




一 :什么是决策树
简单介绍 一下决策树 ,这里借用知乎的一个回答:
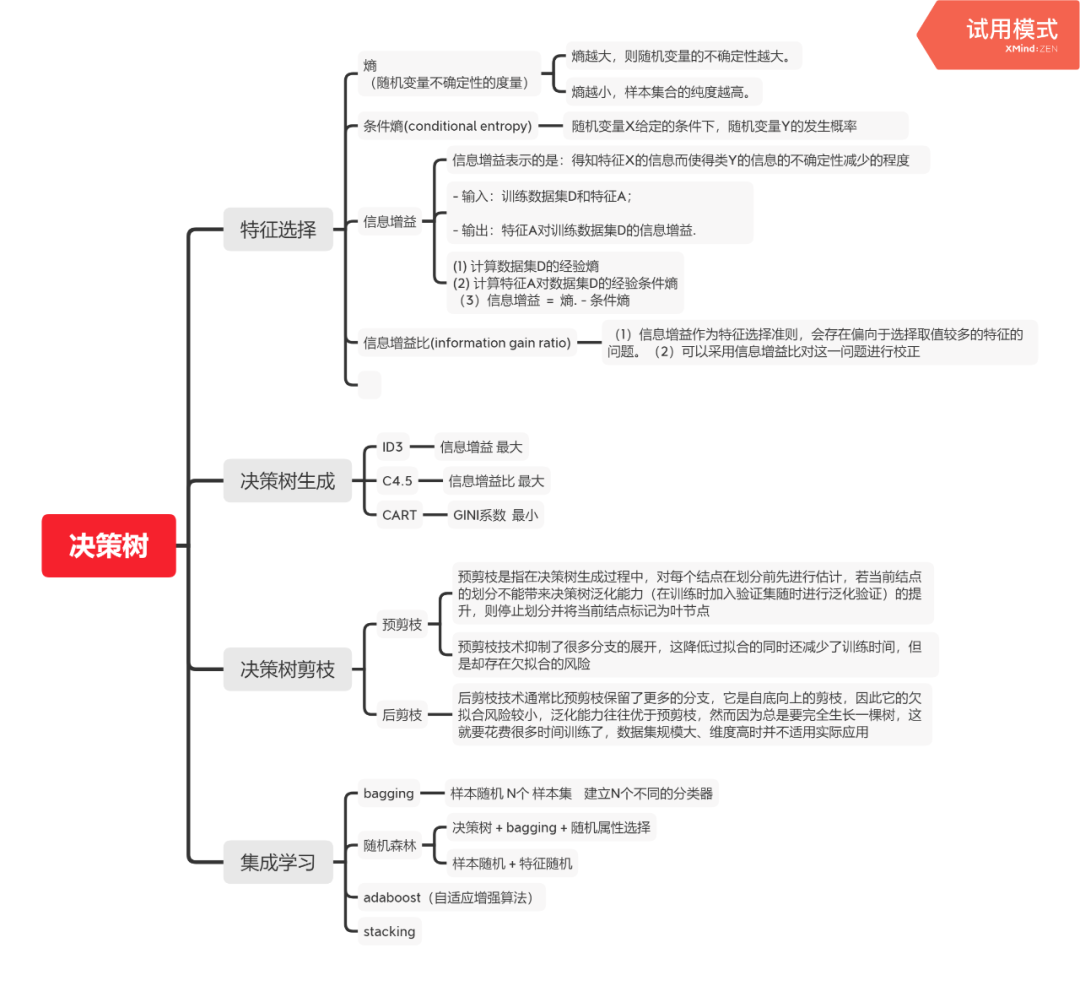
如果你是女性,你面临这一个择偶的问题,前面有一些男性,于是你在心里做了一些“决策”来决定选择谁,把你的决策结果画下来就是一颗树了,如下图
它可以看作if-then规则的集合,认为是定义在特征空间与类空间上的条件概率分布。一般情况,一个机器学习算法需要很多样本(也就是很多人的决策过程)来进行学习。
而我们在学习决策树的时候,其目的就是学一颗泛化能力最强的树。从上面的图可以看出,男性的特征有三个:高否,富否,帅否,而学习的树有根节点有中间节点有树叶,那么凭什么就把富否当做根节点,把高否当做最下面的节点呢?
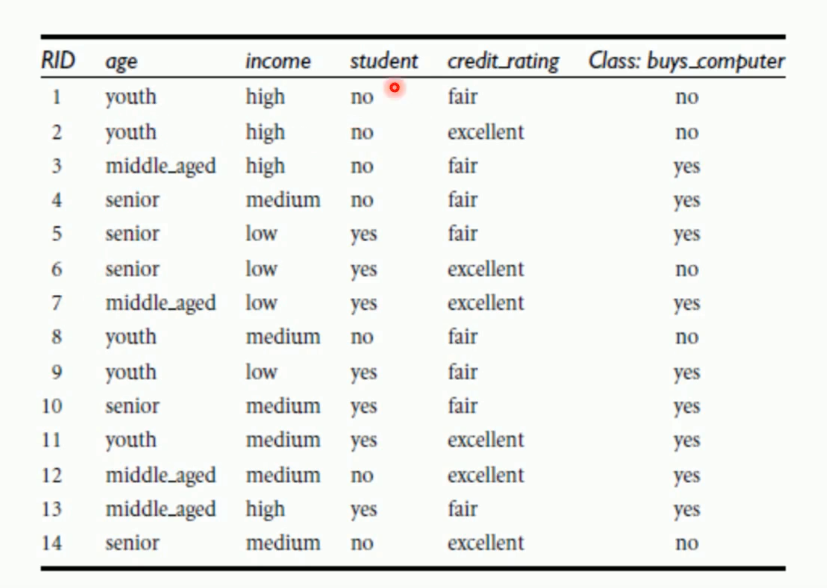
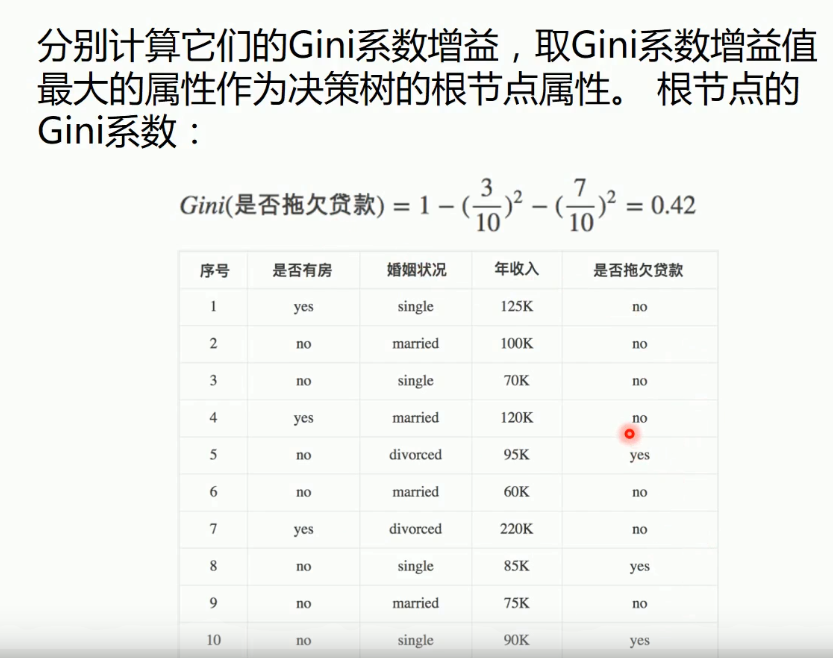
