




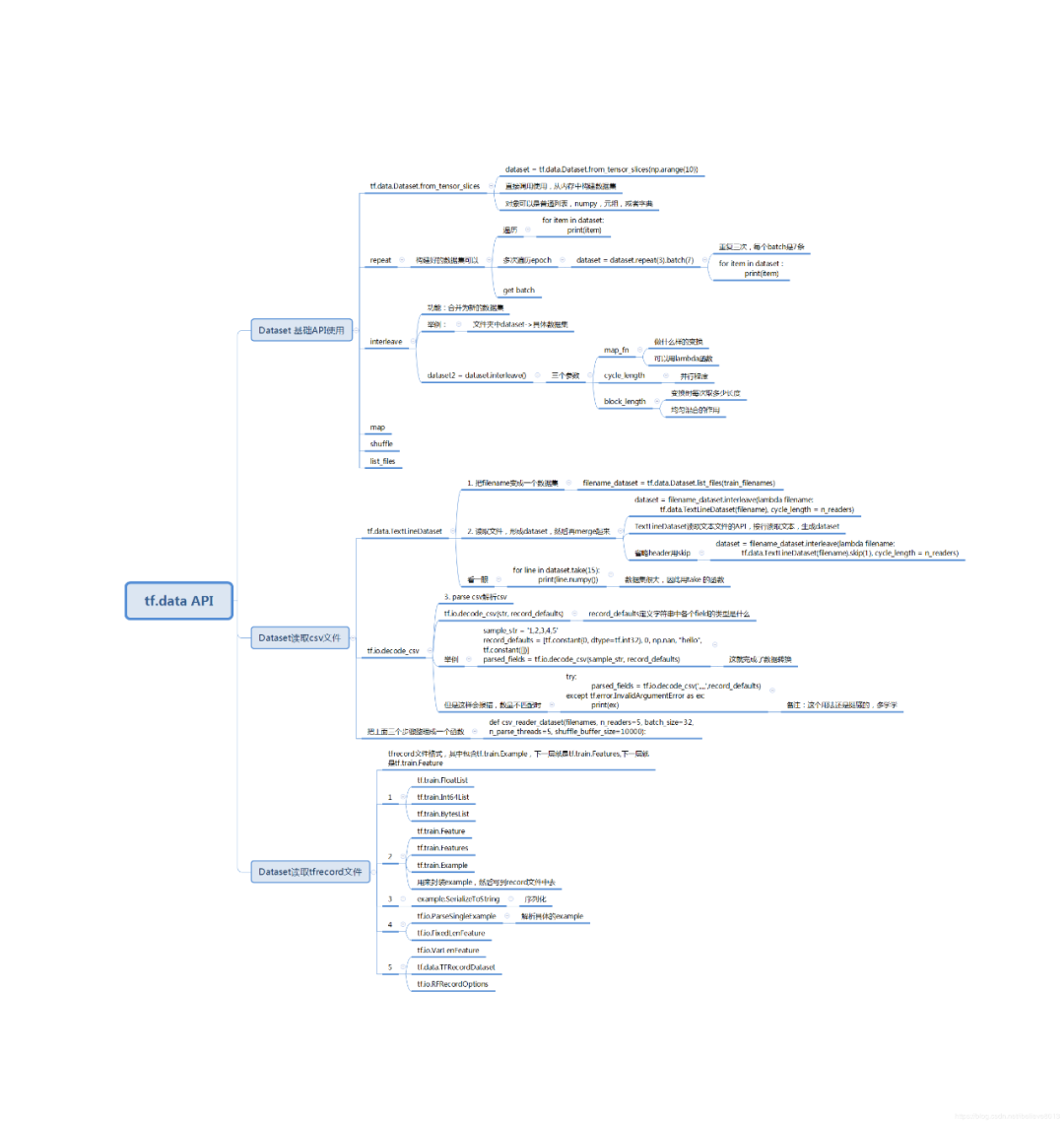
Tensorflow中之前主要用的数据读取方式主要有:
建立placeholder,然后使用feed_dict将数据feed进placeholder进行使用。使用这种方法十分灵活,可以一下子将所有数据读入内存,然后分batch进行feed;也可以建立一个Python的generator,一个batch一个batch的将数据读入,并将其feed进placeholder。这种方法很直观,用起来也比较方便灵活jian,但是这种方法的效率较低,难以满足高速计算的需求。
使用TensorFlow的QueueRunner,通过一系列的Tensor操作,将磁盘上的数据分批次读入并送入模型进行使用。这种方法效率很高,但因为其牵涉到Tensor操作,不够直观,也不方便调试,所有有时候会显得比较困难。使用这种方法时,常用的一些操作包括tf.TextLineReader,tf.FixedLengthRecordReader以及tf.decode_raw等等。如果需要循环,条件操作,还需要使用TensorFlow的tf.while_loop,tf.case等操作
Tensorflow中tf.data.Dataset是最常用的数据集类,我们可以使用这个类做转换数据、迭代数据等操作
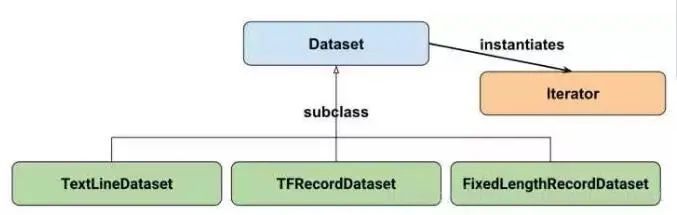
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
使用Dataset管理数据集需要首先定义数据来源,我们可以使用numpy或者tensor定义的数据作为数据来源来定义Dataset。


