常规卷积操作
对于一张5×5像素、三通道(shape为5×5×3)图像,经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),
如果没有 则图像为尺寸变为3×3
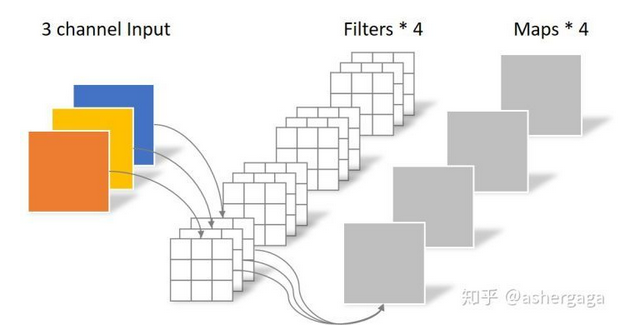 卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积分为两步
(1)逐通道卷积
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
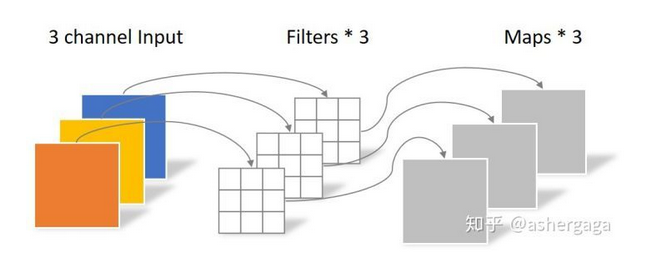
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。
而这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要第二步逐点卷积Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
(2)逐点卷积(Pointwise Convolution)
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
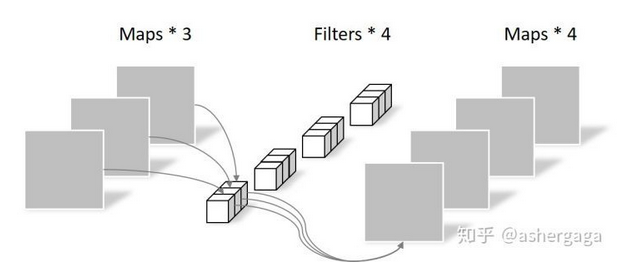
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同.
两种不同方式的 参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,深度可分离卷积的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。

DF图像尺寸。

深度可分离卷积实战。
import matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sklearnimport pandas as pdimport osimport sysimport timeimport tensorflow as tffrom tensorflow import kerasos.environ['CUDA_VISIBLE_DEVICES'] = '/gpu:0'print(tf.__version__)print(sys.version_info)for module in mpl,np,pd,sklearn,tf,keras:print(module.__name__,module.__version__)
2. 读取数据 还是mnist数据集
fashion_mnist = keras.datasets.fashion_mnist# print(fashion_mnist)(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data()x_valid,x_train = x_train_all[:5000],x_train_all[5000:]y_valid,y_train = y_train_all[:5000],y_train_all[5000:]# 打印格式print(x_valid.shape,y_valid.shape)print(x_train.shape,y_train.shape)print(x_test.shape,y_test.shape)
