




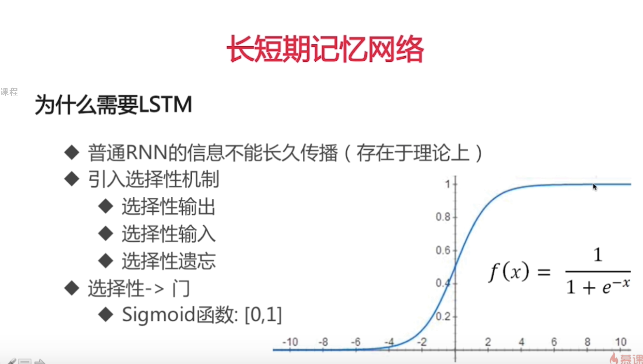

什么是LSTM
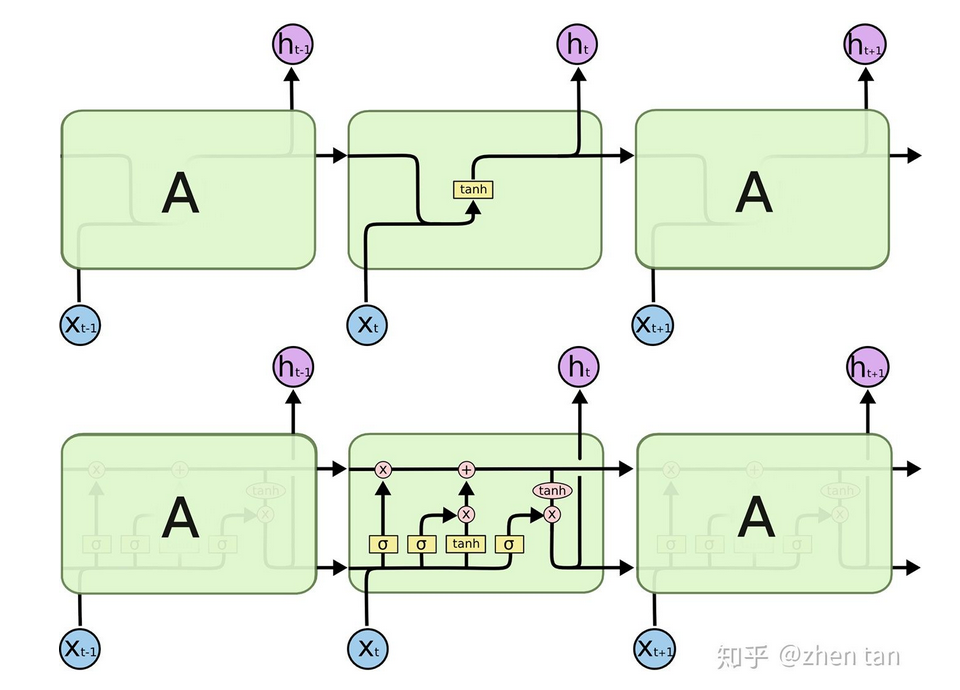
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
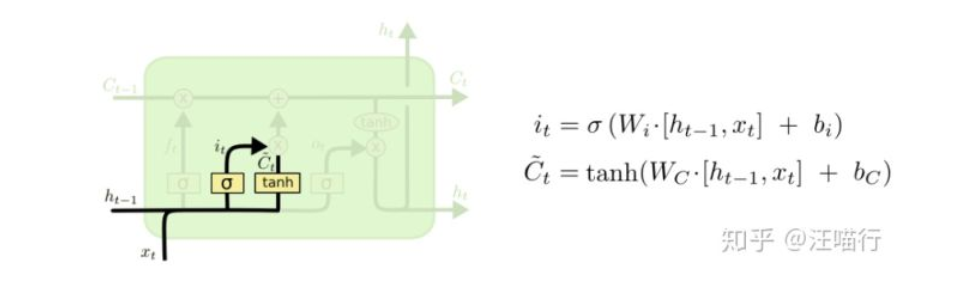
 可以分为以下关键变量(参考题图):
可以分为以下关键变量(参考题图):
输入:
 (t-1时刻的隐藏层)和
(t-1时刻的隐藏层)和  (t时刻的特征向量)
(t时刻的特征向量)输出:
 (加softmax即可作为真正输出,否则作为隐藏层)
(加softmax即可作为真正输出,否则作为隐藏层)主线/记忆:
 和
和
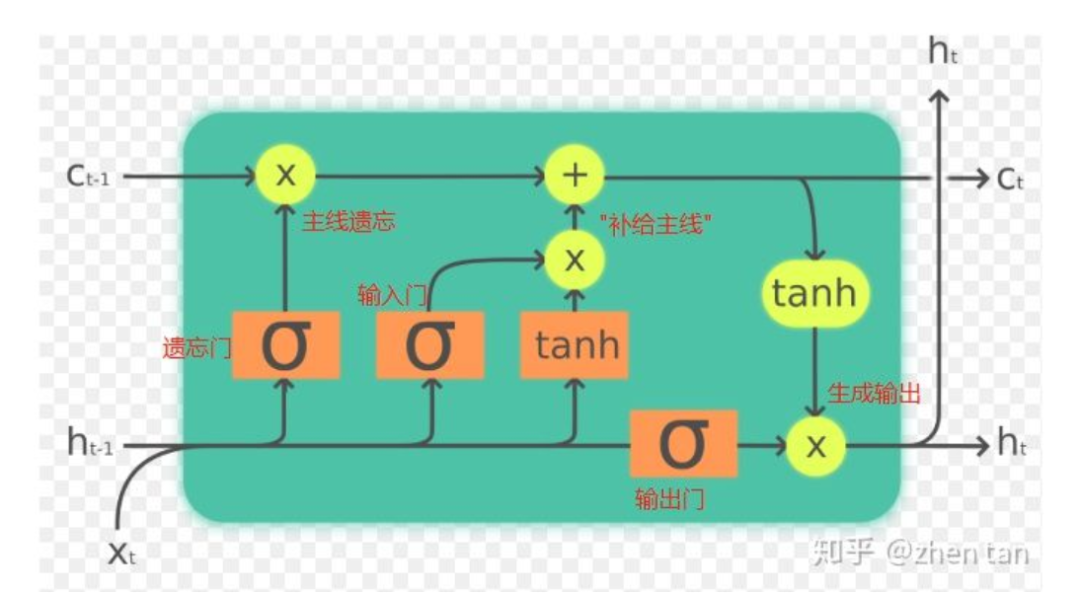
依次分类的依据为(参考图1):
参考橙色部分,
和 联合起来控制了三个门,并且是输入的唯一来源,所以划分为输入部分。图中往上跑的
,它与真正的输出只隔了一层softmax(图中没画出),是输出的直接来源,所以划分为输出部分。当然它同时又是下一个LSTM cell的输入(图中往右跑的 ),但是在当前cell,它仅与输出相关。如图黄色部分,
