




今天科技大涨 总有种把猪骗进来杀的感觉 ,趁着昨天 前天大跌捞了一点 今天上涨跑了大部分 外围应该会疫情二次爆发 美股二次探底 后面应该不是 暴跌而是连续不断阴跌了 难熬啊。 左侧的话 A股不到2600 仓位不要超过50% 右侧的话 突破3000 二次回踩有效 再满仓吧
本节,tfrecord基础API的使用

1. 导入模块
import matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sklearnimport pandas as pdimport osimport sysimport timeimport tensorflow as tffrom tensorflow import keras
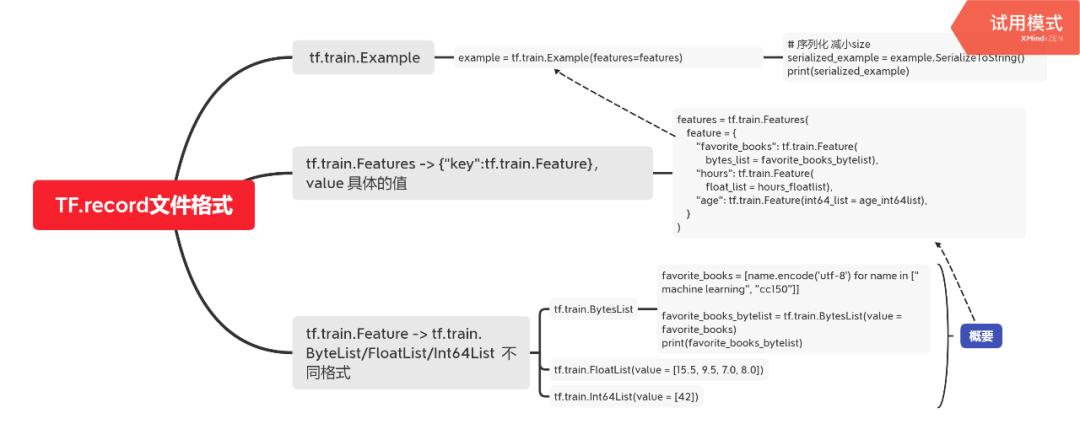
2. tfrecord文件格式
tfrecord 文件格式
-> tf.train.Example
-> tf.train.Features -> {“key”:tf.train.Feature},value 具体的值
-> tf.train.Feature -> tf.train.ByteList/FloatList/Int64List 不同格式
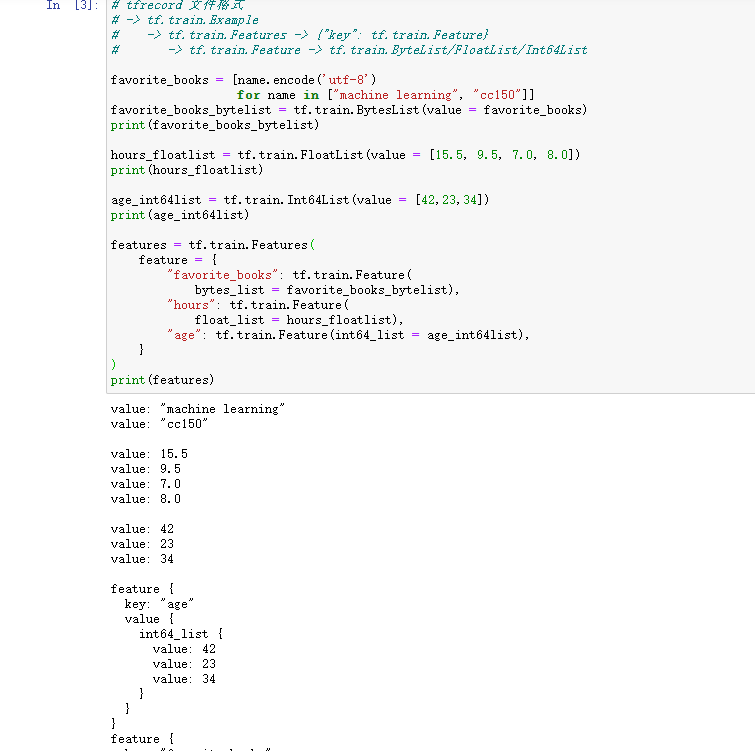
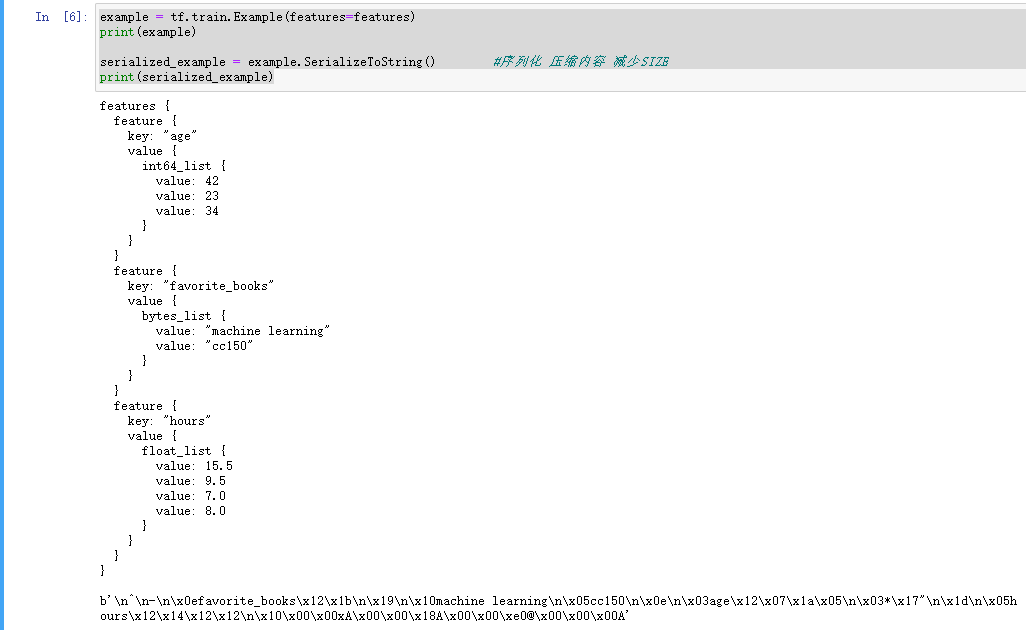
# tfrecord 文件格式# -> tf.train.Example# -> tf.train.Features -> {"key": tf.train.Feature}# -> tf.train.Feature -> tf.train.ByteList/FloatList/Int64Listfavorite_books = [name.encode('utf-8') for name in ["machine learning", "cc150"]]favorite_books_bytelist = tf.train.BytesList(value = favorite_books)print(favorite_books_bytelist)hours_floatlist = tf.train.FloatList(value = [15.5, 9.5, 7.0, 8.0])print(hours_floatlist)age_int64list = tf.train.Int64List(value = [42])print(age_int64list)features = tf.train.Features(feature = {"favorite_books": tf.train.Feature(bytes_list = favorite_books_bytelist),"hours": tf.train.Feature(float_list = hours_floatlist),"age": tf.train.Feature(int64_list = age_int64list),})print(features)
example = tf.train.Example(features=features)print(example)
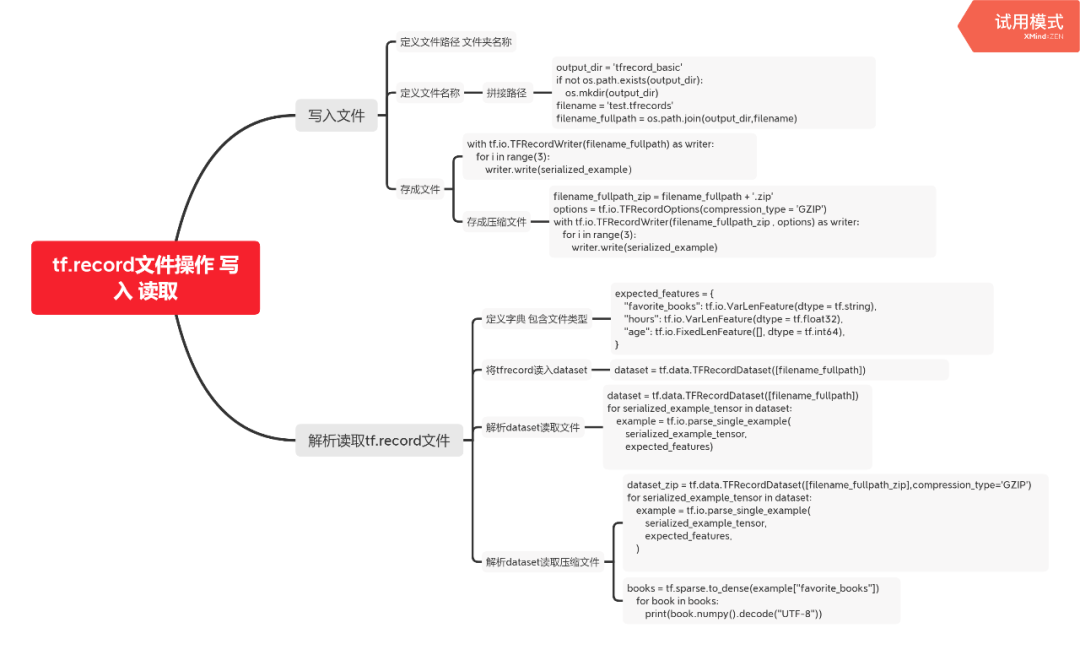
3. 写入文件
output_dir = 'tfrecord_basic'if not os.path.exists(output_dir):os.mkdir(output_dir)filename = 'test.tfrecords'filename_fullpath = os.path.join(output_dir,filename)with tf.io.TFRecordWriter(filename_fullpath) as writer:for i in range(3):writer.write(serialized_example)
4. 读取文件
# 读取文件dataset = tf.data.TFRecordDataset([filename_fullpath]) #生成datasetfor serialized_example_tensor in dataset:print(serialized_example_tensor)

5. 解析
tf.io.VarLenFeature #变长类型tf.io.FixedLenFeature # 定长类型
expected_features = {"favorite_books": tf.io.VarLenFeature(dtype = tf.string),"hours": tf.io.VarLenFeature(dtype = tf.float32),"age": tf.io.FixedLenFeature([], dtype = tf.int64),}dataset = tf.data.TFRecordDataset([filename_fullpath])for serialized_example_tensor in dataset:example = tf.io.parse_single_example(serialized_example_tensor,expected_features)books = tf.sparse.to_dense(example["favorite_books"],default_value=b"")for book in books:print(book.numpy().decode("UTF-8"))