3. 数据归一化
# 数据归一化from sklearn.preprocessing import StandardScalerscaler = StandardScaler()# x_train:[None,28,28] -> [None,784]x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1)x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1)x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1)
4. 构建模型
model = keras.models.Sequential()#一般在输入层使用普通卷积 输入层之后 使用深度可分离卷积。model.add(keras.layers.Conv2D(filters=32, kernel_size=3,padding='same',activation='selu',input_shape=(28, 28, 1)))model.add(keras.layers.SeparableConv2D(filters=32, kernel_size=3,padding='same',activation='selu'))model.add(keras.layers.MaxPool2D(pool_size=2))model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3,padding='same',activation='selu'))model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3,padding='same',activation='selu'))model.add(keras.layers.MaxPool2D(pool_size=2))model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3,padding='same',activation='selu'))model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3,padding='same',activation='selu'))model.add(keras.layers.MaxPool2D(pool_size=2))model.add(keras.layers.Flatten())model.add(keras.layers.Dense(128, activation='selu'))model.add(keras.layers.Dense(10, activation="softmax"))model.compile(loss="sparse_categorical_crossentropy",optimizer = "sgd",metrics = ["accuracy"])

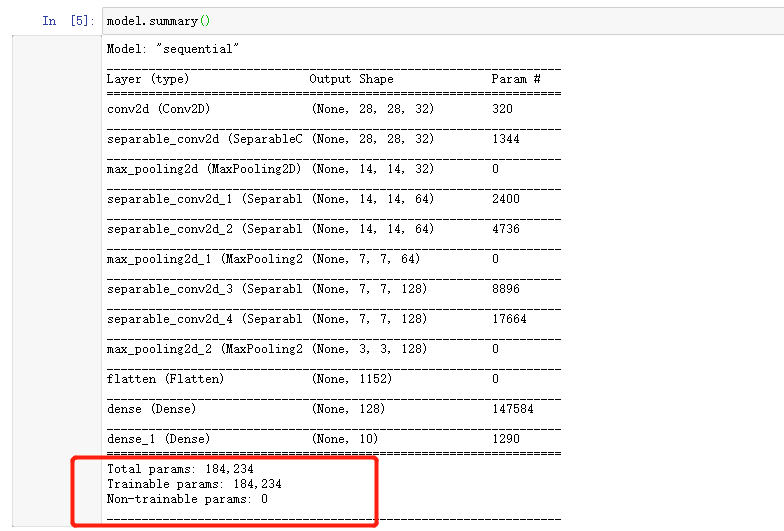
可以看到参数由43万变成了18万
5. 开始训练 时间比较久
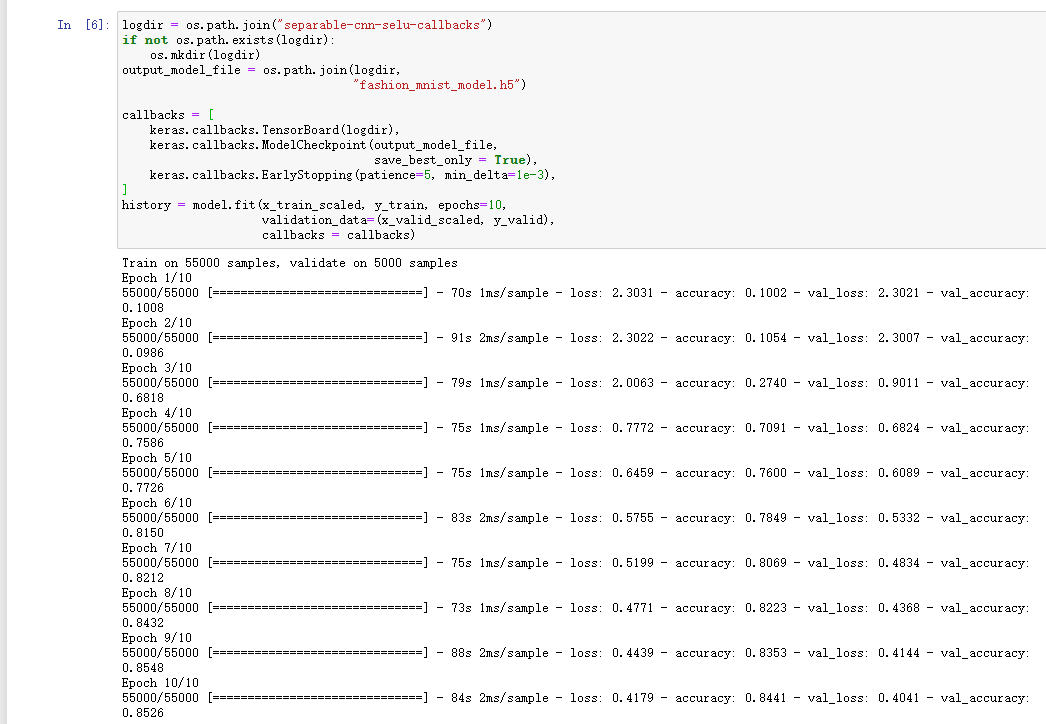