上 个太简单了 特征太少 无效特征也少。只是举例说明什么是决策树 下图是一个人的信息和是否购买 电脑的 统计表 和生成的决策树
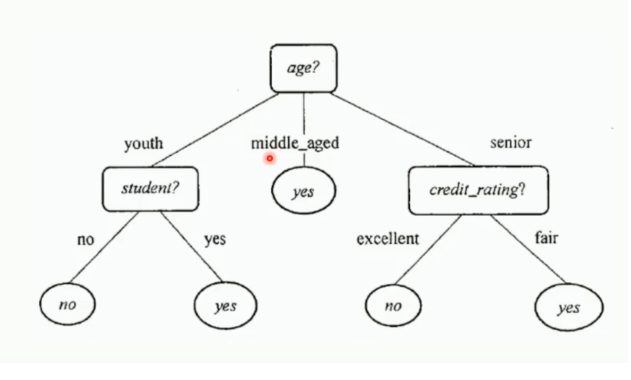
将决策树转换成if-then规则的过程如下:
由决策树的根节点到叶节点的每一条路径构建一条规则;
路径内部结点的特征对应规则的条件;
叶节点的类对应规则的结论.
决策树学习算法主要由三部分构成:
特征选择
决策树生成
决策树的剪枝
下面就以这三部分 详细讲解
二. 决策树的特征选择
我们应该基于什么准则来判定一个特征的分类能力呢?这时候,需要引入一个概念:信息增益.
在介绍信息增益之前,先了解一个基础概念:熵(entropy).
在信息论与概率论中,熵(entropy)用于表示**随机变量不确定性的度量**。
设X是一个有限状态的离散型随机变量,其概率分布为

