




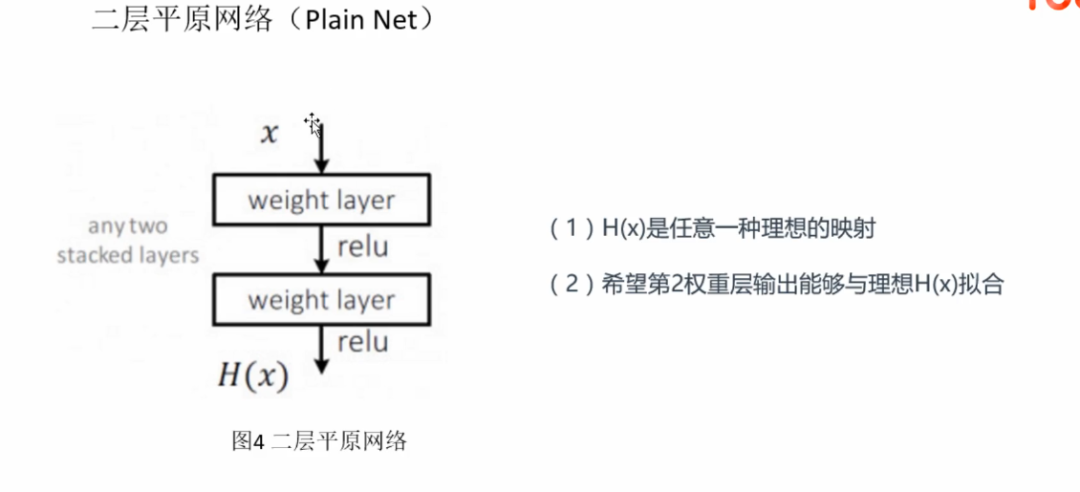
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。网络层数增多一般会伴着下面几个问题
计算资源的消耗
模型容易过拟合
梯度消失/梯度爆炸问题的产生
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batch Normalization也可以避免。貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。
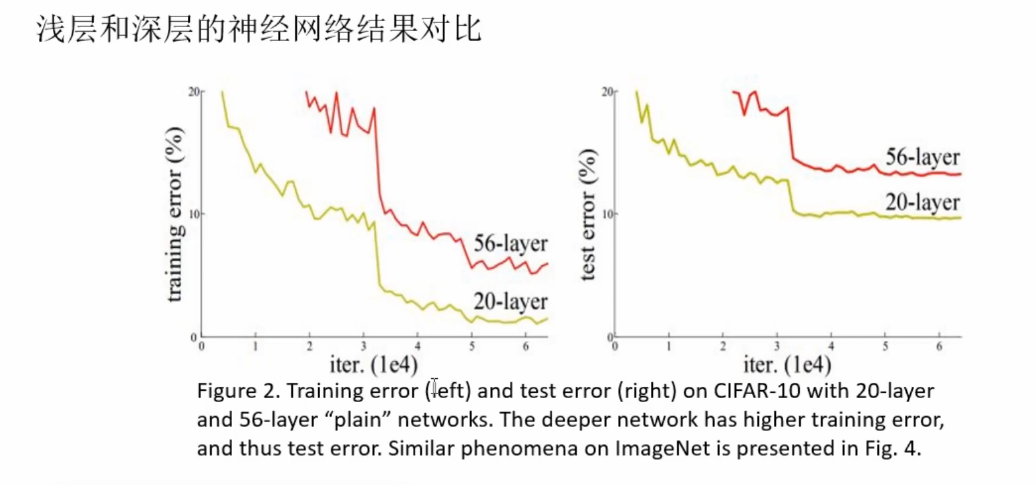
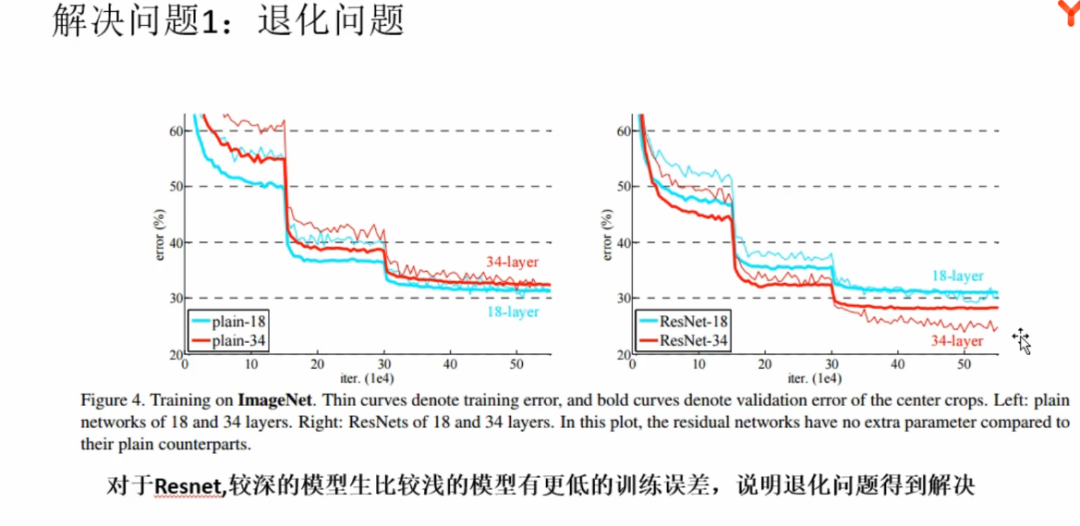
随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。当网络退化时,浅层网络能够达到比深层网络更好的训练效果
造成梯度消失的原因?
目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化,因此整个深度网络可以视为是一个复合的非线性多元函数。

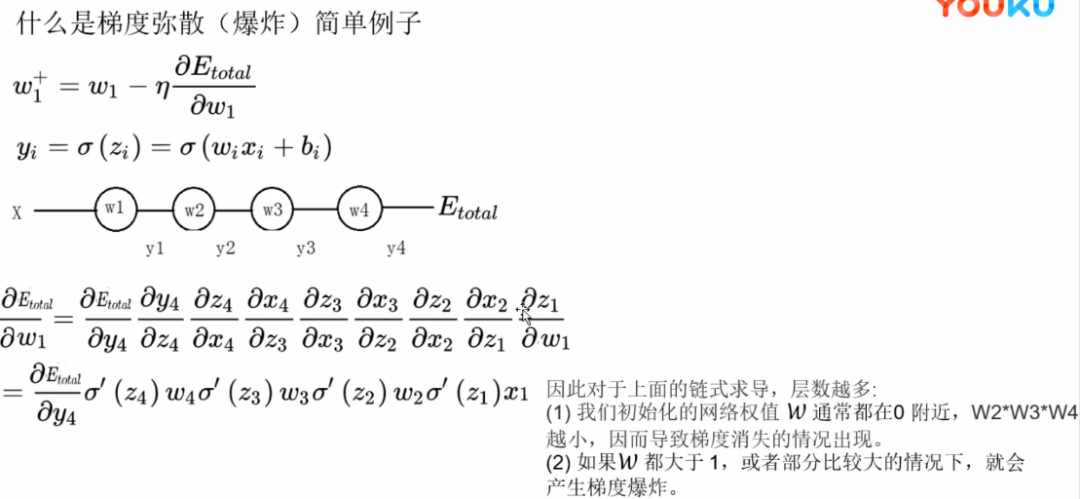
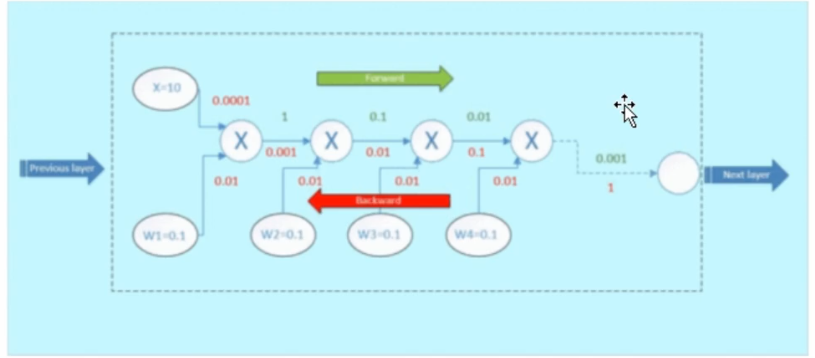
梯度消失与梯度爆炸其实是比较类似。
(1)深层网络角度
对激活函数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
(2)激活函数角度
