







什么是embedding呢 以大名鼎鼎的 word embedding来说
我个人的理解是用一个向量来代表这个word,这个向量是可学习的
在数学上表示一个maping: , function。
, function。
其中该函数满足两个性质:
injective (单射的):就是我们所说的单射函数,每个X只有唯一的Y对应;
structure-preserving(结构保存):比如在X所属的空间上
 ,那么映射后在Y所属空间上同理
,那么映射后在Y所属空间上同理  。
。
那么对于word embedding, 就是找到一个映射(函数)将单词(word)映射到另外一个空间(其中这个映射具有injective和structure-preserving的特点), 生成在一个新的空间上的表达,该表达就是word representation
很难理解 。说点通俗的 的。 转自 知乎
@邱锡鹏老师的《神经网络与深度学习》里对这个的解释比较容易理解——对颜色的RGB表示法就属于一种典型的分布式表示:
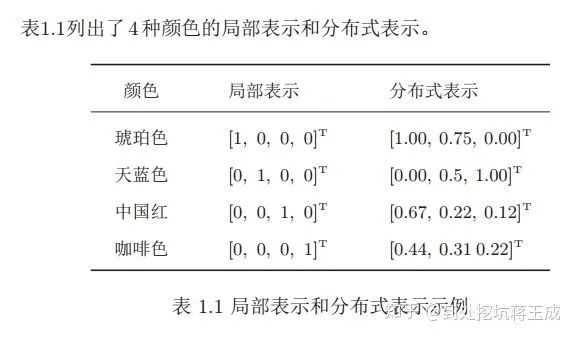
对于颜色,我们可以把它拆成三个特征维度,用这三个维度的组合理论上可以表示任意一种颜色。
同理,对于词,我们也可以把它拆成指定数量的特征维度,词表中的每一个词都可以用这些维度组合成的向量来表示,这个就是Word Embedding的含义。
当然,词跟颜色还是有很大的差别的——我们已经知道表示颜色的三个维度有明确对应的物理意义(即RGB),直接使用物理原理就可以知道某一个颜色对应的RGB是多少。但是对于词,我们无法给出每个维度所具备的可解释的意义,也无法直接求出一个词的词向量的值应该是多少。所以我们需要使用语料和模型来训练词向量——把嵌入矩阵当成模型参数的一部分,通过词与词间的共现或上下文关系来优化模型参数,最后得到的矩阵就是词表中所有词的词向量。
这里需要说明的是,有的初学者可能没绕过一个弯,就是“最初的词向量是怎么来的”——其实你只要知道最初的词向量是随机初始化的就行了。嵌入矩阵最初的参数跟模型参数一样是随机初始化的,然后前向传播计算损失函数,反向传播求嵌入矩阵里各个参数的导数,再梯度下降更新,这个跟一般的模型训练都是一样的。等训练得差不多的时候,嵌入矩阵就是比较准确的词向量矩阵了