# 回调函数 Tensorboard(文件夹)\earylystopping\ModelCheckpoint(文件名)logdir = os.path.join("separable_cnn-selu-callbacks")print(logdir)if not os.path.exists(logdir):os.mkdir(logdir)# 文件名output_model_file = os.path.join(logdir,"fashion_mnist_model.h5")callbacks = [keras.callbacks.TensorBoard(logdir),keras.callbacks.ModelCheckpoint(output_model_file,save_best_only=True),keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3),]# 开始训练history = model.fit(x_train_scaled,y_train,epochs=10,validation_data=(x_valid_scaled,y_valid),callbacks=callbacks)
6. 学习曲线
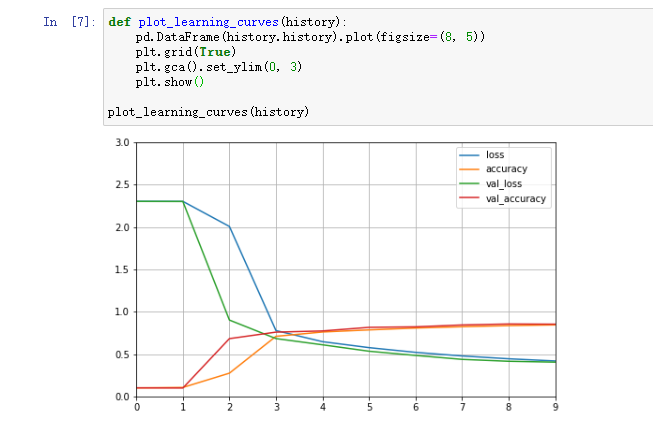
# 画图def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize=(8,5))plt.grid(True)plt.gca().set_ylim(0,1)plt.show()plot_learning_curves(history)
7. 测试集上
model.evaluate(x_test_scaled,y_test)
kaggle实战. 10monkeys.
kaggle是一个机器学习的实战平台.这次使用的数据集是10monkeys
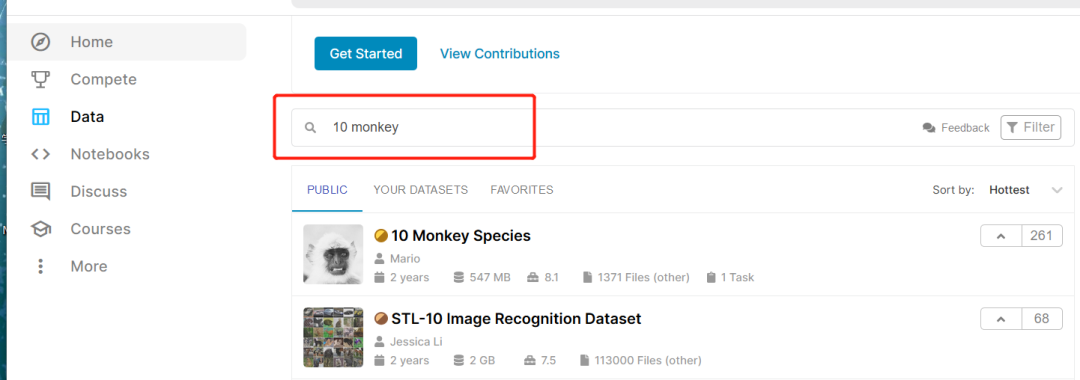
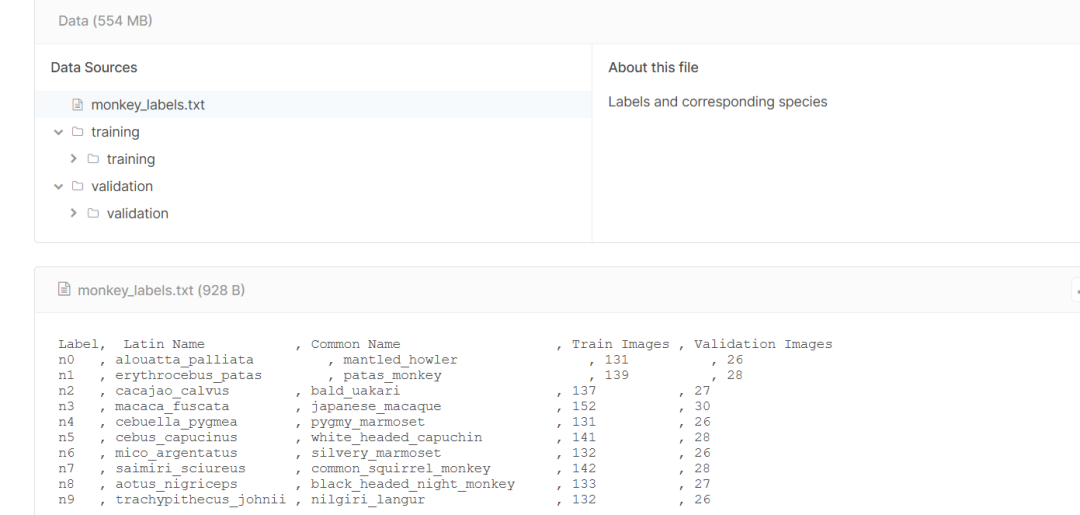
可以查看数据集的信息
第一部分:导入模块
%matplotlib inlineimport matplotlib as mplimport matplotlib.pyplot as lptimport numpy as npimport pandas as pdimport sklearnimport os,sysimport tensorflow as tfimport timefrom tensorflow import kerasprint(tf.__version__)print(sys.version_info)for module in mpl,pd,sklearn,tf,keras:print(module.__name__,module.__version__)
2. 文件路径
# 文件路径train_dir = '../input/10-monkey-species/training/training'valid_dir = "../input/10-monkey-species/validation/validation"label_file = '../input/10-monkey-species/monkey_labels.txt'print(os.path.exists(train_dir))print(os.path.exists(valid_dir))print(os.path.exists(label_file))print(os.listdir(train_dir))print(os.listdir(valid_dir))
3. 读取数据
