




原标题:LSTMVis--A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks
作者:Hendrik Strobelt, Sebastian Gehrmann, Hanspeter Pfister, and Alexander M. Rush
原文链接:
https://ieeexplore.ieee.org/document/8017583
摘要:Recurrent neural networks, and in particular long short-term memory (LSTM) networks, are a remarkably effective tool for sequence modeling that learn a dense black-box hidden representation of their sequential input.Researchers interested in better understanding these models have studied the changes in hidden state representations over time and noticed some interpretable patterns but also significant noise. In this work, we present LSTMVIS, a visual analysis tool for recurrent neural networks with a focus on understanding these hidden state dynamics. The tool allows users to select a hypothesis input range to focus on local state changes, to match these states changes to similar patterns in a large data set,and to align these results with structural annotations from their domain. We show several use cases of the tool for analyzing specific hidden state properties on dataset containing nesting, phrase structure, and chordprogressions, and demonstrate how the tool can be used to isolate patterns for further statistical analysis. We characterize the domain, the different stakeholders, and their goals and tasks. Long-term usage data after putting the tool online revealed great interest in the machine learning community.
RNN以及他的变体LSTM,GRU等,在序列模型建模上显示出了独特的优势,比如文本处理,机器翻译,语音识别等方面。尽管RNN在序列建模方面显示出明显的改进,但事实证明,很难解释其特征表示,也不清楚确切的模型是如何表示序列中的长距离关系的。通常,RNN包含数百万个参数,并在时变条件下利用大型隐藏表示的重复变换。这些因素使模型之间的依赖关系很难在没有复杂数学工具的情况下进行解释。这种不可解释性就导致了很多问题。首先,对于RNN内部机制不够理解就会导致研究者无法进一步改进模型,以得到更好的性能提升。其次,就是对于模型的信任问题,如果用户不信任模型,当然也不会去使用它。
在这篇文章中,作者专注于RNN中隐藏特征的可视化分析。并且开发了一个可视化的系统LSTMVis,这是一种允许高级用户群体探索并形成有关RNN隐藏状态动态的假设的工具。
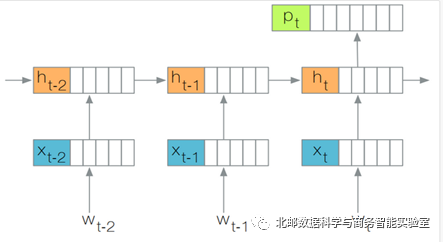
图1 基于RNN的语言模型
文章首先对基于递归神经网络的语言模型进行了介绍,如图1所示。模型的输入是一段文本,可以认为是一个词语的序列w_1, w_2, …, w_T。模型首先会使用一个嵌入层(Embedding Layer)将离散的词语映射实值向量,作为RNN层(比如LSTM)的直接输入。RNN层会根据当前隐含状态h_{t-1}和输入w_t来更新状态,得到h_t。基于这个隐含状态,可以为具体的任务衍生其他的数据。比如,如果这个语言模型用于自动预测/生成下一个词语,那个可以使用softmax层生成一个概率分布,来表示取每一个词的概率。需要注意的是,模型对于每一个词语都会产生一个输出,所以隐含状态可以认为是一个随时间变化的数据。