和 始终与外界隔离开来,显然是作为LSTM记忆或者主线剧情的存在。主线进来后,首先受到遗忘门的衰减作用,接着输入门控制“补给大小”给主线补充能量生成全新的主线。这一衰一补的过程完成了主线的更新。接着在输出门的控制下生成新的输出 。
LSTM公式梳理
LSTM的三个门均采用sigmoid函数,所以并不是只取0和1的门,而是近似。激励函数采用tanh,为奇函数,所以均值为0。
下面将公式分为三部分进行梳理,其中  代表点乘。提醒一下,每个括号里面虽然参数不一样,但本质均为输入部分,不用太纠结,当作“输入”两个字看即可。
代表点乘。提醒一下,每个括号里面虽然参数不一样,但本质均为输入部分,不用太纠结,当作“输入”两个字看即可。
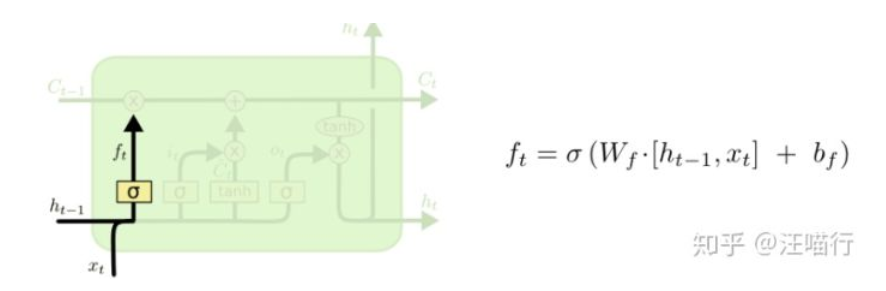
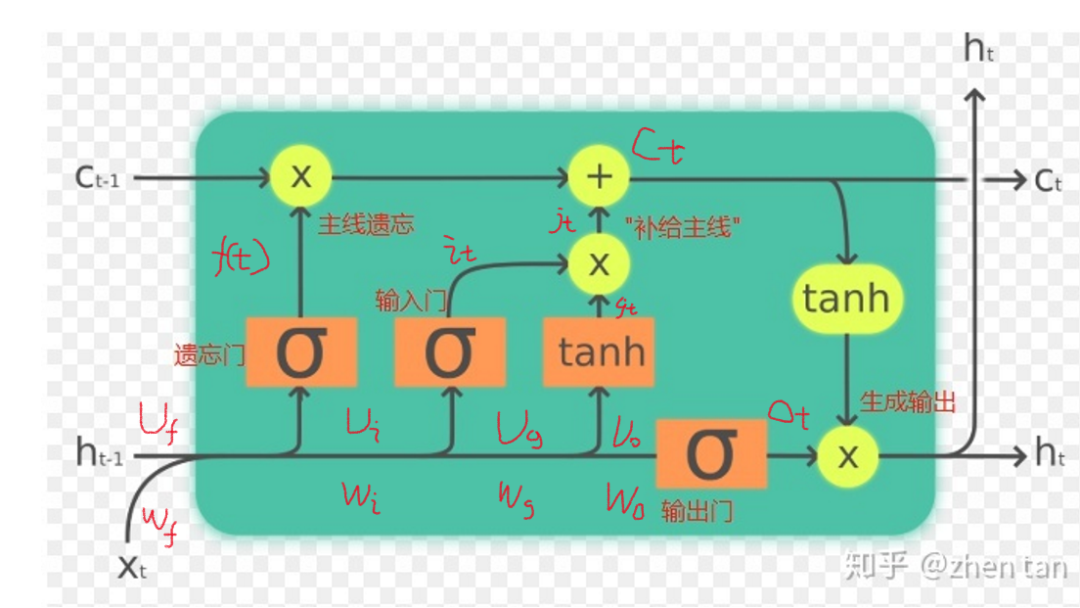
遗忘门部分
遗忘门,表示上个时间点的状态我应该遗忘多少。会首先看上一个阶段的输出ht-1和这个阶段的输入xt,并通过sigmoid来确定要让Ct-1,来忘记多少


