首先 简单讲一下为什么要用深度网络

我的理解就是 人们通过实验 发现
深层次网络 每层少量权值 的网络模型学习能力 > 浅层 多参数 网络模型的学习能力
浅层网络模型的泛华能力也比较一般
今天我们来实现一个 层次为20层的深度神经网络 。
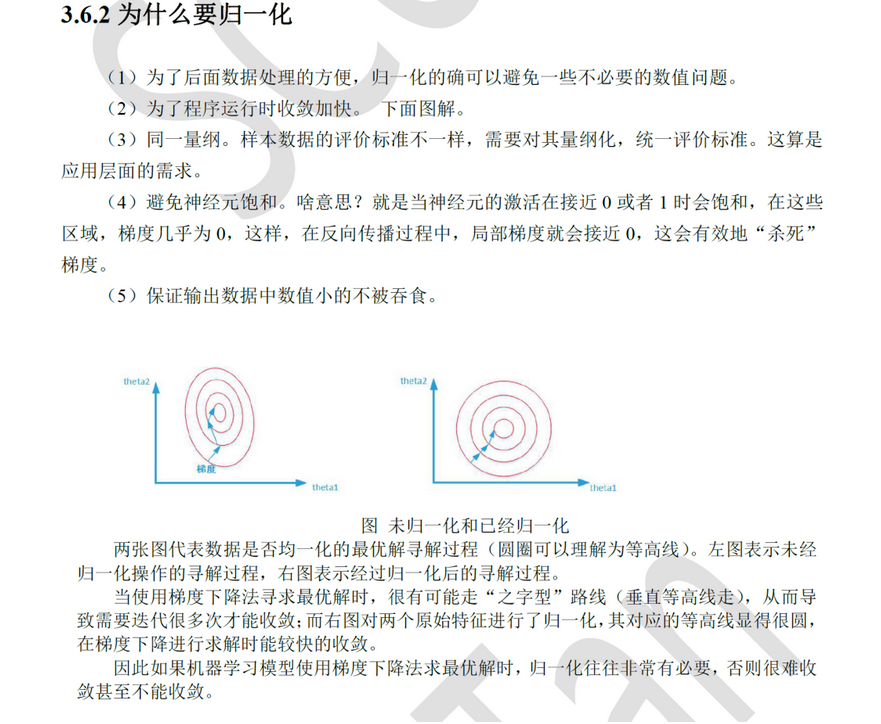
昨天我们学习了为什么要归一化
理论部分 :
归一化的方法有

一般常用的是标准差归一化
今天我们要学习 批归一化
什么是批归一化(Batch Normalization)
(1)以前在神经网络训练中,只是对输入层数据进行归一化处理。
(2)却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。
(3)如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
批归一化的 算法流程


