




广告时间:
• 长期承接数据处理、分析、建模工作
• 软件开发工作
• 培训
• 大模型相关服务
AI应用1: Text2SQL, Text2BI, 自然语言转SQL及图表
今天讨论的第二个应用则是情感分析的话题,
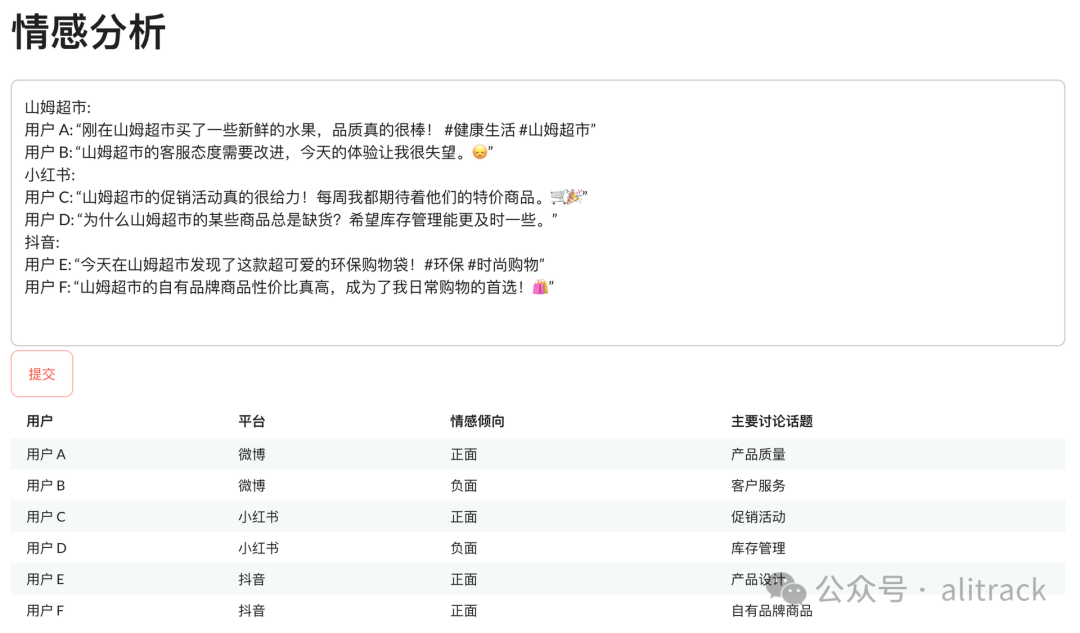
这是根据客户需要写的一个演示,使用了Google Gemini,也对OpenAI及国内的几个商用LLM做了测试,整体效果差不多,开源模型也做了些测试。有兴趣测试国内大模型的,看看这篇文章,国内大模型开始送免费Token了,你不接着吗?,也许还能得到免费的Tokens。
TLR
利用LLM来分析产品评价(不论是你自己的产品还是竞品),从而理解消费者对产品的情绪反应,认识到产品的优势与不足,以及如何优化产品以更好地满足消费者需求。这曾经是一项繁琐的任务,需要机器学习和自然语言处理(NLP)技术,收集大量的训练数据,并对文本进行细致的预处理。然而,ChatGPT的出现改变了这一切,它使你能够根据产品的评价生成富有洞察力的、可行的建议,而无需聘请数据科学家。听起来很有趣吗?在这篇文章中,我将展示如何使用AI技术快速且准确地从消费者评价中获取深入的洞察。
准备工作:
• 大模型
• 国外大模型:OpenAI和Google Gemini 的账号。
• 国内大模型:国内大模型开始送免费Token了,你不接着吗?
• 本地部署开源模型,这里推荐ollama[1],支持模型多,而且跨平台(Windows,Linux,macOS)
• 测试数据集,这里使用的是Kaggle的影评数据:IMDB Dataset of 50K Movie Reviews[2]
编码、测试、验证
这里我们从测试数据集里随机取100条做个验证,
import os
from openai import OpenAI
from sklearn.metrics import (accuracy_score, classification_report,
confusion_matrix, jaccard_score)
import pandas as pd
reviews_df = pd.read_csv('IMDB Dataset.csv.zip')
sample = reviews_df.sample(100)
多个待测试模型的信息,这里以ollama
的llama2
模型为例,可以根据需要扩充,
llms ={}
llms['llama2']={'api_key':"ollama",
'base_url':"http://localhost:11434/v1",
'model':'llama2'}
测试代码
def completion(prompt, llm, temperature=0.1):
model = llms[llm]['model']
client = OpenAI(api_key=llms[llm]['api_key'],base_url=llms[llm]['base_url'])
system_prompt="You are an AI language model trained to analyze and detect the sentiment of reviews."
messages = [{'role': 'system', 'content': system_prompt},{'role': 'user', 'content': prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=2
)
return response.choices[0].message.content.strip()
def sentiment_analysis(llm,sleep=3):
true = []
llm_pred = []
for index, row in sample.iterrows():
true.append(row['sentiment'])
time.sleep(sleep)
tag = completion(prompt.format(review=row['review']),llm)
llm_pred.append(tag)
true = [1 if x == 'positive' else 0 for x in true]
llm_pred = [1 if x == 'positive' else 0 for x in llm_pred]
print(f"{llm}:")
print(f'Accuracy: {accuracy_score(true, llm_pred)}')
print(f'Jaccard Score: {jaccard_score(true, llm_pred)}')
print(f'Confusion Matrix:\n{confusion_matrix(true, llm_pred)}')
print(f'Classification Report:\n{classification_report(true, llm_pred)}')
prompt="""
Label the sentiment of the given text. The answer should be exact ‘positive’ or ‘negative’.