则随机变量 的熵定义为
的熵定义为

熵越大, 则随机变量的不确定性越大。
熵的值越小,样本集合的纯度越高。

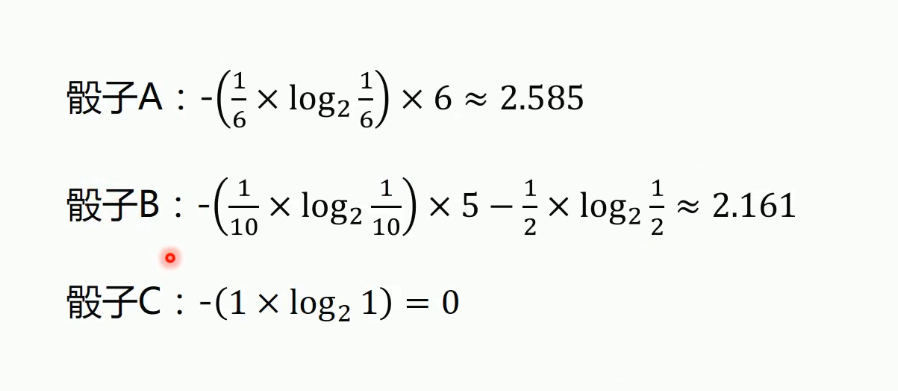
条件熵(conditional entropy)
随机变量给定的条件下,随机变量 的条件熵
的条件熵 定义为:
定义为:

其中, 。
。
2.2信息增益
信息增益表示的是:得知特征X的信息而使得类Y的信息的不确定性减少的程度。下面为复杂的数学公式 不感兴趣可以跳过。
特征A对训练数据集D的信息增益
定义 为集合D的经验熵 与特征A对数据集D的经验条件熵
与特征A对数据集D的经验条件熵 之差,即
之差,即
根据信息增益准则进行特征选择的方法是:对训练数据集D,计算其每个特征的信息增益,并比它们的大小,从而选择信息增益最大的特征。

很难懂吧 。简单以上面的男生例子来说 就是 {富} 对 {高, 富,帅}男生特征集群的的增益最高 ,而是否购买电脑这个数据集来说 年龄是信息增益最大的 的。结论是通过 大量样本数据计算得来的。
假设训练数据集为D,样本容量为|D|,有 个类别
个类别 为类别
为类别 的样本个数。某一特征
的样本个数。某一特征 有n个不同的取值
有n个不同的取值 。根据特征A的取值可将数据集D划分为n个子集
。根据特征A的取值可将数据集D划分为n个子集 ,
, 为
为 的样本个数。并记子集中属于类
的样本个数。并记子集中属于类
的样本的集合为 为
为 的样本个数。
的样本个数。
求信息增益的算法过程分为为三部:
- 输入:训练数据集D和特征A;
- 输出:特征A对训练数据集D的信息增益.
(1) 计算数据集D的经验熵.
- (2) 计算特征A对数据集D的经验条件熵 .
.