1. 导入模块
import matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sklearnimport pandas as pdimport osimport sysimport timeimport tensorflow as tffrom tensorflow import kerasprint(tf.__version__)print(sys.version_info)for module in mpl,np,pd,sklearn,tf,keras:print(module.__name__,module.__version__)
2. 初始化数据
# 初始化 datasetdataset = tf.data.Dataset.from_tensor_slices(np.arange(10))print(dataset)
3. 操作dataset
# 操作datasetfor item in dataset:print(item)

# 1. repeat epoch# 2. get batchdataset = dataset.repeat(3).batch(7)for item in dataset:print(item)
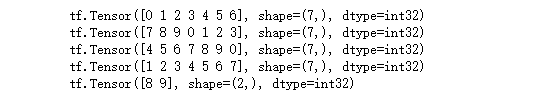
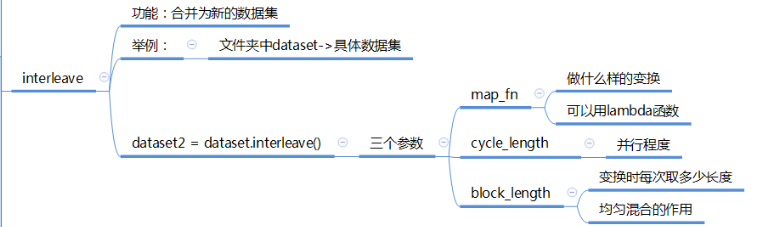
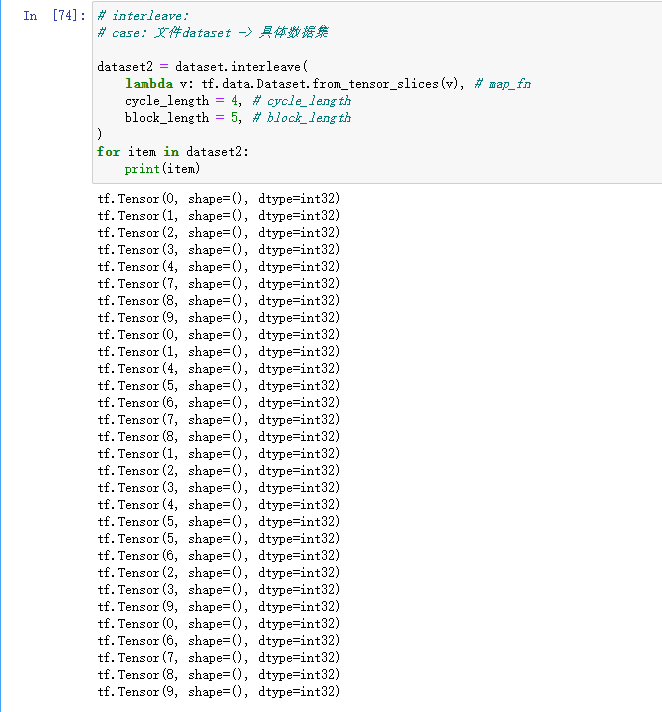
# iterleave:# case: 文件 datset -> 具体数据集dataset2 = dataset.interleave(lambda v : tf.data.Dataset.from_tensor_slices(v), # map_fn 进行何种操作cycle_length = 5, # cycle_length 并行程度block_length = 5, # block_length 均匀混合 长度)for item in dataset2:print(item)
x = np.array([[1, 2], [3, 4], [5, 6]])y = np.array(['cat', 'dog', 'fox'])dataset3 = tf.data.Dataset.from_tensor_slices((x, y))print(dataset3)for item_x, item_y in dataset3:print(item_x.numpy(), item_y.numpy())


dataset4 = tf.data.Dataset.from_tensor_slices({"feature": x,"label": y})for item in dataset4:print(item["feature"].numpy(), item["label"].numpy())

