




上一节简单介绍了机器学习的原理,这次用sklearn包处理一下数据。画图直观的感受一下。
我们想要预测一下 学生的考试通过率。
假设 考试的通过率与两个因素有关 。1:用于学习时间的长短 2:做练习题的多少。
假设学习时长> %80的人 考试通过 label 1
假设做练习题的个数>%80的人 考试通过 label 1
我们设学习时间长短因子为X1 做练习题个数为因子X2
Y = a1*X1 + a2*X2 +a3
a1 a2为未知的权重系数 a3可以理解为正则因子。
Y>0.5 则为考试通过
Y<0.5 考试未通过 label 0
我们先产生数据 我们知道一般数据集分为
训练集(train):学习样本数据集,通过匹配一些参数来建立一个分类器。主要是用来训练模型的。用于模型构建
测试集(Test sets):用于检测模型,数据只在检测时使用,用于评估模型准确率。
该模型未设置验证集
产生数据的代码如下
import numpy as npimport pandas as pddef produce_data(n_points=1000):# 创建储存数据的DataFramedata = pd.DataFrame()# 生成虚拟研究数据np.random.seed(0)# 生成学习特征data['practice'] = np.random.random(n_points)data['time_period'] = np.random.random(n_points)data['error'] = np.random.random(n_points)# 生成类别标签data['label'] = np.round(data['practice']*data['time_period'] + 0.3 + 0.1*data['error'])data['label'][data['practice']>0.8] = 1data['label'][data['time_period']>0.8] = 1return(data)if __name__ == '__main__':data = produce_data()
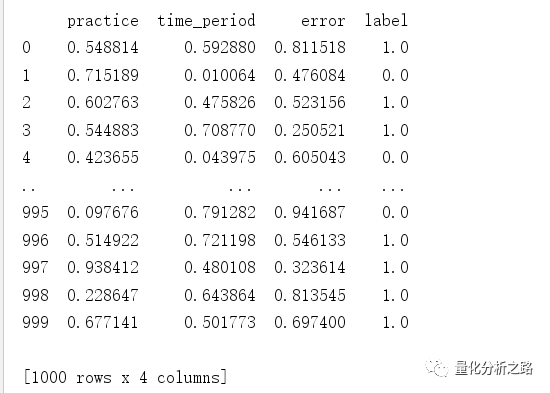
产生1000个随机数据
设置 训练集和测试集的比例为 0.75:0.25
from sklearn.model_selection import train_test_splitfeatures_train,features_test,label_train,label_test =train_test_split(data[['practice','time_period']],data['label'],test_size=0.25 ) #训练集比例
feature_train为训练集数据
feature_test为测试集数据
label_train为训练集标签
label_test为测试集标签
画出该图像在坐标轴上的显示
train_data = features_train.copy() #防止篡改train_data['label'] = label_traintrain_data.head()practice_fail = train_data[train_data['label']==0]['practice']time_preiod_fail = train_data[train_data['label']==0]['time_period']# practice_fail.head()# time_preiod_fail.head()practice_pass = train_data[train_data['label']==1]['practice']time_preiod_pass = train_data[train_data['label']==1]['time_period']plt.figure() #建一个画图窗口plt.xlim(0.0,1.0) #x轴plt.ylim(0.0,1.0)plt.scatter(practice_fail,time_preiod_fail,color = 'b',label = 'fail') #散点图plt.scatter(practice_pass,time_preiod_pass,color = 'r',label = 'pass')plt.xlabel('practice')plt.ylabel('time_period')plt.legend()
