机器学习分类:
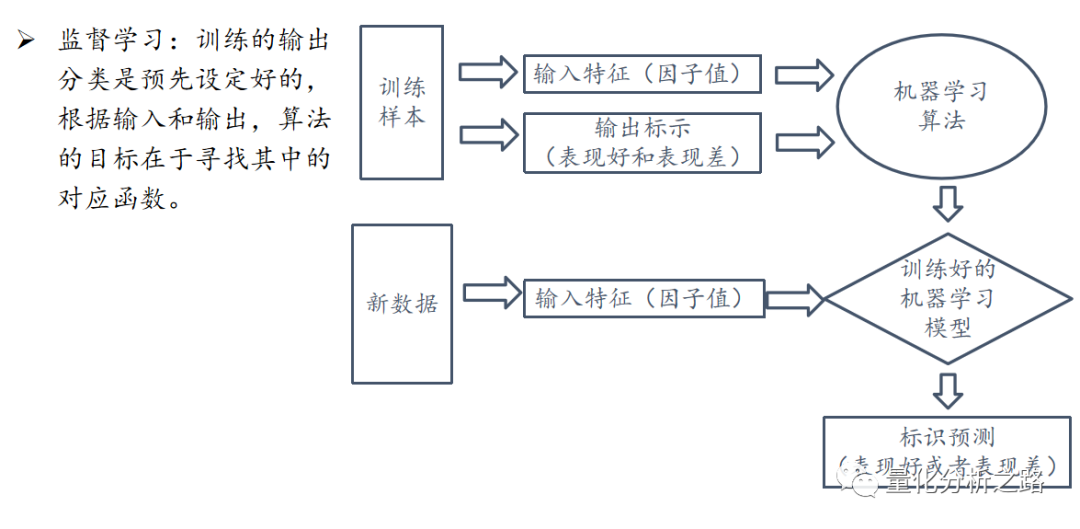
监督学习,训练样本中的“特征”(Features)对应目标的“标签”(Labels),如识别问题:
分类问题,样本标签属于两类或多类(离散)
回归问题,样本标签包括一个或多个连续变量(连续)
无监督学习,训练样本的属性不包含对应的“标签”,如聚类问题;

针对不同的问题,我们需要挑选最合适的机器学习方法。
如果数据中包含特征和标签,希望学习特征和标签之间的对应关系,那么可以采用监督学习的方法;
如果没有标签,希望探索特征自身的规律,那么可以采用非监督学习;
如果学习任务由一系列行动和对应的奖赏组成,那么可以采用强化学习。
如果需要预测的标签是分类变量,比如预测股票上涨还是下跌,那么可以采用分类方法;
如果标签是连续的数值变量,比如预测股票具体涨多少,那么可以采用回归方法;
另外,样本和特征的个数,数据本身的特点,这些都决定了最终选择哪一种机器学习方法。