操作CSV文件 还是用加利福尼亚的房价数据

2. 读取数据
from sklearn.datasets import fetch_california_housing# 房价预测housing = fetch_california_housing()
3. 划分样本
# 划分样本from sklearn.model_selection import train_test_splitx_train_all,x_test,y_train_all,y_test = train_test_split(housing.data,housing.target,random_state=7)x_train,x_valid,y_train,y_valid = train_test_split(x_train_all,y_train_all,random_state=11)print(x_train.shape,y_train.shape)print(x_valid.shape,y_valid.shape)print(x_test.shape,y_test.shape)
4. 数据归一化
# 归一化from sklearn.preprocessing import StandardScalerscaler = StandardScaler()x_train_scaled = scaler.fit_transform(x_train)x_valid_scaled = scaler.transform(x_valid)x_test_scaled = scaler.transform(x_test)
5.1 保存文件
output_dir = 'generate_csv'if not os.path.exists(output_dir):os.mkdir(output_dir)def save_to_csv(output_dir,data,name_prefix,header=None,n_parts=10): #name_prefix train valid test区分path_format = os.path.join(output_dir,'{}_{:02d}.csv')filenames = []for file_idx,row_indices in enumerate(np.array_split(np.arange(len(data)),n_parts)):part_csv = path_format.format(name_prefix,file_idx)filenames.append(part_csv)with open(part_csv,'wt',encoding='utf-8') as f:if header is not None:f.write(header + '\n')for row_index in row_indices:f.write(','.join([repr(col) for col in data[row_index]]))f.write('\n')return filenamestrain_data = np.c_[x_train_scaled,y_train] #mergevalid_data = np.c_[x_valid_scaled,y_valid]test_data = np.c_[x_test_scaled,y_test]header_cols = housing.feature_names + ['MiddianHouseValue']header_str = ','.join(header_cols)
5.2 保存文件
train_filenames = save_to_csv(output_dir,train_data,'train',header_str,n_parts=20)valid_filenames = save_to_csv(output_dir,valid_data,'valid',header_str,n_parts=10)test_filenames = save_to_csv(output_dir,test_data,'test',header_str,n_parts=10)
6. 打印文件名
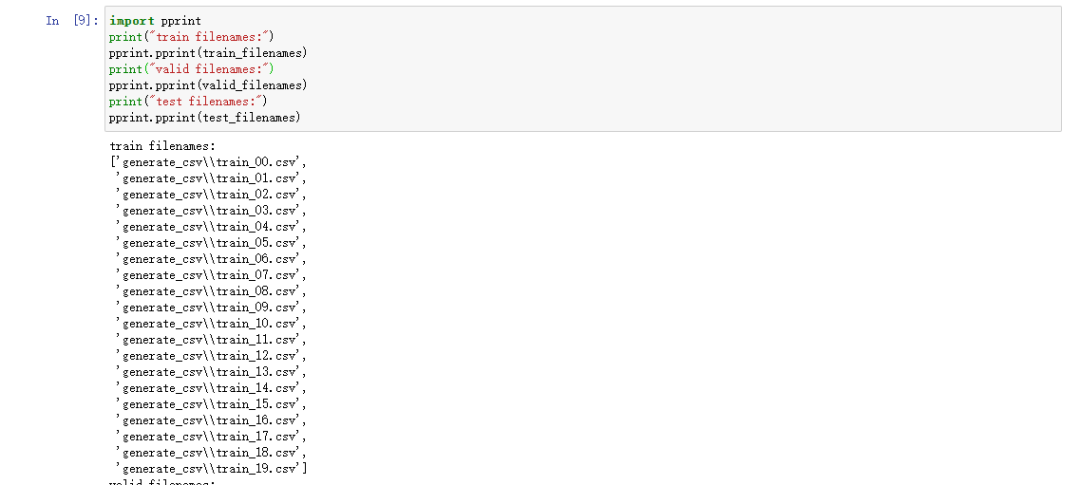
# 读取上面生成的文件# 打印文件名import pprintprint("train filenames: ")pprint.pprint(train_filenames)print("valid filenames: ")pprint.pprint(valid_filenames)print("test filenames: ")pprint.pprint(test_filenames)
7. 读取文件
读取文件
filename -> dataset
read file -> dataset -> datasets -> megre
parse csv
filename_dataset = tf.data.Dataset.list_files(train_filenames)for filename in filename_dataset:print(filename)
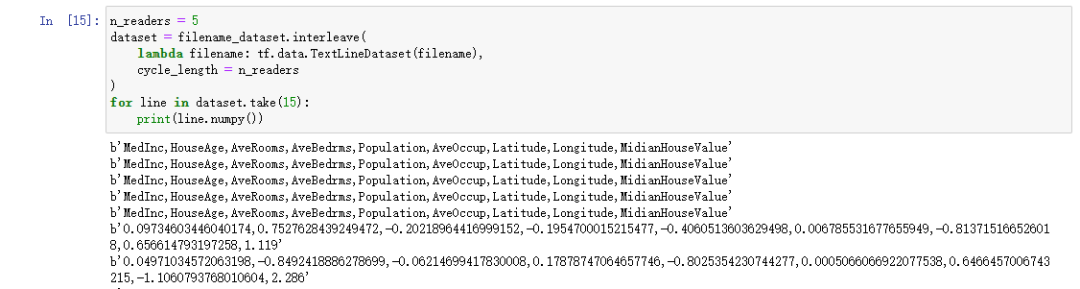
n_readers = 5 # 并行度dataset = filename_dataset.interleave(lambda filename : tf.data.TextLineDataset(filename).skip(1), # skip(1) 省略一行cycle_length = n_readers)for line in dataset.take(15):print(line.numpy(
parse csv 字符串变成tensor
tf.io.decode_csv(str,record_defaults,)
sample_str = '1,2,3,4,5'record_defaults = [tf.constant(0,dtype=tf.int32)] * 5parsed_fields = tf.io.decode_csv(sample_str,record_defaults)print(parsed_fields)
# tf.io.decode_csv(str, record_defaults)sample_str = '1,2,3,4,5'record_defaults = [tf.constant(0, dtype=tf.int32),0,np.nan,"hello",tf.constant([])]parsed_fields = tf.io.decode_csv(sample_str, record_defaults)print(parsed_fields)
8. 解析dataset中的一行
# 解析dataset 中的一行def parse_csv_line(line,n_fields=9):defs = [tf.constant(np.nan)] * n_fieldsparsed_fields = tf.io.decode_csv(line,record_defaults=defs)x = tf.stack(parsed_fields[0:-1])y = tf.stack(parsed_fields[-1:])return x,yparse_csv_line(b'-0.060214068004363165,0.7527628439249472,0.0835940301935345,-0.06250122441959183,-0.03497131082291674,-0.026442380178345683,1.0712234607868782,-1.3707331756959855,1.651',n_fields=9)