- (3) 计算信息增益 熵. - 条件熵
2.3 信息增益比(information gain ratio)
以信息增益作为特征选择准则,会存在偏向于选择取值较多的特征的问题。可以采用信息增益比对这一问题进行校正。
特征A对训练数据集D的 信息增益比
定义为其信息增益与训练集D关于特征A的值的熵之比,即

其中,  .
.
以上就是特征选择的过程
三.决策树的生成:
决策树的生成算法有很多变形,这里介绍几种经典的实现算法:ID3算法,C4.5算法和CART算法
ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择。具体做法是:
从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;
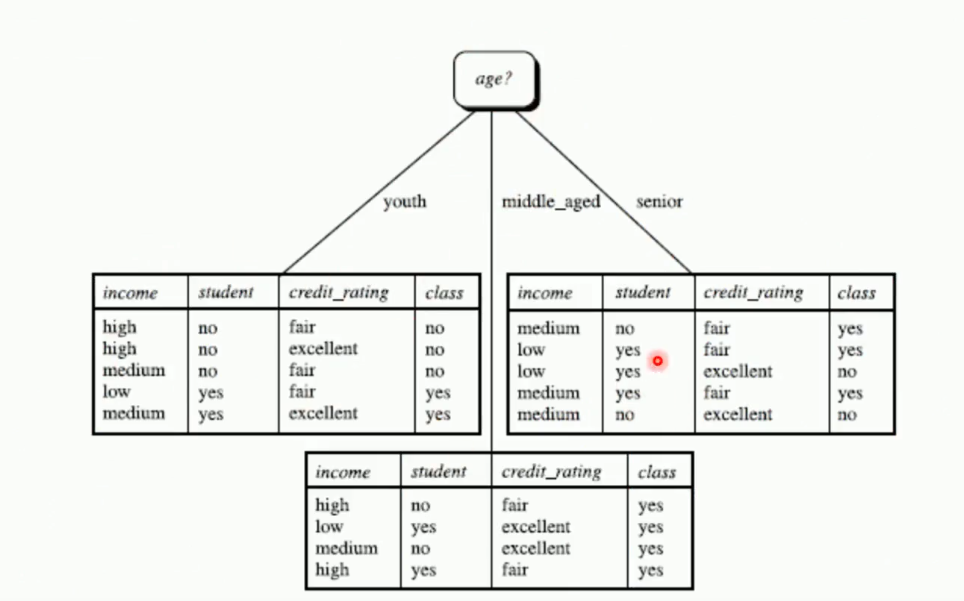
对子节点递归地调用以上方法,构建决策树;
直到所有特征的信息增益均很小或者没有特征可选时为止。
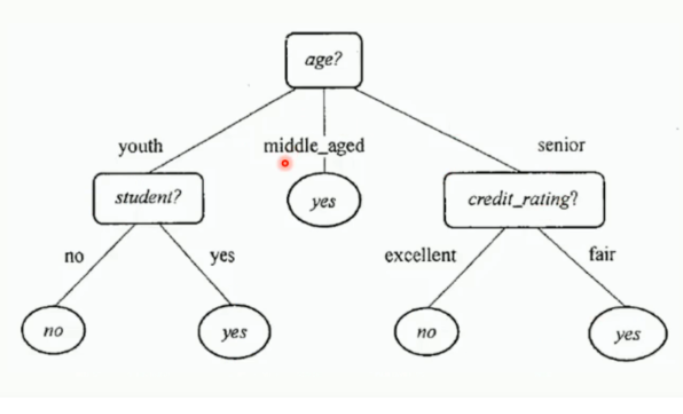
C4.5算法
C4.5算法与ID3算法的区别主要在于它在生产决策树的过程中,使用信息增益比来进行特征选择。
CART算法:使用基尼指数作为属性划分指标。
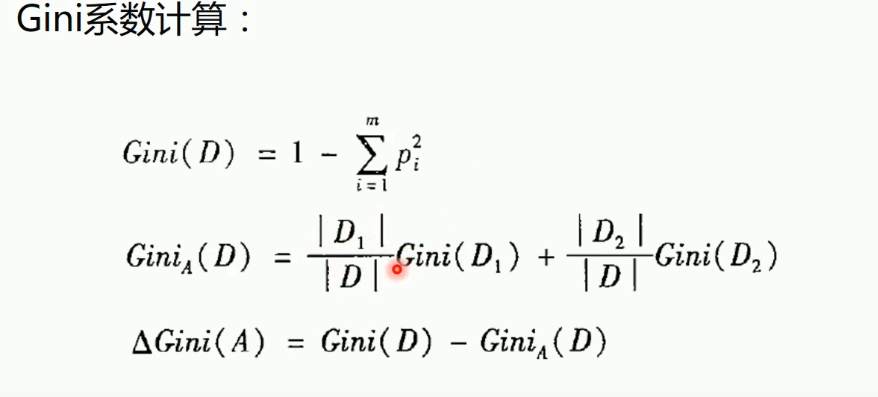