实战 部分
import matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sklearnimport pandas as pdimport osimport sysimport timeimport tensorflow as tffrom tensorflow import kerasprint(tf.__version__)print(sys.version_info)for module in mpl, np, pd, sklearn, tf, keras:print(module.__name__, module.__version__)
fashion_mnist = keras.datasets.fashion_mnist(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()x_valid, x_train = x_train_all[:5000], x_train_all[5000:]y_valid, y_train = y_train_all[:5000], y_train_all[5000:]print(x_valid.shape, y_valid.shape)print(x_train.shape, y_train.shape)print(x_test.shape, y_test.shape)
from sklearn.preprocessing import StandardScaler#预处理归一化 转换为28*28的图像scaler = StandardScaler()# x_train: [None, 28, 28] -> [None, 784]x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
model = keras.models.Sequential()model.add(keras.layers.Flatten(input_shape=[28, 28]))for _ in range(20):model.add(keras.layers.Dense(100, activation="relu"))model.add(keras.layers.BatchNormalization())"""model.add(keras.layers.Dense(100))model.add(keras.layers.BatchNormalization())model.add(keras.layers.Activation('relu'))"""model.add(keras.layers.Dense(10, activation="softmax"))model.compile(loss="sparse_categorical_crossentropy",optimizer = "sgd",metrics = ["accuracy"])