6. 存成压缩文件
# 存成压缩文件filename_fullpath_zip = filename_fullpath + '.zip'options = tf.io.TFRecordOptions(compression_type = 'GZIP')with tf.io.TFRecordWriter(filename_fullpath_zip , options) as writer:for i in range(3):writer.write(serialized_example)

7. 读取压缩文件
# 读取压缩文件dataset_zip = tf.data.TFRecordDataset([filename_fullpath_zip],compression_type='GZIP')for serialized_example_tensor in dataset:example = tf.io.parse_single_example(serialized_example_tensor,expected_features,)# print(example)# 解析books :sparse_tensorbooks = tf.sparse.to_dense(example["favorite_books"])for book in books:print(book.numpy().decode("UTF-8"))

从CSV生成tfrecords文件
用的上上节课生成的数据集
2. 读取文件 根据文件前缀名生成不同路径
source_dir = './generate_csv/'print(os.listdir(source_dir))# 读取文件名def get_filenames_by_prefix(source_dir,prefix_name):all_files = os.listdir(source_dir)results = []for filename in all_files:if filename.startswith(prefix_name):results.append(os.path.join(source_dir,filename))return resultstrain_filenames = get_filenames_by_prefix(source_dir,'train')valid_filenames = get_filenames_by_prefix(source_dir,'valid')test_filenames = get_filenames_by_prefix(source_dir,'test')import pprintpprint.pprint(train_filenames)pprint.pprint(valid_filenames)pprint.pprint(test_filenames)
3. 从csv中读取文件
# 解析dataset 中的一行def parse_csv_line(line,n_fields=9):defs = [tf.constant(np.nan)] * n_fieldsparsed_fields = tf.io.decode_csv(line,record_defaults=defs)x = tf.stack(parsed_fields[0:-1])y = tf.stack(parsed_fields[-1:])return x,y
def csv_reader_dataset(filenames,n_readers=5,batch_size=32,n_parse_threads=5,shuffle_buffer_size=10000):# 1. filename -> datasetdataset = tf.data.Dataset.list_files(filenames)dataset = dataset.repeat() # 重复多少次# 文件名转换成文本内容dataset = dataset.interleave(lambda filename:tf.data.TextLineDataset(filename).skip(1),cycle_length = n_readers)dataset.shuffle(shuffle_buffer_size)# 解析dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads)dataset = dataset.batch(batch_size)return dataset
batch_size = 32train_set = csv_reader_dataset(train_filenames,batch_size=batch_size)valid_set = csv_reader_dataset(valid_filenames,batch_size=batch_size)test_set = csv_reader_dataset(test_filenames,batch_size=batch_size)