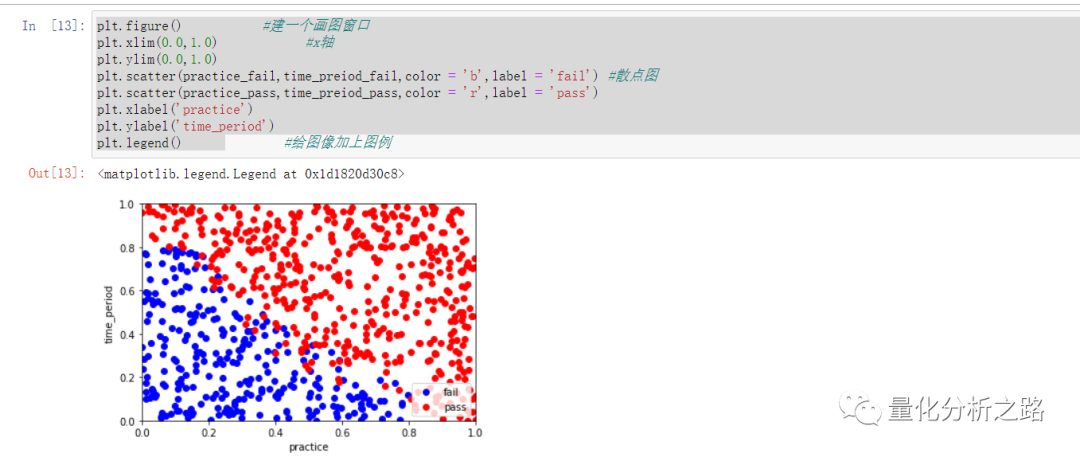
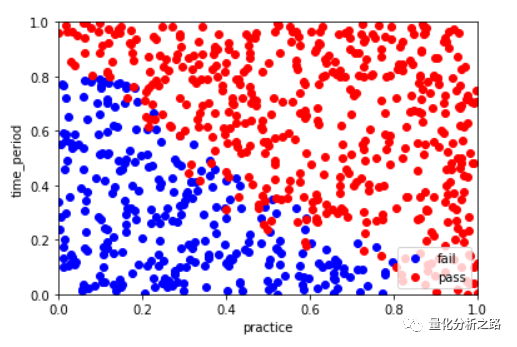
想得到决策边界将通过和未通过的分割开来。
首先用到的就是逻辑回归
其中plot_pic为写好的一个 画图函数
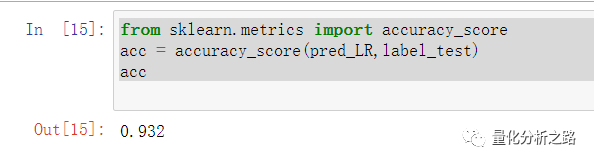
from sklearn.linear_model import LogisticRegressionclf_LR = LogisticRegression() #定义逻辑回归的分类器 初始化模型clf_LR.fit(features_train,label_train) #重点 #用训练集进行训练pred_LR = clf_LR.predict(features_test) # 预测 测试集 返回预测labelplot_pic(clf_LR,features_test,label_test) # clf_LR 训练好模型为参数为传入 画图
###plot_pic函数import numpy as npimport matplotlib.pyplot as pltdef plot_pic(clf, X_test, y_test):x_min = 0.0; x_max = 1.0y_min = 0.0; y_max = 1.0# 画出决策边界,我们为每一个点绘制一个颜色step = .01 # 设置步长xx, yy = np.meshgrid(np.arange(x_min, x_max, step), np.arange(y_min, y_max, step))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])# 绘图Z = Z.reshape(xx.shape)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())plt.pcolormesh(xx, yy, Z, cmap=plt.cm.RdYlBu)data = X_test.copy()data['label'] = y_testpractice_fail = data[data['label']==0]['practice']time_period_fail = data[data['label']==0]['time_period']practice_pass = data[data['label']==1]['practice']time_period_pass = data[data['label']==1]['time_period']plt.scatter(practice_fail, time_period_fail, color = 'b', label='fail')plt.scatter(practice_pass, time_period_pass, color = 'r', label='pass')plt.legend()plt.xlabel('practice')plt.ylabel('time_period')plt.legend(loc='upper right')

查看预测准确率 即预测标签和实际标签的准确率
from sklearn.metrics import accuracy_scoreacc = accuracy_score(pred_LR,label_test)acc
2:决策树算法