3.1 读取标签
labels = pd.read_csv(label_file, header=0)print(labels)
3.2 读取图片 这里在读取图片的时候和之前 有些区别 记录一下
之前都是用tf.dataset 这次在keras上有更高层的封装keras.preprocessing.image.ImageDataGenerator
可以对图像做预处理。data augmentation。
例如,可以对已有的图片进行水平翻转、垂直翻转、任意角度旋转、缩放或扩大等等。如下图所示,这些处理都能“制造”出新的训练样本。虽然这样会使训练集产生冗余,不如额外收集一组新图片好,但是不需要增加额外成本,除了产生一些对抗性。也能起到防止过拟合的效果。
简单讲解一下参数。
rescale 将图像从0-255 转换为 0-1
rotarion_range 图像增强的一种方法 随机旋转的角度值
width_shift_range 水平方向位移 像素值
height_shift_range 垂直方向位移
shear_range 剪切强度
zoom_range 缩放强度
horizontal_flip = True, 是否做水平翻转
fill_mode = 'nearest', 自动填充像素规则 最近
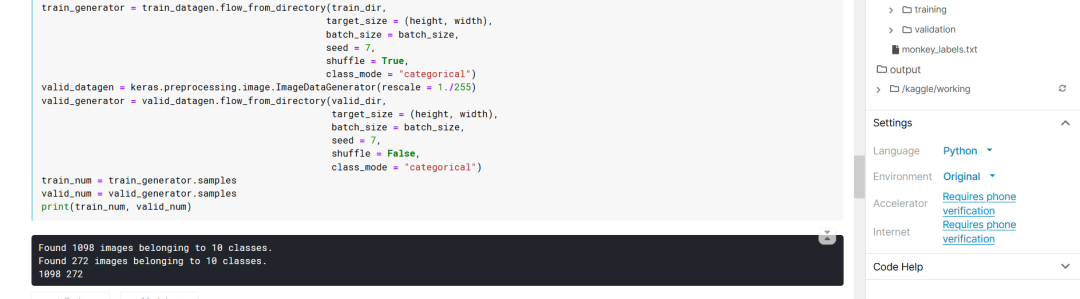
# 读取图片height = 128width = 128channels = 3batch_size = 64num_classes = 10train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale = 1. / 255,rotation_range=40,width_shift_range=0.2,height_shift_range = 0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip = True,fill_mode = 'nearest',)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(height,width),batch_size=batch_size,seed=7,shuffle=True,class_mode="categorical")valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255)valid_generator = valid_datagen.flow_from_directory(valid_dir,target_size=(height,width),batch_size=batch_size,seed=7,shuffle=False,class_mode="categorical")trian_num = train_generator.samplesvalid_num = valid_generator.samplesprint(trian_num,valid_num)
4. 构建模型