1:代码部分导入模块
import matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sklearnimport pandas as pdimport osimport sysimport timeimport tensorflow as tffrom tensorflow import kerasprint(tf.__version__)print(sys.version_info)for module in mpl, np, pd, sklearn, tf, keras:print(module.__name__, module.__version__)
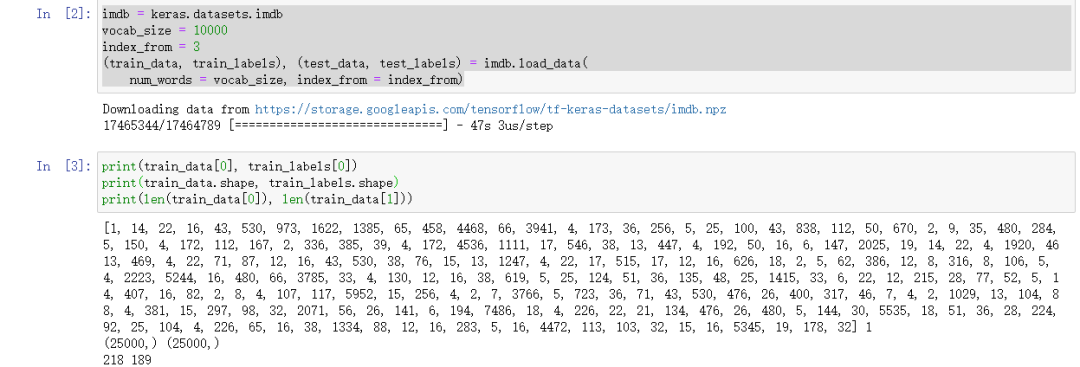
2. 读取数据 这次用的是keras自带的imdb 电影评论网站 被分为两类 positive negative.对数据集进行二分类
imdb = keras.datasets.imdbvocab_size = 10000index_from = 3(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = vocab_size, index_from = index_from
3.载入词典 key为具体的词语 value为id
word_index = imdb.get_word_index()print(len(word_index))print(word_index)

4 字符处理
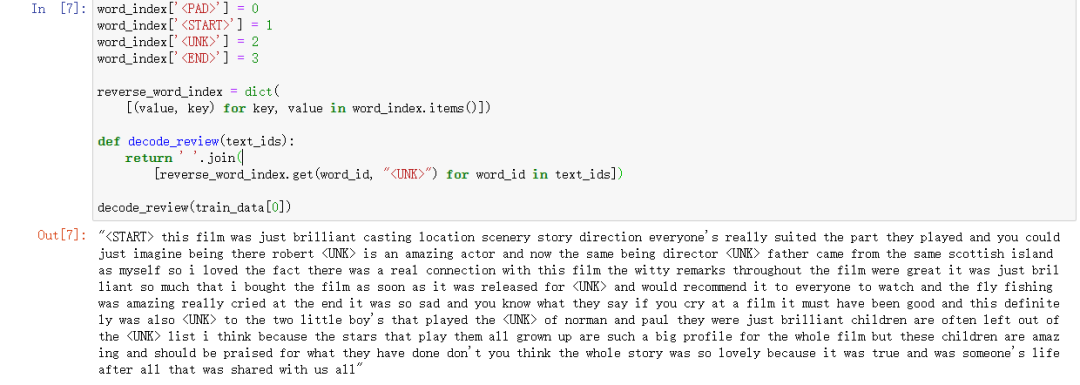