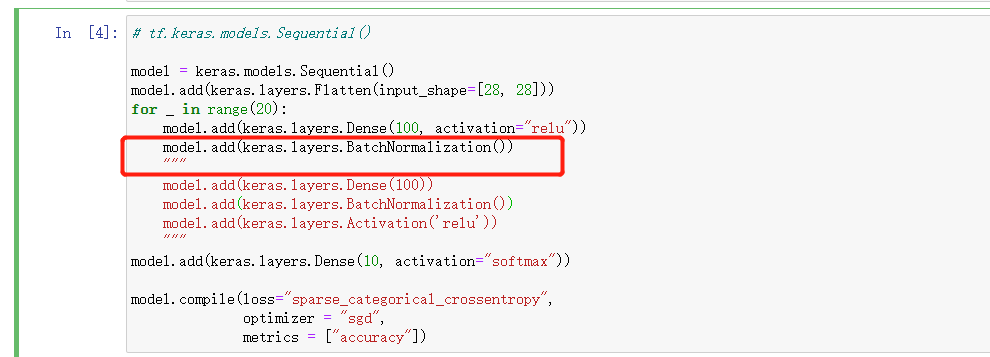
上图中红色框部分为批归一化 代码很简单
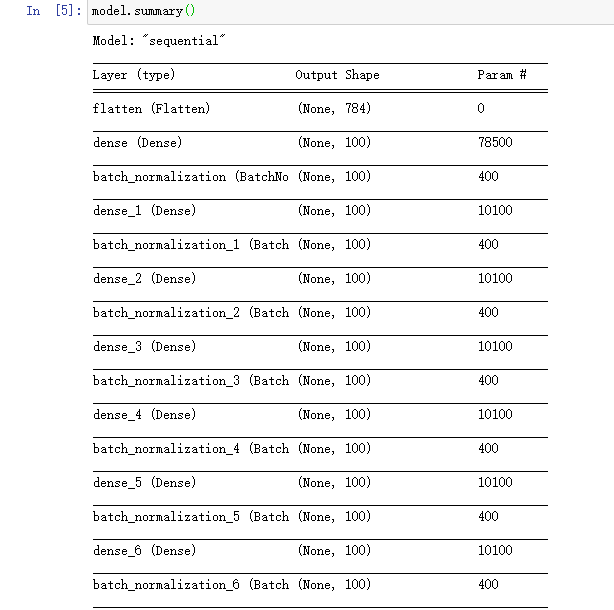
模型结构
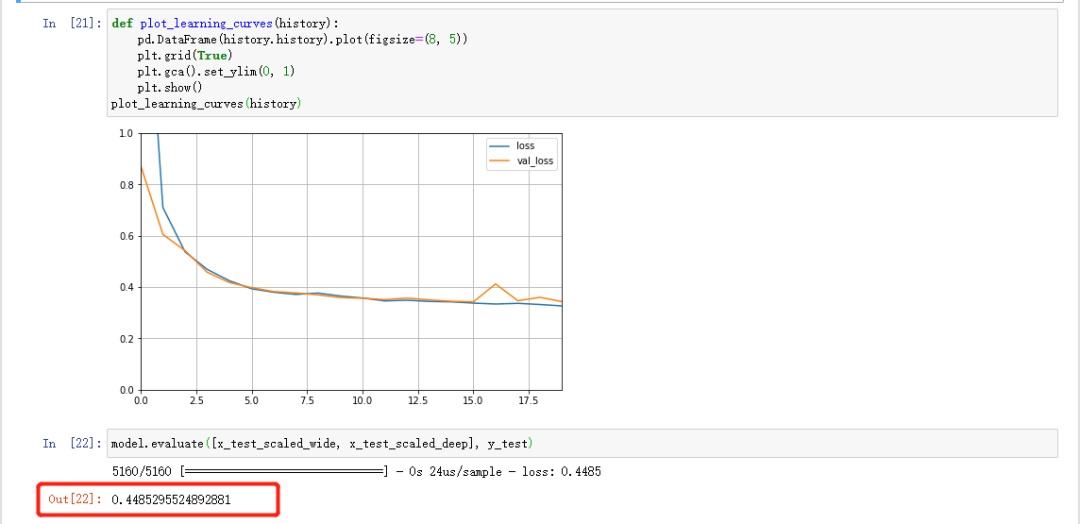
训练 模型# Tensorboard, earlystopping, ModelCheckpointlogdir = os.path.join('dnn-bn-callbacks')if not os.path.exists(logdir):os.mkdir(logdir)output_model_file = os.path.join(logdir,"fashion_mnist_model_dnnbn.h5")callbacks = [keras.callbacks.TensorBoard(logdir),keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),]history = model.fit(x_train_scaled, y_train, epochs=10,validation_data=(x_valid_scaled, y_valid),callbacks = callbacks)
我们可以看一下准确率 轻轻松松85
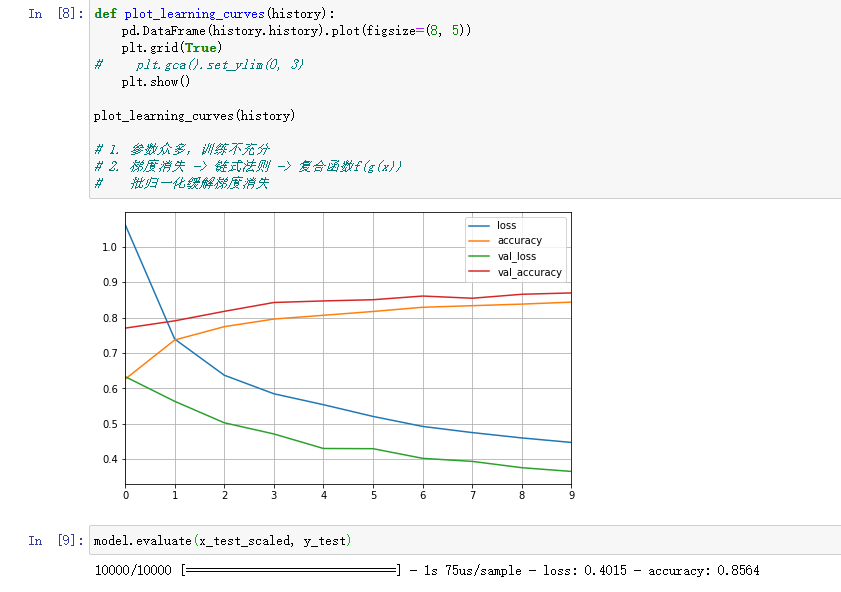
selu 激活函数 = relu + 批归一化
二 什么是dropout
(1)在深层网络中 模型的参数一般都比较多 若样本集过少 很容易出现过拟合
(2)Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
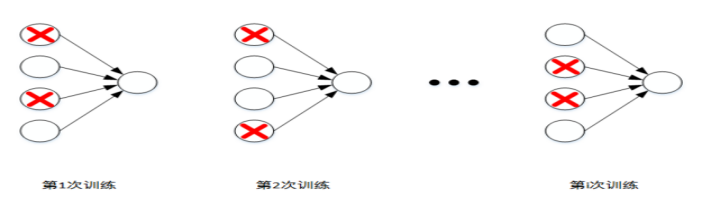
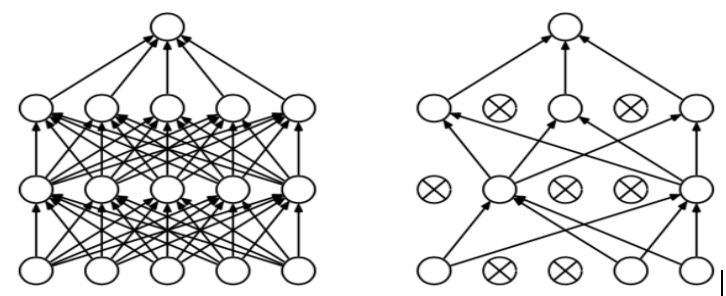
Dropout正则化会遍历神经网络的每一层,并且概率性的设置消除神经网络中的节点,假设每个节点都以0.5设置概率,即每个节点保留和消失的概率都是0.5。每次训练时,每一层都有部分神经元不工作,起到简化复杂网络模型的效果,也许你认为这个方法有点奇怪,但是事实证明他真的有效。能有效的避免过拟合的发生。
dropout不依赖于任何一个特征,因为该单元的输入可能随时被清除,每次丢掉的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性。

