本人持仓股:随时可能卖出 仅供参考。
什么是word embedding
Word2Vec简介
CBOW和Skip-Gram
CBOW模型
Skip-gram模型
加速策略(一):Hierarchical Softmax
加速策略(二):Negative Sampling
word2vec词向量性质观察
(1)如果用一句比较简单的话来总结,word2vec是用一个简单的神经网络把one-hot形式的稀疏词向量映射称为一个n维(n一般为几百)的稠密向量的过程。
(2)什么是word embedding
我们将一个词从一个可能非常稀疏的向量坐在的空间,映射到现在这个四维向量所在的空间,必须满足以下性质:
(1)这个映射是单设;
(2)映射之后的向量不会丢失之前向量所含的信息。
这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。顺便找了个图 三维到二维

经过一系列的降维操作,有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了
需要注意的是和下面要讲的word2vec和word embedding的联系和区别,word embedding 是一个将词向量化的概念,或者说是一种基于神经网络的分布表示,为区别one-hot的词向量,可翻译成词嵌入。而word2vec是谷歌提出一种word embedding 的工具或者算法集合
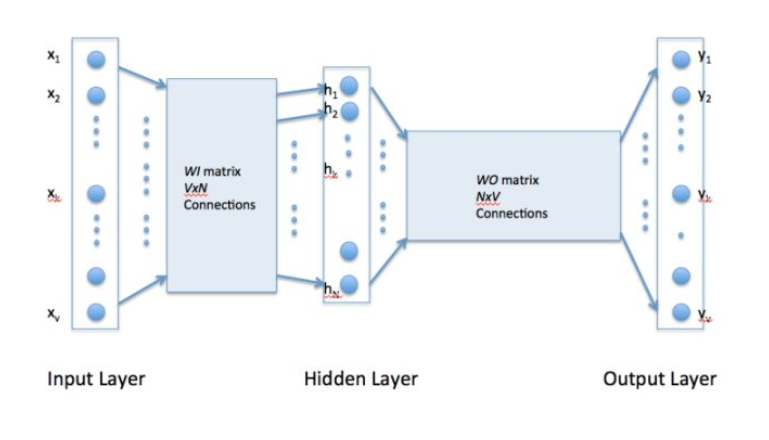
下面看图说下整体步骤是怎么样的:
在输入层,一个词被转化为One-Hot向量。
然后在第一个隐层,输入的是一个
 (
(  就是输入的词向量,
就是输入的词向量,  ,
,  是参数),做一个线性模型,注意已这里只是简单的映射,并没有非线性激活函数,当然一个神经元可以是线性的,这时就相当于一个线性回归函数。
是参数),做一个线性模型,注意已这里只是简单的映射,并没有非线性激活函数,当然一个神经元可以是线性的,这时就相当于一个线性回归函数。第三层可以简单看成一个分类器,用的是Softmax回归,最后输出的是每个词对应的概率
举个例子:
如果我们的语料库仅仅有这3句话:
“the dog saw a cat”,
“the dog chased the cat”,
“the cat climbed a tree”.
那么语料库只有8个单词: “the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”.
那么V=8, 输入层的初始就可以是:
[1, 1, 1, 1, 1, 1, 1, 1] 代表: [“the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”]
输入[“”, “dog“, “”, “”, “”, “”, “”, “”] 可以表示为: [0, 1, 0, 0, 0, 0, 0, 0]
输入[“”, “”, “saw“, “” , “”, “”, “”, “”] 可以表示为: [0, 0, 1, 0, 0, 0, 0,0]
如果是在字典中有的, 就用1表示
W 的大小是NxV的, 通过训练完毕后得到权重  ,当只要输入单词, 就能预测出最符合这个上下文的下一个单词时,这时候的 参数的精度最高。
,当只要输入单词, 就能预测出最符合这个上下文的下一个单词时,这时候的 参数的精度最高。
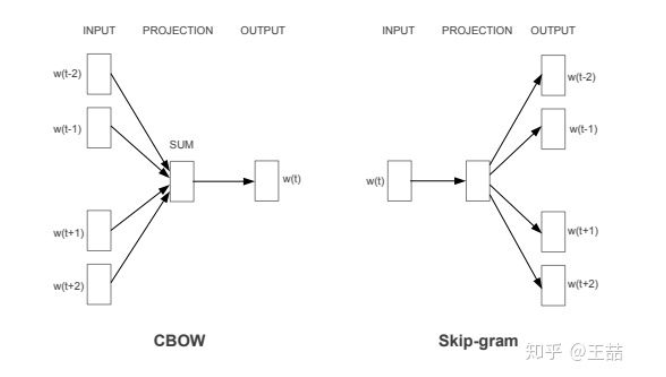
CBOW(continues bag of words)和Skip-Gram
Word2vec是一种可以进行高效率词嵌套学习的预测模型。其有两种变体是现在比较常用的,分别为:连续词袋模型(CBOW)及Skip-Gram模型。从算法角度看,其本质是通过context——word(背景词)来预测target word(目标词),而Skip-Gram模型做法相反,Skip-Gram是利用目标词预测背景词。
CBOW的全称是continuous bag of words(连续词袋模型)。其本质也是通过context word(背景词)来预测target word(目标词)。如上述不同的时候,上述target word“climbed”的context word只有一个“cat”作为训练样本,而在CBOW中,可由多个context word表示.
CBOW(continues bag of words):
“the cat climbed a
tree”. 这句话
例如,我们可以使用“cat”和“tree”作为“climbed”的context word。这需要修改神经网络架构。


简单的讲,CBOW是依据背景词来预测目标词。
具体算法如下:
第一步就是去计算隐藏层h的输出。如下:

(权重矩阵WI依然是one-hot编码)
第二步就是计算在输出层每个结点的输入。如下:

其中WOj是矩阵WO的第j列
接着我们计算输出层的输出,也就是将Softmax用作激活函数
最后使用交叉熵最为loss function,用BP算法更新权重
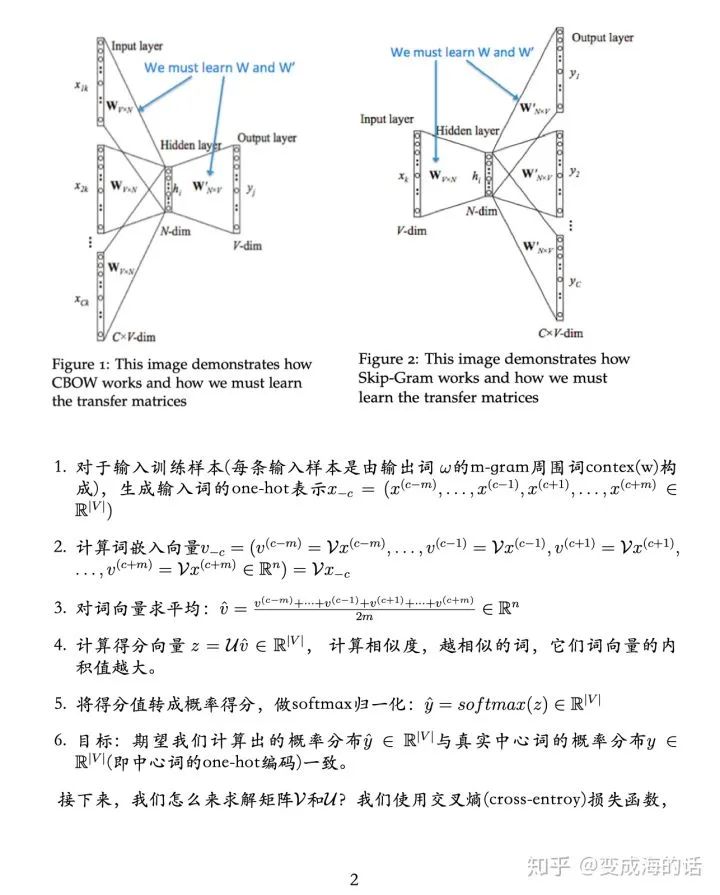

Skip-Gram是利用目标词预测背景词。
在介绍skip-gram模型前,我们先来了解下训练数据的格式。skip-gram模型的输入是一个单词WI,它的输出是WI的背景词:WO_1,...,WO_C,C为窗口大小。
举个例子,有个句子“I drive my car to the store”。我们如果把”car”作为训练输入数据,窗口大小设置为6,那么{“I”, “drive”, “my”, “to”, “the”, “store”}就是输出。所有这些单词会进行one-hot编码。skip-gram模型图如下所示:
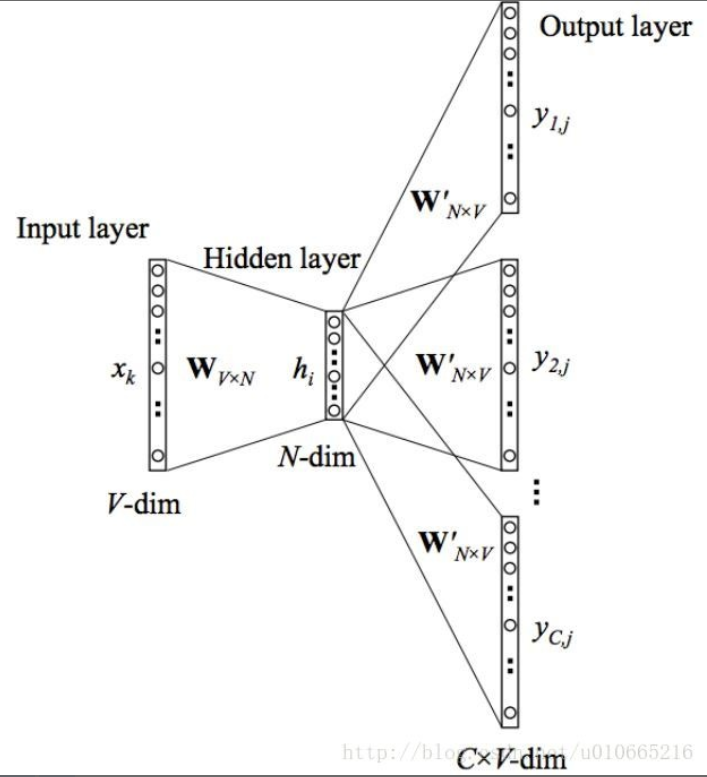
在上图中,输入向量x代表某个单词的one-hot编码,对应的输出向量{y1,…,yC}。接下来重点来了:这个权重矩阵W就是我们需要学习的目标(同W′),因为这个权重矩阵包含了词汇表中所有单词的权重信息。
每个输出单词向量也有个N×V维的输出向量W′。最后模型还有N个结点的隐藏层,我们可以发现隐藏层节点hi的输入就是输入层输入的加权求和。因此由于输入向量x是one-hot编码,那么只有向量中的非零元素(也就是“1”)才能对隐藏层产生输入。因此对于输入向量x其中xk=1并且xk′=0,k≠k′。所以隐藏层的输出只与权重矩阵第k行相关。
在输出层,不再是一个多项式分布,而是输出C个多项式分布。每一个输出用同一个W’计算,同样采用Softmax计算概率,误差为所有输出{y1,…,yC}的误差和,采用交叉熵做损失函数,最后用BP算法更新参数。