计算权值更新信息的时候需要计算前层偏导信息,因此如果激活函数选择不合适,比如使用sigmoid,梯度消失就会很明显了,原因看下图,左图是sigmoid 的损失函数图,右边是其倒数的图像,如果使用sigmoid 作为损失函数,其梯度是不可能超过0.25 的,这样经过链式求导之后,很容易发生梯度消失。
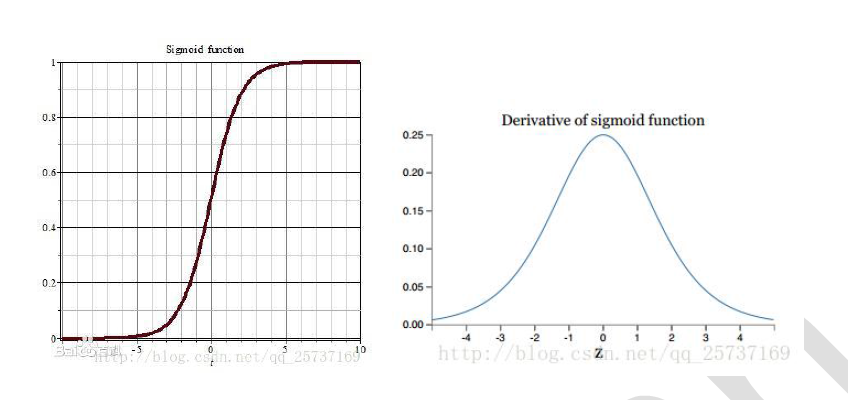
梯度消失和爆炸的的问题本质上是激活函数的偏导数在链式求导中累乘导致越来越小或者越来越大。还有很多数学公式我就不在这列举了。
梯度消失、爆炸的解决方案
方案1-预训练加微调
方案2-梯度剪切、正则
方案3-relu、leakrelu、elu 等激活函数
relu 的主要贡献在于:
(1)解决了梯度消失、爆炸的问题
(2)计算方便,计算速度快
(3)加速了网络的训练
同时也存在一些缺点:
(1)由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
(2)输出不是以0 为中心的
leakrelu
leakrelu 就是为了解决relu 的0 区间带来的影响, 其数学表达为:
leakrelu=max(k∗ x,0)其中k 是leak 系数,一般选择0.01 或者0.02,或者通过学习而来
方案4-batchnorm:
Batchnorm 是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm 本质上是解决反向传播过程中的梯度问题。batchnorm 全名是batchnormalization,简称BN,即批规范化,通过规范化操作将输出信号x 规范化到均值为0,方差为1 保证网络的稳定性。