4. 数据写入tf.record
# 将数据写入tf.recorddef serialize_example(x,y):""" Converts x,y to tf.train.Example eand serialize"""input_features = tf.train.FloatList(value = x)label = tf.train.FloatList(value = y)# 转成featurefeatures = tf.train.Features(feature = {"input_features":tf.train.Feature(float_list = input_features),"label":tf.train.Feature(float_list = label)})# 转成exampleexample = tf.train.Example(features = features)return example.SerializeToString() # 序列化def csv_dataset_to_tfrecords(base_filename,dataset,n_shards,steps_per_shard,compression_type=None):options = tf.io.TFRecordOptions(compression_type = compression_type)all_filenames = []for shard_id in range(n_shards):filename_fullpath = '{}_{:05d}-of-{:05d}'.format(base_filename,shard_id,n_shards)with tf.io.TFRecordWriter(filename_fullpath,options) as writer:for x_batch,y_batch in dataset.take(steps_per_shard):for x_example,y_example in zip(x_batch,y_batch):writer.write(serialize_example(x_example,y_example))all_filenames.append(filename_fullpath)return all_filenames
n_shards = 20train_steps_per_shard = 11610 // batch_size // n_shardsvalid_steps_per_shard = 3880 // batch_size // n_shardstest_steps_per_shard = 5170 // batch_size // n_shardsoutput_dir = "generate_tfrecords"if not os.path.exists(output_dir):os.mkdir(output_dir)train_basename = os.path.join(output_dir,'train')valid_basename = os.path.join(output_dir,'valid')test_basename = os.path.join(output_dir,'test')train_tfrecord_filenmaes = csv_dataset_to_tfrecords(train_basename,train_set,n_shards,train_steps_per_shard,None)valid_tfrecord_filenames = csv_dataset_to_tfrecords(valid_basename,valid_set,n_shards,valid_steps_per_shard,None)test_tfrecord_filenames = csv_dataset_to_tfrecords(test_basename,test_set,n_shards,valid_steps_per_shard,None)
4.2 生成压缩文件
# 生成压缩文件n_shards = 20train_steps_per_shard = 11610 // batch_size // n_shardsvalid_steps_per_shard = 3880 // batch_size // n_shardstest_steps_per_shard = 5170 // batch_size // n_shardsoutput_dir = "generate_tfrecords_zip"if not os.path.exists(output_dir):os.mkdir(output_dir)train_basename = os.path.join(output_dir,'train')valid_basename = os.path.join(output_dir,'valid')test_basename = os.path.join(output_dir,'test')train_tfrecord_filenmaes = csv_dataset_to_tfrecords(train_basename,train_set,n_shards,train_steps_per_shard,compression_type="GZIP")valid_tfrecord_filenames = csv_dataset_to_tfrecords(valid_basename,valid_set,n_shards,valid_steps_per_shard,compression_type="GZIP")test_tfrecord_filenames = csv_dataset_to_tfrecords(test_basename,test_set,n_shards,valid_steps_per_shard,compression_type="GZIP")
读取tfrecords文件
6.1 打印文件名
pprint.pprint(train_tfrecord_filenmaes)pprint.pprint(valid_tfrecord_filenames)pprint.pprint(test_tfrecord_filenames)
6.2 读取文件
expected_features = {"input_features":tf.io.FixedLenFeature([8],dtype=tf.float32),"label":tf.io.FixedLenFeature([1],dtype=tf.float32)}def parse_example(serialized_example):example = tf.io.parse_single_example(serialized_example,expected_features)return example["input_features"],example["label"]def tfrecords_reader_dataset(filenames,n_readers=5,batch_size=32,n_parse_threads=5,shuffle_buffer_size=10000):# 1. filename -> datasetdataset = tf.data.Dataset.list_files(filenames)dataset = dataset.repeat() # 重复多少次# 文件名转换成文本内容dataset = dataset.interleave(lambda filename:tf.data.TFRecordDataset(filename,compression_type="GZIP"),cycle_length = n_readers)dataset.shuffle(shuffle_buffer_size)# 解析dataset = dataset.map(parse_example,num_parallel_calls=n_parse_threads)dataset = dataset.batch(batch_size)return dataset
6.3 测试
batch_size = 32tfrecords_train_set = tfrecords_reader_dataset(train_tfrecord_filenmaes,batch_size=batch_size)tfrecords_valid_set = tfrecords_reader_dataset(valid_tfrecord_filenames,batch_size=batch_size)tfrecords_test_set = tfrecords_reader_dataset(test_tfrecord_filenames,batch_size=batch_size)
# 搭建模型model = keras.models.Sequential([keras.layers.Dense(30,activation='relu',input_shape=[8]),keras.layers.Dense(1),])# 打印model信息model.summary()# 编译model.compile(loss='mean_squared_error',optimizer="sgd")# 回调函数callbacks = [keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)]
#训练history = model.fit(tfrecords_train_set,validation_data=tfrecords_valid_set,steps_per_epoch=11160 // batch_size,validation_steps = 3870 // batch_size,epochs=100,callbacks=callbacks)
6.5 测试集上 我们看到是百分之30多的的准确率
model.evaluate(tfrecords_test_set,steps = 5160 // batch_size)


文章转载自量化分析之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