Statement: {review}
The answer is:
"""
sentiment_analysis('openhermes',0)
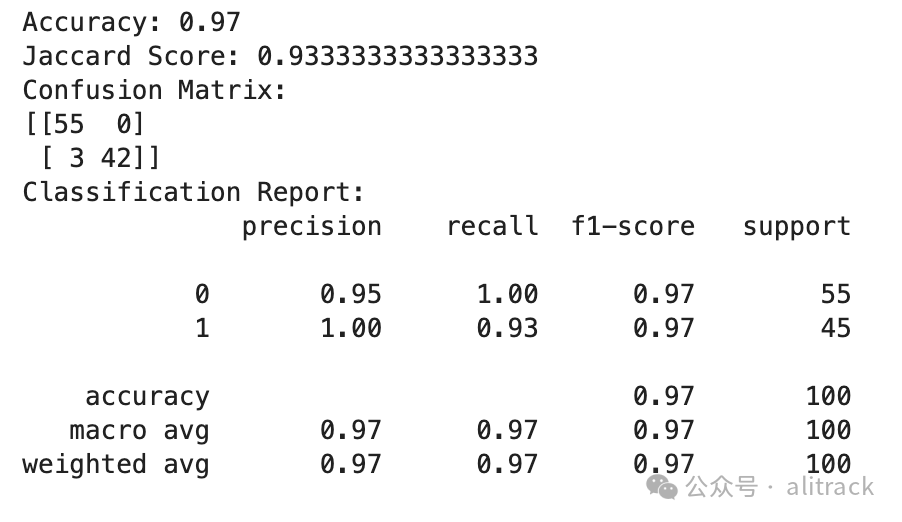
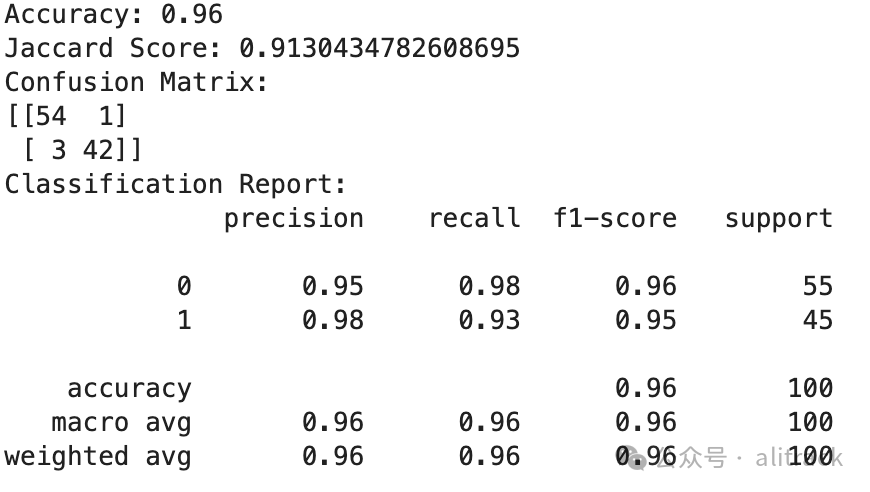
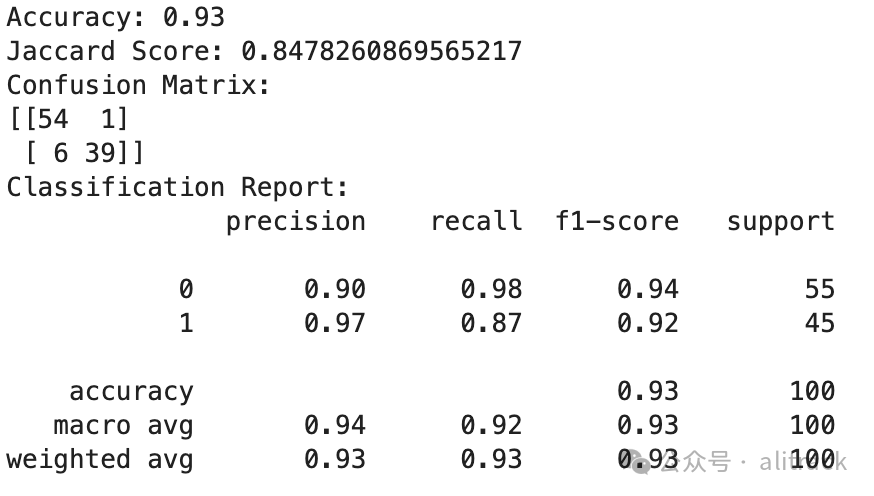
测试结果
这里放两个例子对比下,
• 智谱AI,GLM-4
• Google Gemini
• 开源模型
⚠️:实际测试结果,可能受以下因素影响
• system prompt
• user prompt
• 参数设定
不仅仅是情感分析
除了前面提到的情感分析,还能做的还有很多,如
• 从原始客户评论中生成优缺点列表
• 从原始评论中生成产品改进建议列表
• 将改进建议列表合并到前 10 名
• 解释 ChatGPT 为何选择这些改进作为最重要的改进
• 根据完成这些建议的估计工作量对建议列表进行优先级排序
• 。。。
这些代码以后再放吧。
引用链接
[1]
ollama: https://ollama.com/[2]
IMDB Dataset of 50K Movie Reviews: https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