样本集合数据集的纯度除了可以用熵来衡量外,也可以用基尼值来度量:

基尼值反映了从数据集中随机抽取两个样本,其类别标记不一致的概率,因此基尼值越小,则数据集纯度越高。
对属性a进行划分,则属性a的基尼指数定义为:

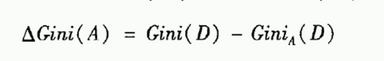
cart算法在选择划分属性时,选择那个使得划分之后基尼指数最小的属性作为划分属性。
那么到底使用基尼指数还是熵来进行属性划分选择呢?其实大部分时候它们两种属性划分选择方式所生产的决策树基本相同,但gini值的计算更快一些,因此在sklrean中默认的划分方式就是gini指数,默认的决策树是CART树;但是gini指数的划分趋向于孤立数据集中数量多的类,将它们分到一个树叶中,而熵偏向于构建一颗平衡的树,也就是数量多的类可能分散到不同的叶子中去了
分类与回归树(classification and regression tree,CART)与C4.5算法一样,由ID3算法演化而来。CART假设决策树是一个二叉树,它通过递归地二分每个特征,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布。
CART算法中,对于回归树,采用的是平方误差最小化准则;对于分类树,采用基尼指数最小化准则。
决策树剪枝:
预剪枝 和后剪枝
预剪枝:限定树的的最大生长高度
后剪枝: 在测试集上定义损失函数,通过剪枝使损失函数在测试集上有所降低
使用一个训练样本集合来生成一个决策树,如果不做任何限制,让决策树随意生长,那么决策树将拟合所有训练样本使得训练正确率达到100%;毫无疑问这是没有意义的,因为它完全过拟合了,这样的决策树不具有泛化能力。那么决策树是怎样来防止过拟合呢?一般的措施是将生产的决策树进行剪枝,预剪枝或者后剪枝。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化能力(在训练时加入验证集随时进行泛化验证)的提升,则停止划分并将当前结点标记为叶节点;后剪枝则是先从训练集中生成一颗完整的树,然后自底向上对非叶节点进行考察,若该节点对应的子树替换为叶节点能够提升泛化能力,则进行剪枝将该子树替换为叶节点,否则不剪枝。
很明显,预剪枝技术抑制了很多分支的展开,这降低过拟合的同时还减少了训练时间,但是却存在欠拟合的风险;预剪枝基于“贪心”策略,往往可以达到局部最优解却不能达到全局最优解,也就是说预剪枝生成的决策树不一定是最佳的决策树。XGBoost和lightGBM使用的树就是预剪枝的CART决策树,这能保证他们的训练速度较快,但是准确率如何保证呢?你知道吗,我们大概在讲随机森林的时候再提这点。。
后剪枝技术通常比预剪枝保留了更多的分支,它是自底向上的剪枝,因此它的欠拟合风险较小,泛化能力往往优于预剪枝,然而因为总是要完全生长一棵树,这就要花费很多时间训练了,数据集规模大、维度高时并不适用实际应用。
集成学习