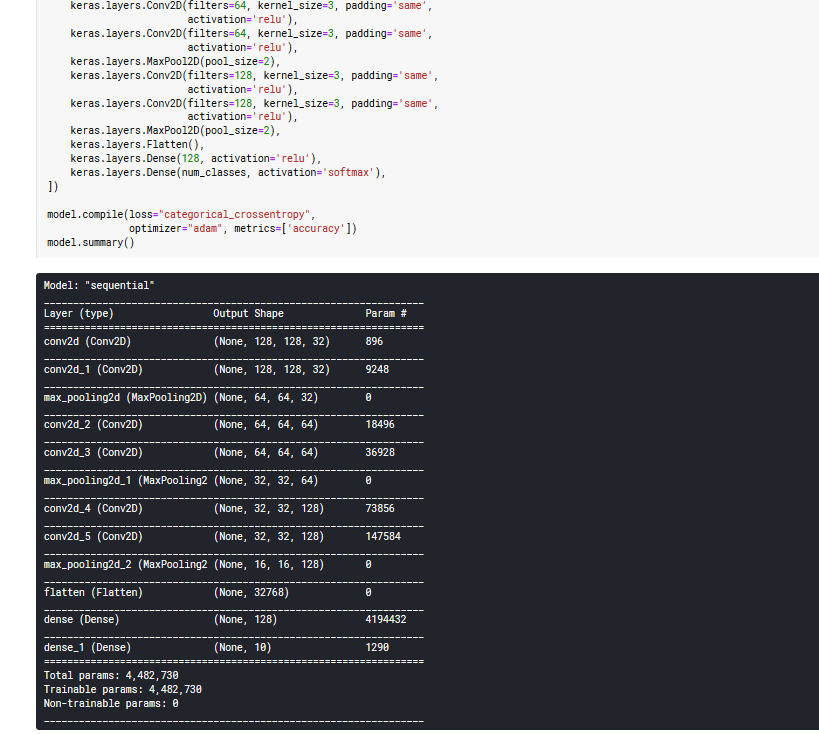
model = keras.models.Sequential([keras.layers.Conv2D(filters=32,kernel_size=3,padding='same',activation='relu',input_shape=[width,height,channels]),keras.layers.Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),keras.layers.MaxPool2D(pool_size=2),keras.layers.Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),keras.layers.Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),keras.layers.MaxPool2D(pool_size=2),keras.layers.Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),keras.layers.Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),keras.layers.MaxPool2D(pool_size=2),# 展平keras.layers.Flatten(),keras.layers.Dense(128,activation='relu'),keras.layers.Dense(num_classes,activation='softmax'),])model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])model.summary()
5. 没有gpu 训练 很久 我的电脑10个epoch大概 40分钟
epochs = 10history = model.fit_generator(train_generator,steps_per_epoch = train_num // batch_size,epochs=epochs,validation_data = valid_generator,validation_steps=valid_num // batch_size)
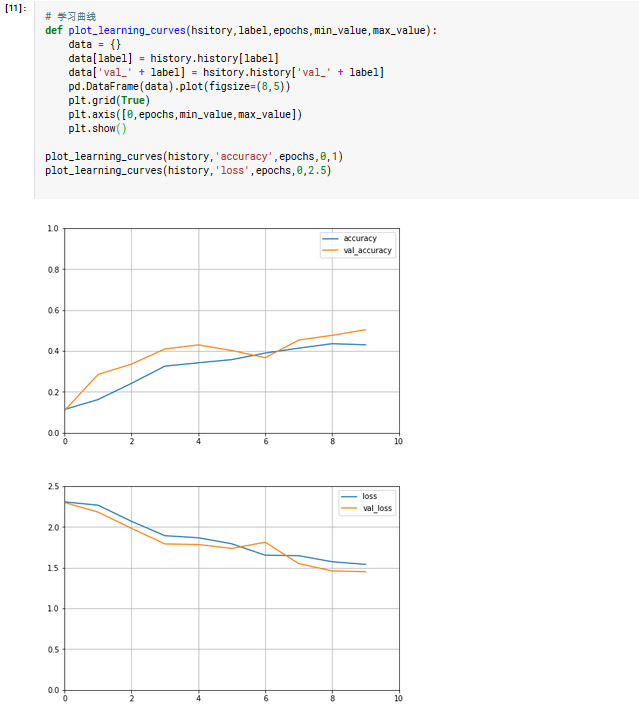
6. 学习曲线
# 学习曲线def plot_learning_curves(hsitory,label,epochs,min_value,max_value):data = {}data[label] = history.history[label]data['val_' + label] = hsitory.history['val_' + label]pd.DataFrame(data).plot(figsize=(8,5))plt.grid(True)plt.axis([0,epochs,min_value,max_value])plt.show()plot_learning_curves(history,'accuracy',epochs,0,1)plot_learning_curves(history,'loss',epochs,0,2.5)