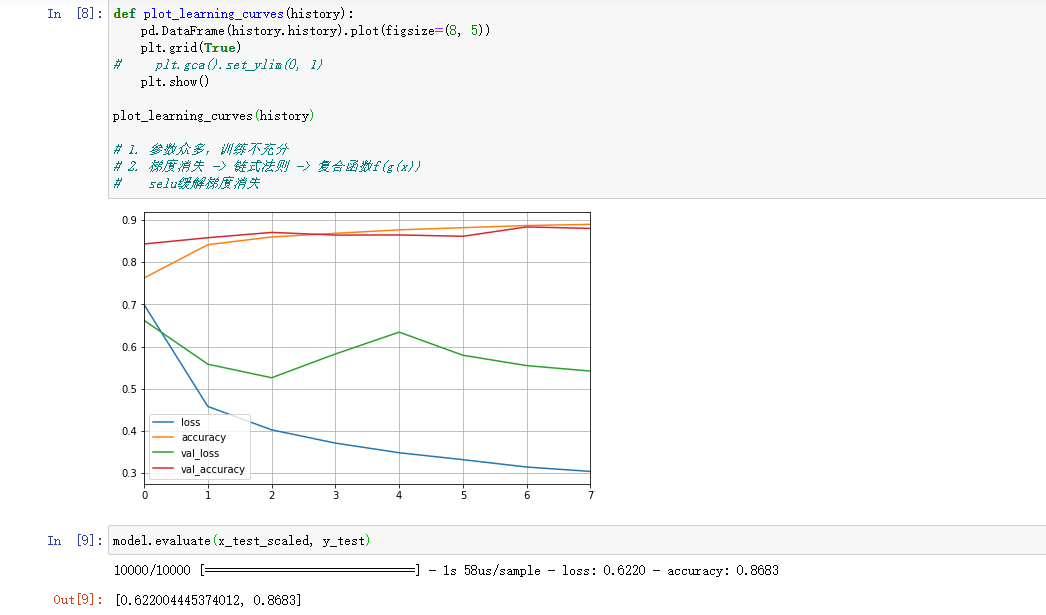
添加了dropout后的准确度提高了百分之1
三 Wide&deep模型





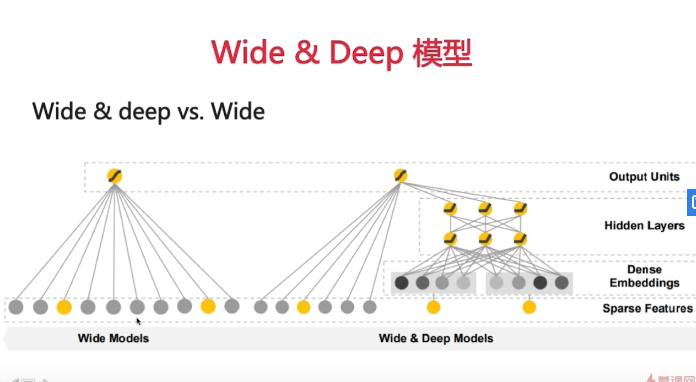


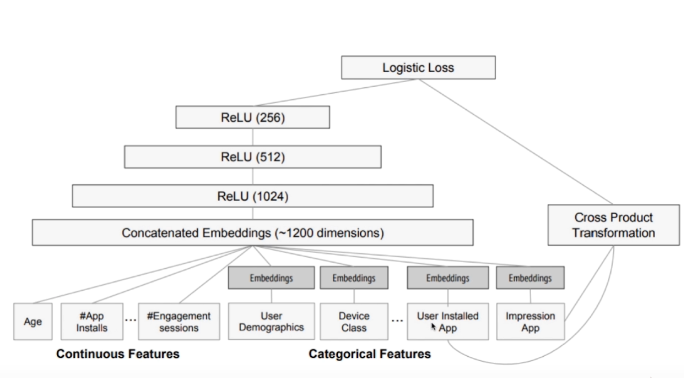
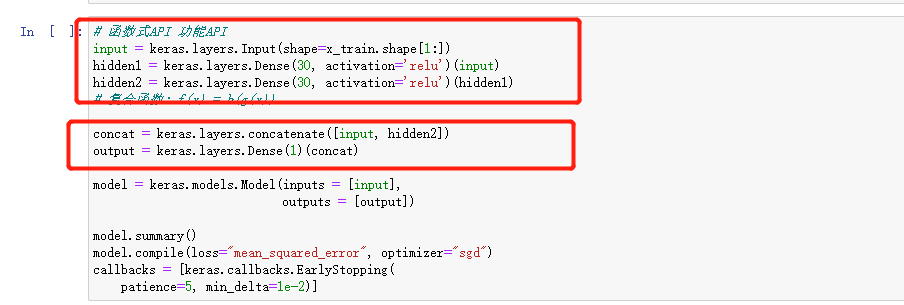

多输入