值。
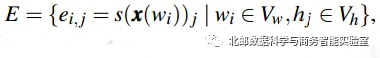
对于这么多条边建立的二分图,并不能分析出有效的信息。所以作者使用谱聚类方法将所有word聚类成word cluster,将所有hidden state聚类为hidden state cluster,聚类后word cluster和hidden state cluster的边的值为加权平均:
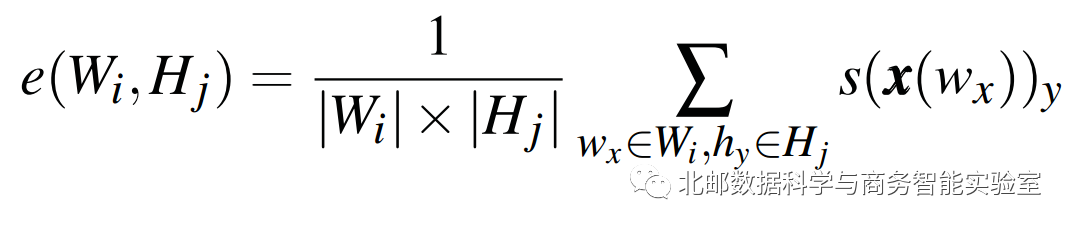
序列分析
所有隐藏状态被聚类为p个隐藏状态簇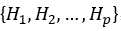
对于t时步,
Hi的整合信息定义为:
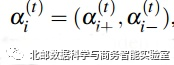
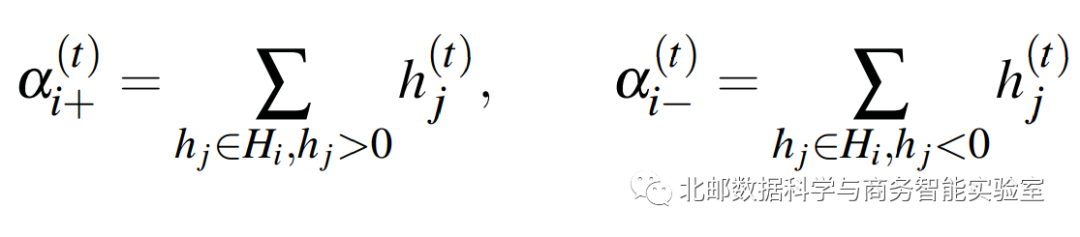
更新信息
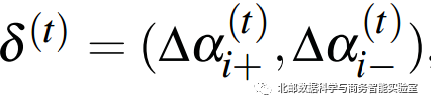
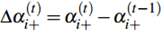
保留信息
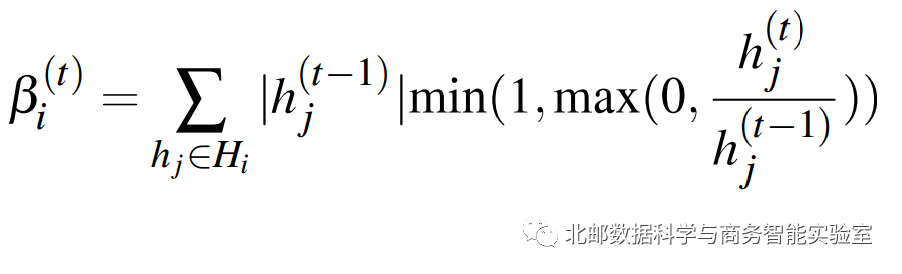
序列分析的目的就是想查看,当进来一个单词t时,一个hidden state cluster更新了多少信息,保留了多少信息。由此可以查看该单词对于这个hidden state cluster的影响程度。
RNNVis系统

A:用户可以选择想要分析的模型以及该模型的具体参数设置,比如对于一个lstm模型,是想分析记忆单元还是隐藏状态单元,隐藏层的数量,是否打开磁性标签,聚类的数量等信息。
D:是聚类的word cluster,一个长方形是一个wordcluster。其中单词的大小与该词向量到这个word cluster中心的欧式距离有关,距离中心越近就会显示的越大,表示这个词越能代表这个word cluster的特征。颜色表示词性,系统给出了词性标签。从颜色可以大致看出,一个word cluster的单词基本上都是一种词性。
C:一个长方形表示一个hidden statecluster,里面的小块代表的是hidden state,当D中一个词被选中以后,与之相关的隐藏状态的颜色表示期望反应值的大小,橘色代表正,蓝色代表负。
C-D的边表示hidden statecluster对于word cluster的响应值,值越大边越粗。同样,蓝色边表示负,橘色边表示正
B:块的顺序与C中hidden statecluster的顺序一致。每个粗线框表示整合信息,上面是正下面是负,粗线框外面彩色的表示更新信息,橘色表示正涨负减,蓝色反之。上面的流线表示保留信息
E:上面的图代表word对每个hiddenstate的期望反应值对比,将hidden state按照对一个word的值排序,这样横轴就有了,其他word的值直接在上面画。下面的图就反过来了,代表一个hidden state对相关word的反应值。上(1 word->n hidden state),下(1 hiddenstate->n word)。
语言模型
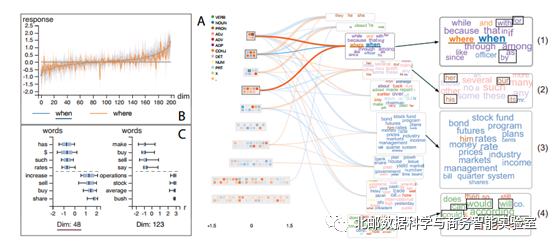
这是一个语言模型的例子,从这幅图中可以大致看到,相同功能的词聚在一起,从词的颜色也可以大致看出来。比如介词“with”,“for”,“by”,“as”被分到word cluster 1中,情态动词“would”,“could”,“should”被聚类到word cluster 4中。
在点击了word cluster 1之后,突出显示了第一个和第四个隐藏状态簇,可以认为第一个和第四个隐藏状态簇能够捕获介词的信息。从B部分可以看到,隐藏状态对于相似词响应大致相似,表明模型可以捕获相似词的功能。图C表示,用户可以选择自己感兴趣的隐藏单元进行探索。
普通RNN与LSTM比较
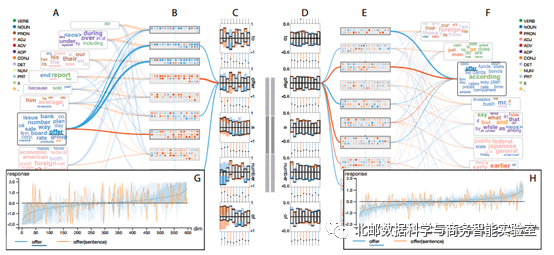
A-B之间的线条比E-F之间的线条更粗,说明普通RNN中隐藏状态对于词的反应值更高。
C中带颜色的条比D中带颜色的条更高,说明RNN更新隐藏状态比较多。LSTM在更新隐藏状态方面的惰性可能有助于它长期存储。再对比图G、H,H更加稳定。这些就解释了LSTM可以更好的处理长期依赖性。