输入门部分
首先会拿上一个阶段的输出ht-1和这个阶段的输入xt,通过sigmoid来控制现在要加多少进入主线剧情Ct,即第一个公式的含义;然后又会创建一个备选的Ct~ = g(t),用tanh去控制要加入部分是多少。之后通过把两个部分相乘,总共决定了要影响Ct的量是多少,加上之前的遗忘门的影响




输出门部分


1、为了解决RNN中的梯度消失的问题,为了让梯度无损传播,想到了c(t)=c(t-1),称c为“长时记忆单元”。
2、然后为了把新信息平稳安全可靠的装入长时记忆单元,引入了“输入门”。
3、然后为了解决新信息装载次数过多带来的激活函数饱和的问题,引入了“遗忘门”。
4、然后为了让网络能够选择合适的记忆进行输出,引入了“输出门”。
5、然后为了解决记忆被输出门截断后使得各个门单元受控性降低的问题,我们引入了“peephole”连接。
6、然后为了将神经网络的简单反馈结构升级成模糊历史记忆的结构,引入了隐单元h,并且发现h中存储的模糊历史记忆是短时的,于是记h为短时记忆单元。
7、于是该网络既具备长时记忆,又具备短时记忆,就干脆起名叫“长短时记忆神经网络(Long Short Term Memory Neural Networks,简称LSTM)“啦。
LSTM的特点就是,通过遗忘门,输入门,输出门对于状态C的影响,最终决定每一个时间点,要忘记多少,记住多少,输出多少,最后把这个状态一直传递下去,从而达到可以控制其不会忘记遥远的重要信息,也不会把附近的不重要的信息看的太重的作用。
模型构建
vocab_size = len(vocab)embedding_dim = 256rnn_units = 1024def build_model(vocab_size, embedding_dim, rnn_units, batch_size):model = keras.models.Sequential([keras.layers.Embedding(vocab_size, embedding_dim,batch_input_shape = [batch_size, None]),keras.layers.LSTM(units = rnn_units,stateful = True,recurrent_initializer = 'glorot_uniform',return_sequences = True),keras.layers.Dense(vocab_size),])return modelmodel = build_model(vocab_size = vocab_size,embedding_dim = embedding_dim,rnn_units = rnn_units,batch_size = batch_size)model.summary()

载入之前模型
model2 = build_model(vocab_size,embedding_dim,rnn_units,batch_size = 1)model2.load_weights(tf.train.latest_checkpoint(output_dir))model2.build(tf.TensorShape([1, None]))# start ch sequence A,# A -> model -> b# A.append(b) -> B# B(Ab) -> model -> c# B.append(c) -> C# C(Abc) -> model -> ...model2.summary()