from sklearn.tree import DecisionTreeClassifierclf_DT = DecisionTreeClassifier()clf_DT.fit(features_train,label_train)pred_DT = clf_DT.predict(features_test) # 预测 测试集 返回预测labelplot_pic(clf_DT,features_test,label_test) # clf_LR 训练好模型为参数为传入 画图from sklearn.metrics import accuracy_scoreacc = accuracy_score(pred_DT,label_test)acc
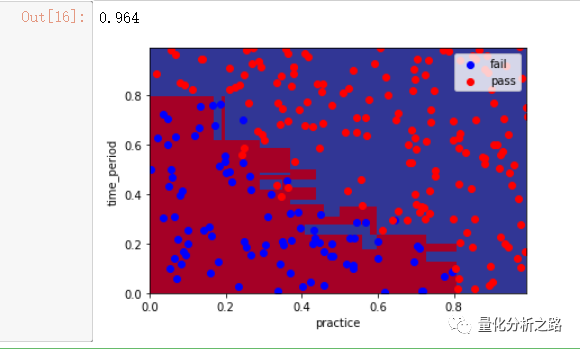
3 随机森林算法
from sklearn.ensemble import RandomForestClassifierclf_RF = RandomForestClassifier()clf_RF.fit(features_train,label_train)pred_RF = clf_RF.predict(features_test) # 预测 测试集 返回预测labelplot_pic(clf_RF,features_test,label_test) # clf_LR 训练好模型为参数为传入 画图from sklearn.metrics import accuracy_scoreacc = accuracy_score(pred_RF,label_test)acc
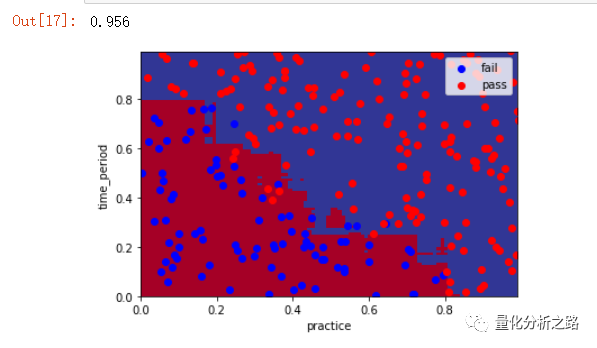
4 KNN算法
#KNN算法原理from sklearn.neighbors import KNeighborsClassifierclf_KNN = KNeighborsClassifier(n_neighbors=7)clf_KNN.fit(features_train,label_train)pred_KNN = clf_KNN.predict(features_test) # 预测 测试集 返回预测labelplot_pic(clf_KNN,features_test,label_test) # clf_LR 训练好模型为参数为传入 画图from sklearn.metrics import accuracy_scoreacc = accuracy_score(pred_KNN,label_test)acc
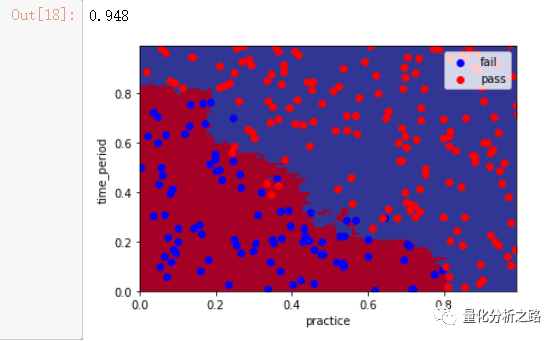
5 SVM算法 不同的kernel
from sklearn.svm import SVCclf_SVC = SVC(kernel='rbf',gamma = 100) #默认kernel = rbf 高斯核 linear 线性核 ploy 多项式核 gamma SVM超参数(根据经验)clf_SVC.fit(features_train,label_train) #gamma 控制SVM中点距离大小的影响程度pred_SVC = clf_SVC.predict(features_test) # 预测 测试集 返回预测labelplot_pic(clf_SVC,features_test,label_test) # 训练好模型为参数为传入 画图from sklearn.metrics import accuracy_scoreacc = accuracy_score(pred_SVC,label_test)acc
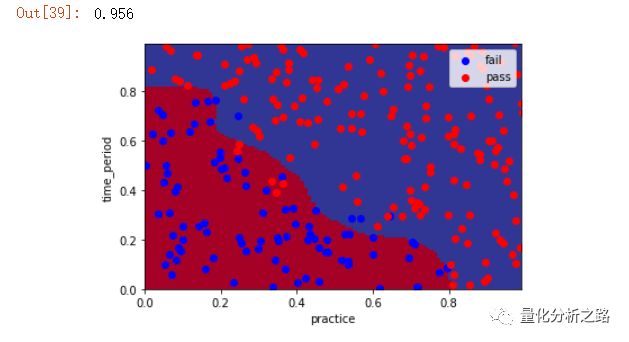

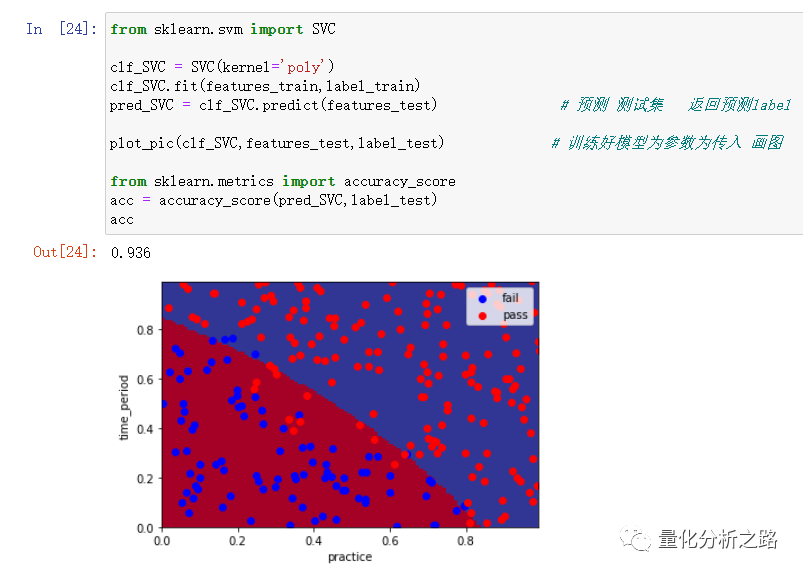
总结一下就是
1:准备好数据
2:导入包 选择模型 初始化
3:将训练数据与训练标签 导入 fit 得到训练后的模型
4:将测试集导入训练后的模型用于预测
5:获得准确率
下一次将学习用简单地机器学习算法 预测股市涨跌