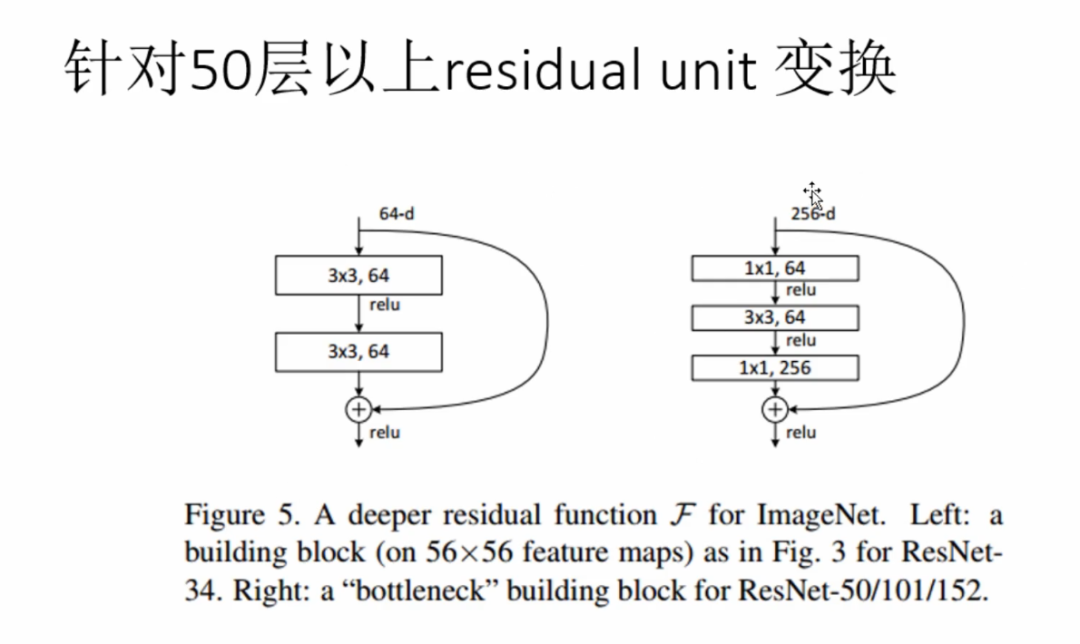
方案5-残差结构
事实上,就是残差网络的出现导致了image net比赛的终结,自从残差提出后,几乎所有的深度网络都离不开残差的身影,相比较之前的几层,几十层的深度网络,在残差网络面前都不值一提,残差可以很轻松的构建几百层,一千多层的网络而不用担心梯度消失过快的问题,原因就在于残差的捷径(shortcut)部分.
今天就主要学习一下残差网络的结构模型。

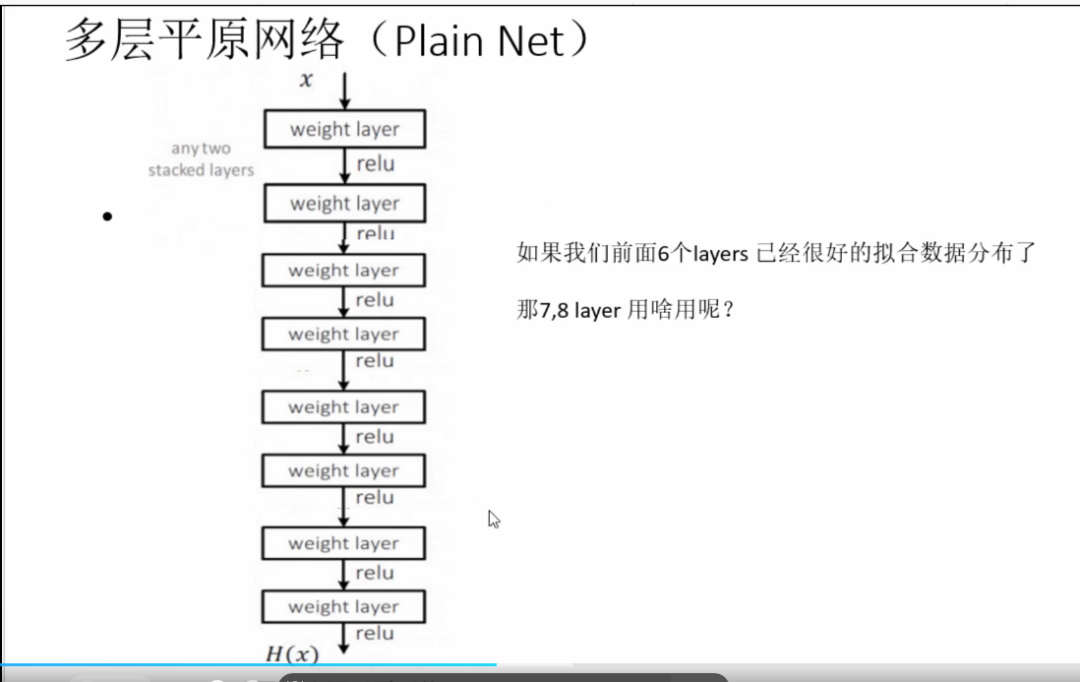
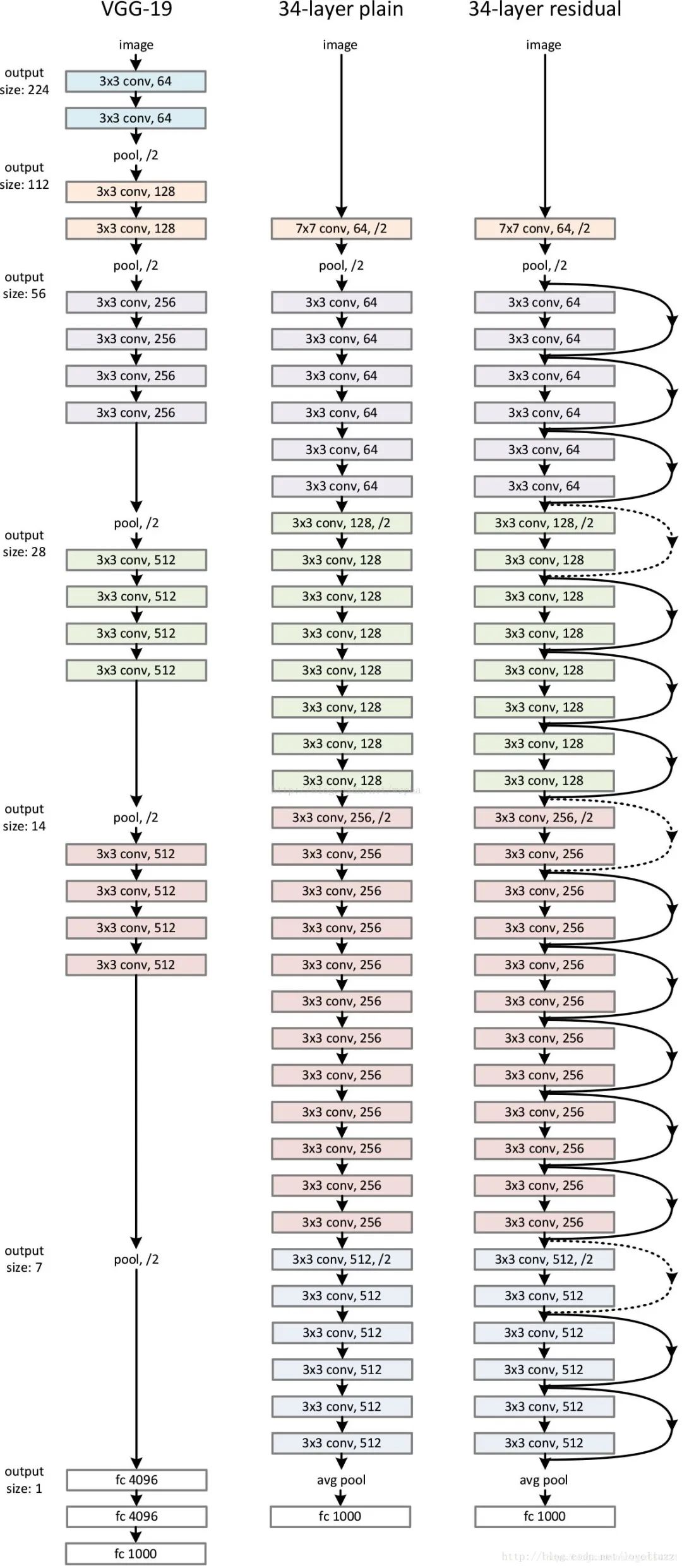
举个例子,假设已经有了一个最优化的网络结构,图左边。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设为18层,设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这五部分为恒等映射,也就是经过这层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
论文中的结果。

1. 残差网络
1.1 残差块
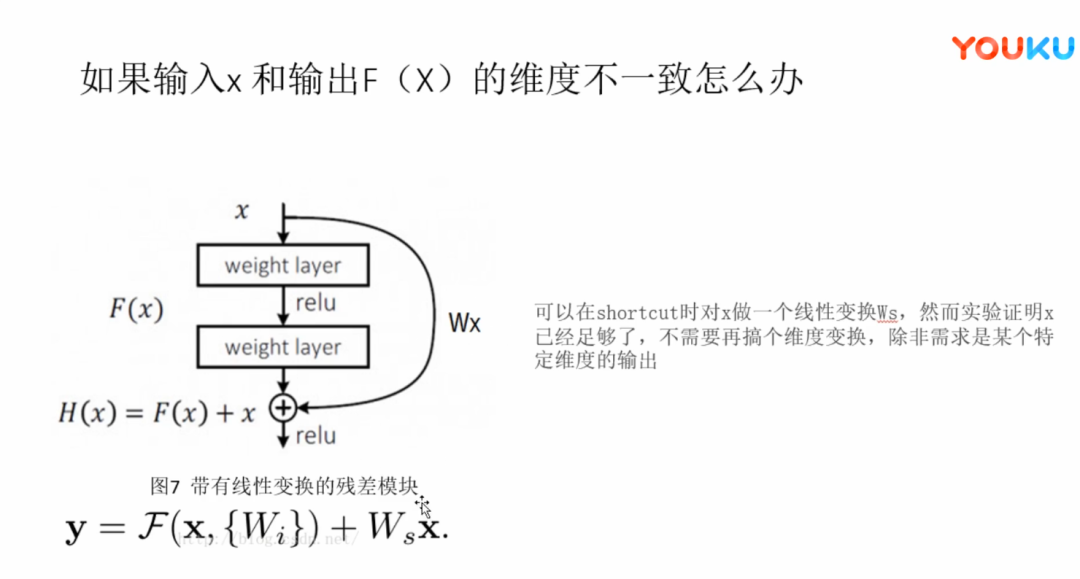
残差网络是由一系列残差块组成的(图1)。一个残差块可以用表示为:
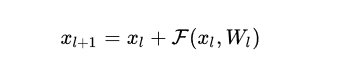
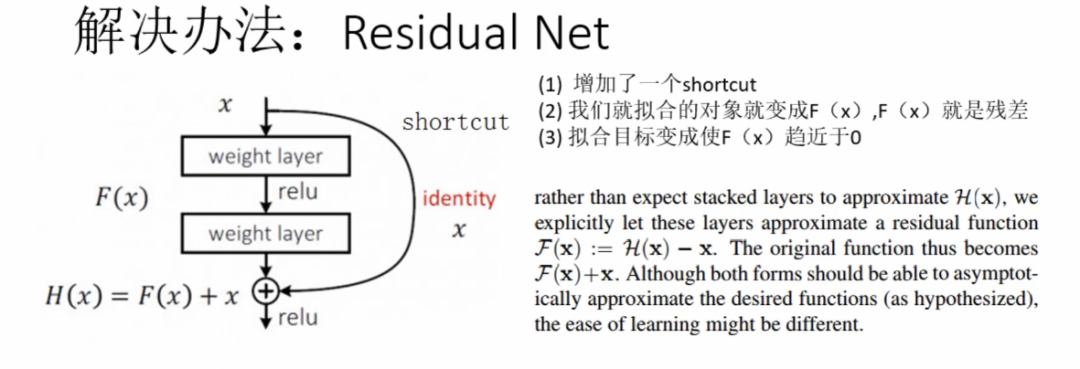