本文就是研究隐含状态序列h_1,h_2, …, h_T的可视化。已有的工作通常直接使用高维投影技术,来对它们进行可视化。但是,由于所得到的隐含状态与原始输入序列并没有直接关联,所以使用者仍然难以真正理解模型所学到的内容。因此,本文希望能在可视化结果中关联所在的领域数据。
接着作者讨论了可视化工具的目标用户。作者将模型自身的用户划分为三类:架构师、训练者、以及终端用户。架构师指设计神经网络结构的人群,他们需要通过对网络结构的不断调整与比较,以获取更高的性能;训练者则只需要使用一个已经建立好的网络,观察它是如何根据训练数据运作的;而终端用户是指给输入数据、通过网络产生输出结果和置信度的人群。不同的用户使用模型的目的不同。本文中设计可视化的目的则是为了服务前两类用户。
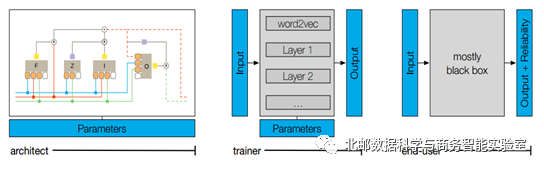
图2 LSTMVis的目标用户
针对这两类用户的用户需求,作者提出了高层次的设计目标,即要回答诸如“这个RNN网络到底在它的隐含状态中学习到了什么样的信息”之类的问题。作者分为三点:
一、形成一个关于“哪些隐含状态学习到哪些特征”的假说;
二、根据可视化结果改进这个假说,包括增强或者拒绝;
三、比较不同的模型和数据集表现。
对于这些高层次目标,作者又定义了其可视化需要支持的几类具体任务:
1、 对隐含状态的时序变化进行可视化(对应第一个目标);
2、 对隐含状态进行筛选(一、二);
3、 根据隐含状态的特征匹配相似的数据样本(二);
4、 将文本信息对应起来(二、三);
5、 提供一个通用的界面(三)。
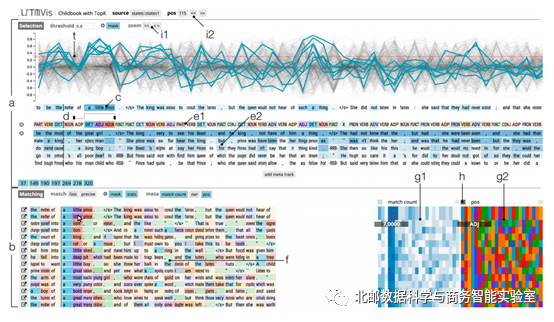
图3 LSTMVis主界面
图3是作者开发的可视化界面,这个工具由选择视图和匹配视图两个主要部件组成。这个可视化工具的主要思想就是,将隐藏状态的值随时间的变化画成折线图,如图3里面a部分所示。对于一个隐含状态向量h_t,它实际上包含若干个分量,每一个对应一个隐含状态。我们可以把每个隐含状态随时间的变化看作一个时间序列,这样就得到若干个时间序列。作者采用时序平行坐标的形式来进行可视化。其中,表示横轴的时间直接对应的文本中的词来表示,而纵轴则表示每个隐含状态的值,也就是对应神经元的激活值。每个隐含状态的变化情况,就用折线绘制出来。用户可以通过调节阈值来对状态进行筛选。
对于完整的隐藏状态的变化图可能很难理解,所以这个系统提供了选择的功能。如图中C,为了提出一个关于隐含状态——数据特征关系的假说,使用者可以从已有的词语序列中去寻找感兴趣的部分进行选择。例如,图(a)中,使用者对“a little prince”词组感兴趣,所以选择了它们,t是指定了一个阈值,大于阈值的隐藏状态表示处于”on”,状态,小于t值得隐藏状态表示处于”off”状态。这种选择功能还可以将前后的相邻词语考虑进来,d表示,在选择了特定的隐藏状态以后,指定这个隐藏状态之前或滞后的隐藏状态是处于”on”还是”off”状态。
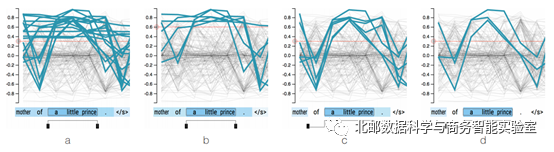
图4 选择功能
更具体的,图4就表示筛选出本来没有被激活、遇到“a little prince”后才被激活的隐含状态。并且一般来说,这种“原本未激活、之后才激活”的隐含状态比一直激活的隐含状态要更有意义,因为一直激活的隐含状态则意味着它们对最后的输出没有特别的作用。因此,作者的可视化工具中默认是图4(c)中的选择方式。基于所筛选出来的隐含状态,使用者可以很容易地将所选词组和这些状态给关联起来,形成假说。
图5 匹配功能
之后,这个可视化工具将在文本其他位置寻找具有相同激活特征的情形,将它们展示出来,作为假说的支持,如图5所示。这是这个可视化工具的匹配视图。从图中可以很直观地看到相同状态具有相同激活特征的情形,正好都对应的是介词+a+名词的形式,即名词词组。因此,用户也基本可以判定所筛选的隐含状态学习到了如何辨别这类词组特征。
作者提出的可视化工具本质上是支持“search-by-example”的探索流程,即让用户能从个例中提出假说,然后在自动匹配出其他的满足条件的例子,来增强或者改进假说,从而达到理解模型的目的。在这之外,作者也将问题本身所在领域的一些其他信息放置到可视化中,帮助用户理解。例如在图3这个研究语言模型的例子中,可以将词语的词性、匹配的状态数量等等,添加到界面中来帮助理解。
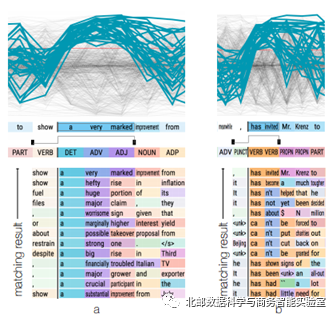
图6 其他两个例子
图6是作者在RNN语言模型上发现的另外两个例子。其中左图筛选出来的是识别名词短语的隐含状态,而右图则是识别动词短语的隐含状态,并且两者都可以同匹配到的语料中加以验证。作者还另外使用一个投影图,将各个短语对应的激活状态给投影出来,也发现两者存在明显的区分关系。
总之,LSTMVIS提供了交互式可视化,以促进对RNN隐藏状态的数据分析。该工具基于直接推论,用户可以选择一定范围的文本来表示假设,然后将该选择与数据集中的其他示例进行匹配。该工具可以轻松地使用外部注释来验证或拒绝假设。它只需要按时间顺序排列的隐藏状态,就可以轻松地对不同数据集和模型,甚至不同任务(语言建模,翻译等)进行广泛的可视化分析。
