





PART 01
为什么需要在线创建索引
在关系型数据库中通常会在表上创建索引来解决数据查询时效率过低的问题,有两种场景:
1. 业务上线前对业务模型进行细致分析,确定需要建立索引的字段。
2. 业务线上运行时调整索引字段。
第一种场景可以在系统开发阶段提前建立索引,而第二种场景则复杂的多,主要难点有二:
创建索引时不能阻塞线上业务运行,普通的创建索引属于DDL(Data Definition Language)操作,会对表加锁,阻塞表上的DML(Data Manipulation Language)操作。
若不阻塞表上的DML操作,创建索引的同时可能有数据的插入(INSERT)、更新(UPDATE)和删除(DELETE)操作发生,如何保证索引数据的正确。
为解决上述问题,提出一种在线创建索引(CONCURRENTLY CREATE INDEX)的方法。
PART 02
在线创建索引的应用
不阻塞线上业务运行
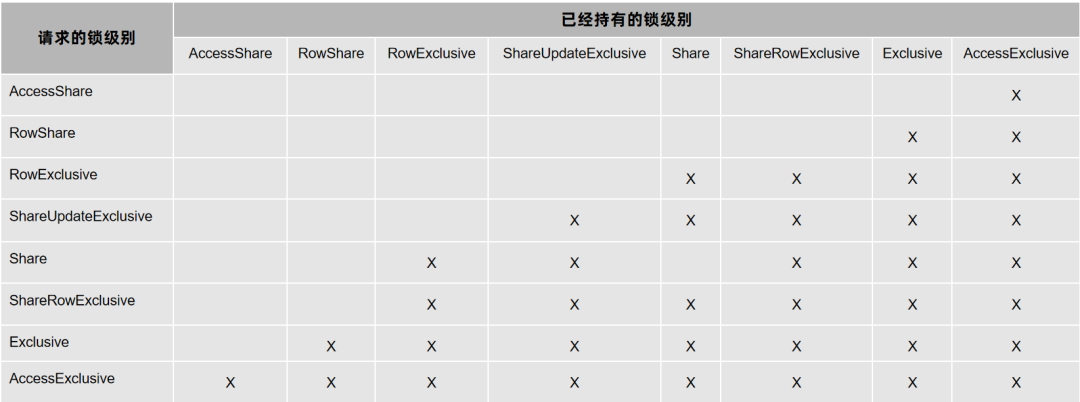
在Vastbase中表级锁有八个级别,从低到高分别如下:
1
AccessShareLock:访问共享锁,通常在查询(SELECT)操作时获取;
2
RowShareLock:行共享锁,通常在FOR UPDATE时获取;
3
RowExclusiveLock:行互斥锁,通常在DML操作时获取;
4
ShareUpdateExclusiveLock:共享更新互斥锁,通常在VACUUM、ANALYZE操作时获取;
5
ShareLock:共享锁,通常在创建索引(CREATE INDEX)时获取;
6
ShareRowExclusiveLock:共享行互斥锁,通常在创建触发器(CREATE TRIGGER)时获取;
7
ExclusiveLock:互斥锁,通常在物化视图刷新、表物理文件扩展时获取;
8
AccessExclusiveLock:访问互斥锁,最高级别的锁,通常在删除表等DDL操作时获取。
上表中[X]表示两种级别的锁有冲突,否则表示不冲突。注意到普通创建索引对表加ShareLock是会和DML操作请求的RowExclusiveLock冲突,这就会导致业务系统线上运行时使用普通的创建索引方法会阻塞业务运行。
根据锁的冲突关系,在线创建索引时对表只能添加ShareUpdateExclusiveLock,这种情况下将不会和DML操作请求的锁冲突。
保证索引数据正确
在线创建索引和DML不冲突,如何保证索引中数据的正确性?普通索引创建过程大致如下:
开启事务

对表添加ShareLock级别锁
创建索引表(索引在Vastbase内部本质上也是一种关系)
对索引表添加AccessExclusiveLock级别锁
读取表中数据并按索引字段值排序
将索引数据<索引字段值,数据位置信息>写入索引表
事务结束(过程中会释放事务执行期间获取的锁)
由于第2步阻塞了表上的DML操作,故第5步中读取数据时不用担心表中数据发生变化,这样第6步写入索引表中的数据就不会发生缺漏。
在线创建索引对表添加ShareUpdateExclusive级别锁,在第5步读取表数据时可能有并发DML操作修改表中数据,这将导致第6步写入索引表中的数据错误。
为了解决上述问题,Vastbase将在线创建索引拆分为多个事务,且在多个事务执行期间持有表上的ShareUpdateExclusive级别锁以防止在事务边界发生race condition,关键过程如下:
事务T1
1. 对表添加ShareUpdateExclusive级别会话锁,防止事务边界出现race condition问题;
2. 创建索引表,但此时索引表中没有数据;
事务T2
1.事务T2开始时先等待那些正在修改表数据的事务结束,确保后续开启的任何事务都能够感知到在事务T1中创建的索引;
2.获取快照S1,并依据此快照读取表中数据,按索引字段排序;
3.将索引数据<索引字段值,数据位置信息>写入索引表
4.将索引标记为可写入状态,虽然索引表中已经有数据,但查询操作仍旧不能使用该索引,插入或者更新操作可以向索引表写入数据;
事务T3
1. 事务T3开始时先等待那些正在修改表数据的事务结束,确保后续开启的事务都感知到索引是可以写入数据的;
2. 获取快照S2,遍历表中数据,若数据对快照S2可见但尚未写入索引表则补齐这部分索引数据;
3. 记录下获取快照S2时最小的事务号Xmin;
事务T4
1. 事务T4开始时先等待所有快照的最小事务号小于等于Xmin的事务结束,确保没有事务可以看到索引表中没有但堆表中可能存在的数据;
2. 将索引设置为可读状态,这样后续开启的事务可以正常使用索引(可读写);
通过将在线创建索引拆解为4个事务,并在合适的时机等待,成功解决了为不阻塞DML操作而进行锁降级带来的数据正确性问题。
PART 03
分区表在线创建全局索引
Vastbase中分区表包含一级、二级分区两种情况,分区方式支持范围(Range)、列表(List)和哈希(Hash)三种形式,整个分区特性的模型如下:

partitioned table表示主表,partition表示一级分区,subpartition表示二级分区。若用户创建的表为一级分区则数据存储在一级分区中,主表中不存储数据;若为二级分区则数据存储在二级分区中,主表和一级分区不存储数据。
相比普通表的索引,分区表全局索引中需要额外记录数据所在的分区信息,另外一个区别是分区表数据存储在每个分区的物理文件中,为了提升在线创建索引的效率,在事务T2执行时会启动多个后台线程并行读取数据、排序,在事务T3执行期间同样启动多个后台线程并行扫描各个分区中缺失的数据。
• END •
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列、海量大数据Datalink系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