在引入ResNet之前,我们想让该层学习到的参数能够满足h(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是可以看见,要想学习h(x)=x恒等映射时的这层参数时比较困难的。ResNet想到避免去学习该层恒等映射的参数,使用了如上图的结构,让h(x)=F(x)+x;这里的F(x)我们称作残差项,我们发现,要想让该冗余层能够恒等映射,我们只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛。

由于h(x)=F(x)+x,由于链式求导后的结果如图所示,不管括号内右边部分的求导参数有多小,因为左边的1的存在,并且将原来的链式求导中的连乘变成了连加状态(正是 ),都能保证该节点参数更新不会发生梯度消失或梯度爆炸现象。


1. 代码部分
1. 导入模块
%matplotlib inlineimport matplotlib as mplimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport sklearnimport os,sysimport tensorflow as tfimport timefrom tensorflow import kerasprint(tf.__version__)print(sys.version_info)for module in mpl,pd,sklearn,tf,keras:print(module.__name__,module.__version__)
2. 文件读取
# 文件路径train_dir = '../input/10-monkey-species/training/training'valid_dir = "../input/10-monkey-species/validation/validation"label_file = '../input/10-monkey-species/monkey_labels.txt'print(os.path.exists(train_dir))print(os.path.exists(valid_dir))print(os.path.exists(label_file))print(os.listdir(train_dir))print(os.listdir(valid_dir))
# 读取图片height = 224width = 224channels = 3batch_size = 24num_classes = 10train_datagen = keras.preprocessing.image.ImageDataGenerator(preprocessing_function=keras.applications.resnet50.preprocess_input, # 归一化rotation_range=40,width_shift_range=0.2,height_shift_range = 0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip = True,fill_mode = 