9. 整体
整体
filename -> dataset
read file -> dataset -> datasets -> megre
parse csv
# 整体# 1. filename -> dataset# 2. read file -> dataset -> datasets -> megre# 3. parse csvdef csv_reader_dataset(filenames,n_readers=5,batch_size=32,n_parse_threads=5,shuffle_buffer_size=10000):# 1. filename -> datasetdataset = tf.data.Dataset.list_files(filenames)dataset = dataset.repeat() # 重复多少次# 文件名转换成文本内容dataset = dataset.interleave(lambda filename:tf.data.TextLineDataset(filename).skip(1),cycle_length = n_readers)dataset.shuffle(shuffle_buffer_size)# 解析dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads)dataset = dataset.batch(batch_size)return dataset# 测试train_set = csv_reader_dataset(train_filenames,batch_size=3)for x_batch,y_batch in train_set.take(2):print("x:")pprint.pprint(x_batch)print("y:")pprint.pprint(y_batch)
10. 搭建模型
# 搭建模型model = keras.models.Sequential([keras.layers.Dense(30,activation='relu',input_shape=[8]),keras.layers.Dense(1),])# 打印model信息model.summary()# 编译model.compile(loss='mean_squared_error',optimizer="sgd")# 回调函数callbacks = [keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)]
11. 训练
#训练history = model.fit(train_set,validation_data=valid_set,steps_per_epoch=11160 // batch_size,validation_steps = 3870 // batch_size,epochs=100,callbacks=callbacks)
12. 测试集上
model.evaluate(test_set,steps = 5160 // batch_size)