word_index['<PAD>'] = 0 是否padword_index['<START>'] = 1 开始起始字符word_index['<UNK>'] = 2 寻找字符word_index['<END>'] = 3 结束字符reverse_word_index = dict([(value, key) for key, value in word_index.items()])def decode_review(text_ids):return ' '.join([reverse_word_index.get(word_id, "<UNK>") for word_id in text_ids])decode_review(train_data[0])
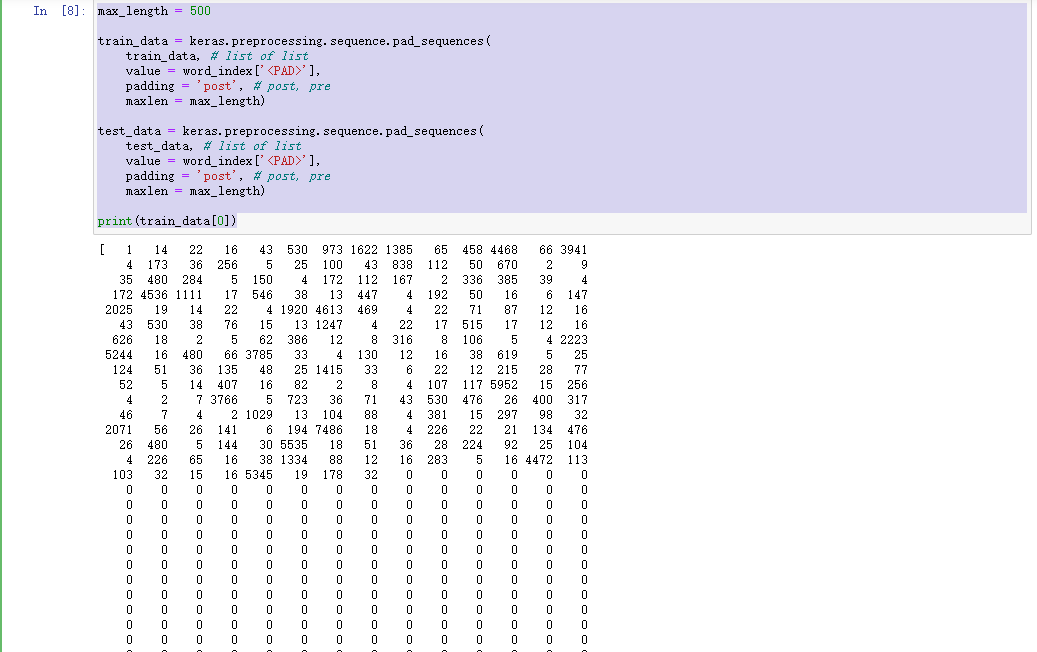
max_length = 500train_data = keras.preprocessing.sequence.pad_sequences(train_data, # list of listvalue = word_index['<PAD>'],padding = 'post', # post, premaxlen = max_length)test_data = keras.preprocessing.sequence.pad_sequences(test_data, # list of listvalue = word_index['<PAD>'],padding = 'post', # post, premaxlen = max_length)print(train_data[0])
5 定义模型
embedding_dim = 16 #每个word embedding为长度16batch_size = 128model = keras.models.Sequential([# 1. define matrix: [vocab_size, embedding_dim]# 2. [1,2,3,4..], max_length * embedding_dim# 3. batch_size * max_length * embedding_dimkeras.layers.Embedding(vocab_size, embedding_dim,input_length = max_length),# batch_size * max_length * embedding_dim# -> batch_size * embedding_dimkeras.layers.GlobalAveragePooling1D(),keras.layers.Dense(64, activation = 'relu'),keras.layers.Dense(1, activation = 'sigmoid'),])model.summary()model.compile(optimizer = 'adam', loss = 'binary_crossentropy',metrics = ['accuracy'])
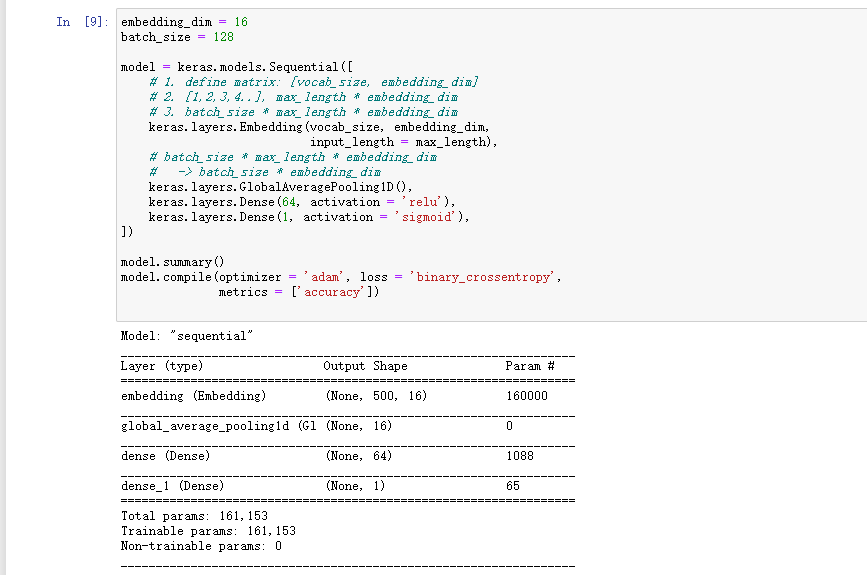
6 训练模型
history = model.fit(train_data, train_labels,epochs = 30,batch_size = batch_size,validation_split = 0.2)
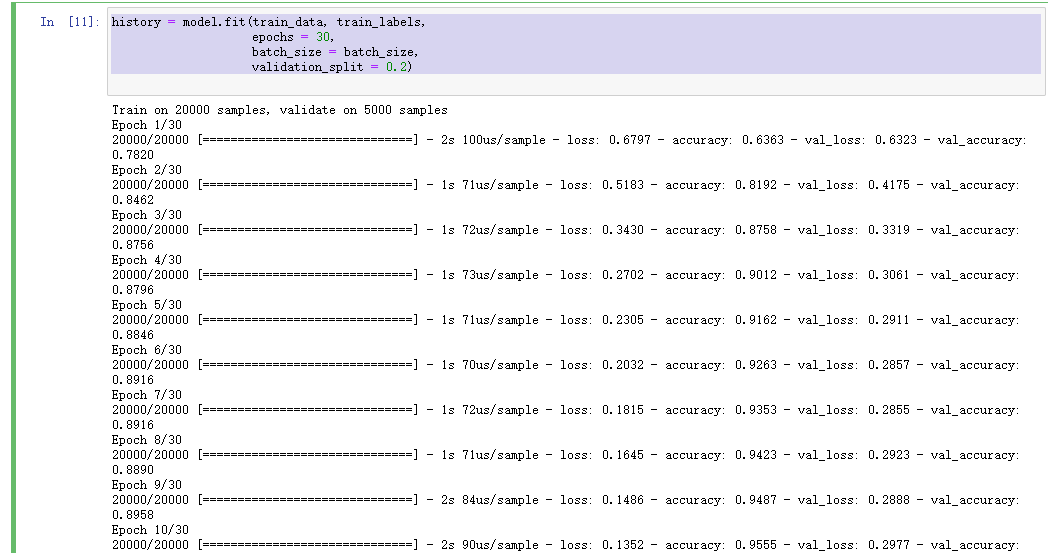
7 测试准确率
def plot_learning_curves(history, label, epochs, min_value, max_value):data = {}data[label] = history.history[label]data['val_'+label] = history.history['val_'+label]pd.DataFrame(data).plot(figsize=(8, 5))plt.grid(True)plt.axis([0, epochs, min_value, max_value])plt.show()plot_learning_curves(history, 'accuracy', 30, 0, 1)plot_learning_curves(history, 'loss', 30, 0, 1)
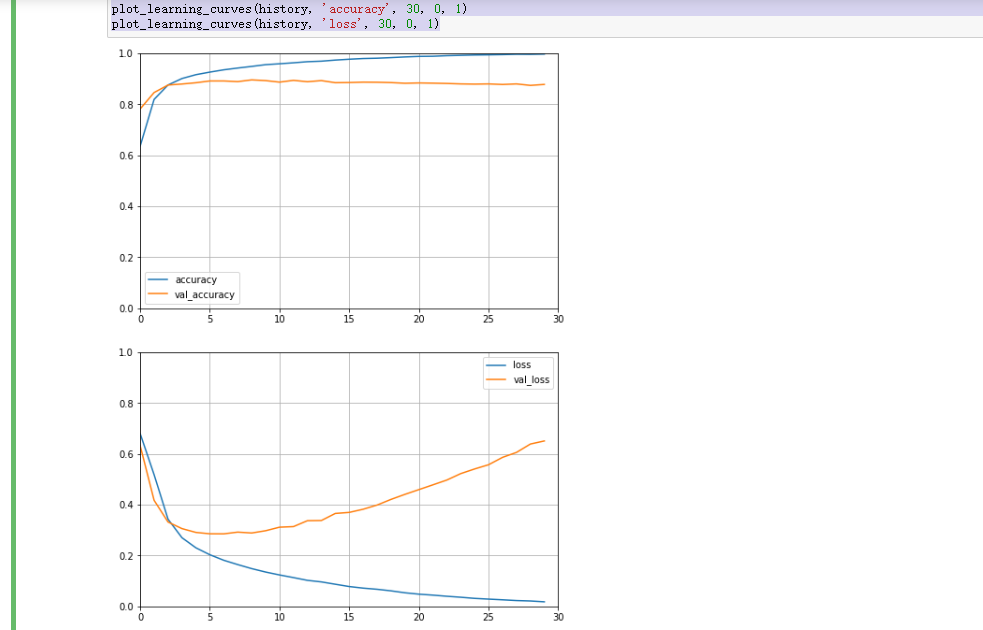


这是一个初级的embedding网络,下节课学习传统的RNN实现文本分类