'nearest',)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(height,width),batch_size=batch_size,seed=7,shuffle=True,class_mode="categorical")valid_datagen = keras.preprocessing.image.ImageDataGenerator( preprocessing_function=keras.applications.resnet50.preprocess_input)valid_generator = valid_datagen.flow_from_directory(valid_dir,target_size=(height,width),batch_size=batch_size,seed=7,shuffle=False,class_mode="categorical")train_num = train_generator.samplesvalid_num = valid_generator.samplesprint(train_num,valid_num)
3. 构建模型
resnet50_fine_tune = keras.models.Sequential()resnet50_fine_tune.add(keras.applications.ResNet50(include_top=False,pooling='avg',weights='imagenet'))resnet50_fine_tune.add(keras.layers.Dense(num_classes,activation='softmax'))resnet50_fine_tune.layers[0].trainable=Falseresnet50_fine_tune.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])resnet50_fine_tune.summary()
4. 训练
epochs = 10history = resnet50_fine_tune.fit_generator(train_generator,steps_per_epoch = train_num // batch_size,epochs=epochs,validation_data = valid_generator,validation_steps=valid_num // batch_size)

5. 学习曲线
# 学习曲线def plot_learning_curves(hsitory,label,epochs,min_value,max_value):data = {}data[label] = history.history[label]data['val_' + label] = hsitory.history['val_' + label]pd.DataFrame(data).plot(figsize=(8,5))plt.grid(True)plt.axis([0,epochs,min_value,max_value])plt.show()plot_learning_curves(history,'accuracy',epochs,0,1)plot_learning_curves(history,'loss',epochs,0,2)