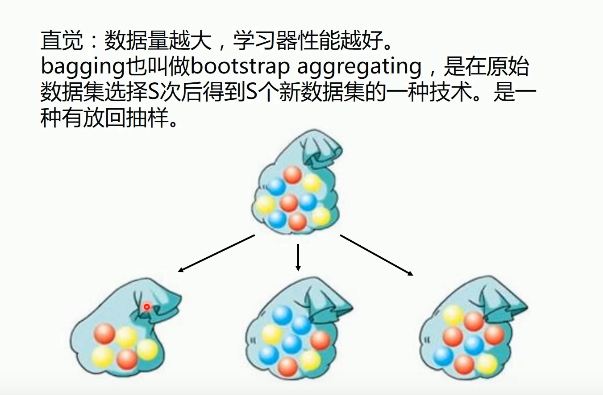

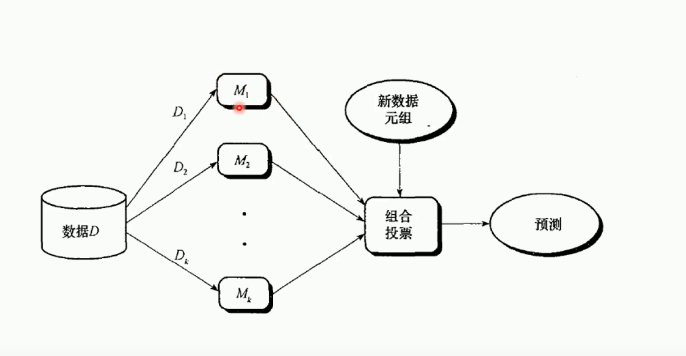
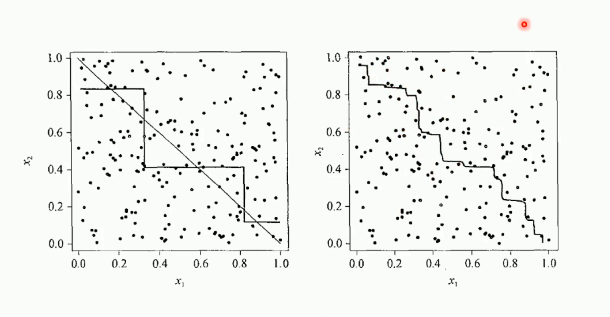
随机森林 :

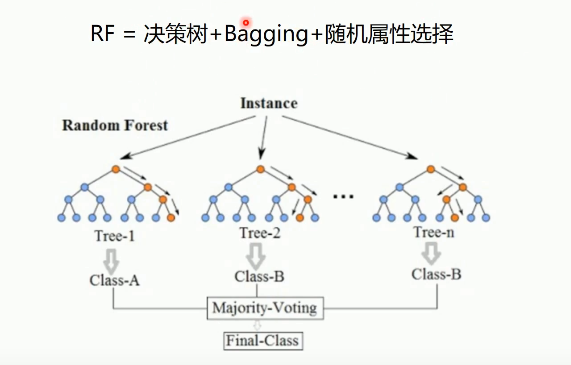
Adaboost算法可以简述为三个步骤:
(1)首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都被赋予相同的权值:w1=1/N。
(2)然后,训练弱分类器hi。具体训练过程中是:如果某个训练样本点,被弱分类器hi准确地分类,那么在构造下一个训练集中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。