数据库的建立分为训练集(Training sets);验证集(Development sets);测试集(Test sets)。
训练集(train):学习样本数据集,通过匹配一些参数来建立一个分类器。主要是用来训练模型的。用于模型构建
验证集(开发集dev sets):在学习过程中,调整分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来调整网络结构或者控制模型复杂程度的参数。用于辅助模型构建
测试集(Test sets):用于检测模型,数据只在检测时使用,用于评估模型准确率。
一:支持向量机(SVM)
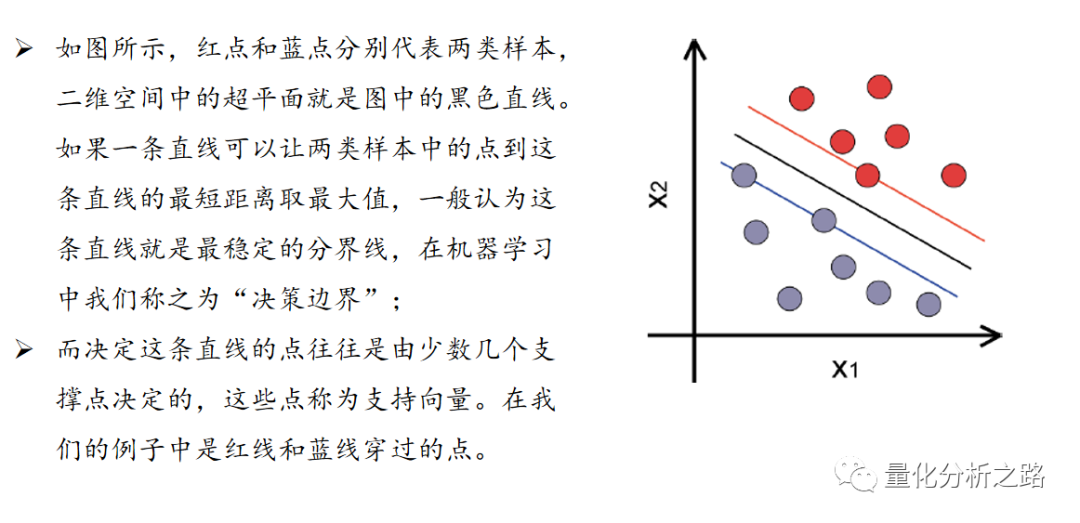
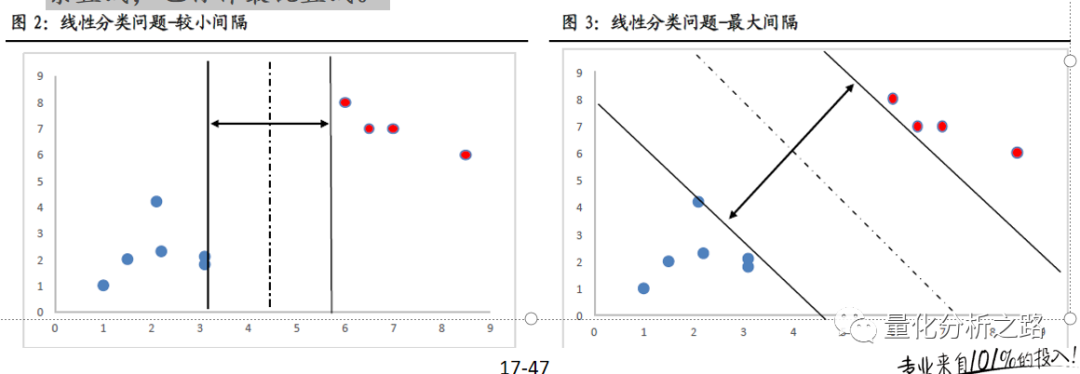
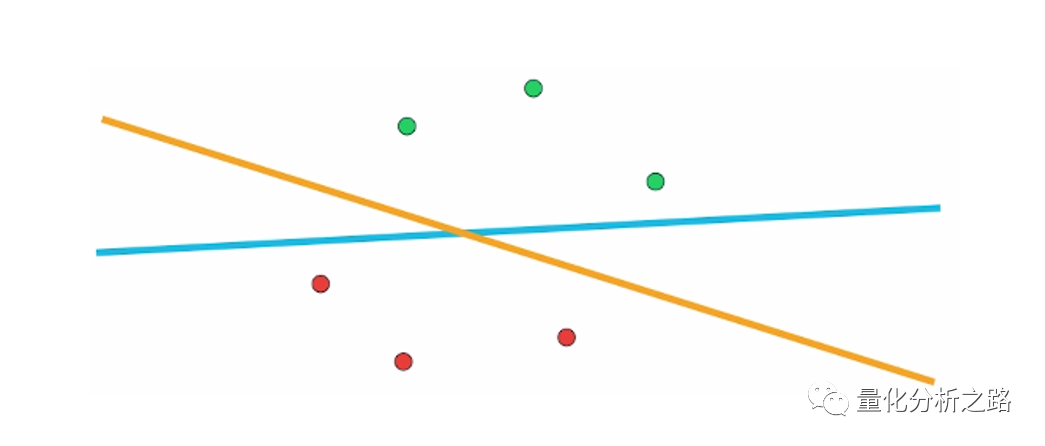
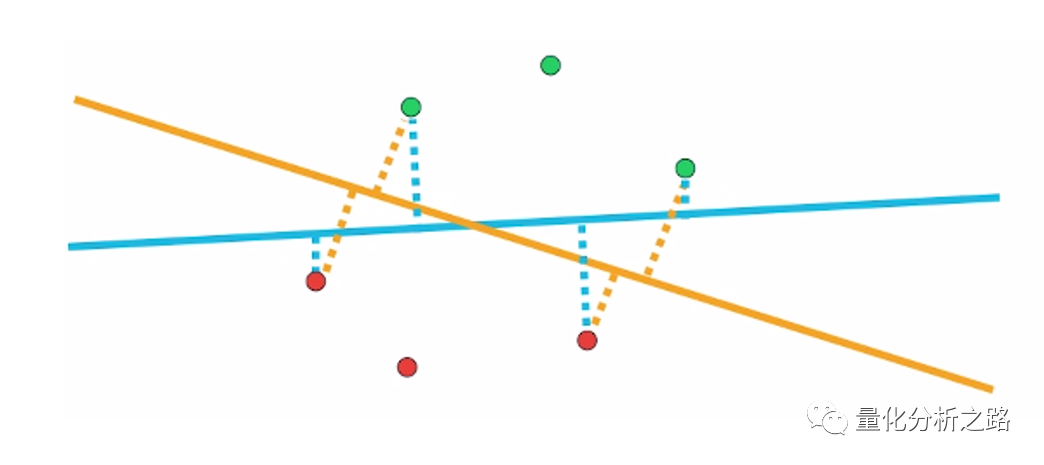
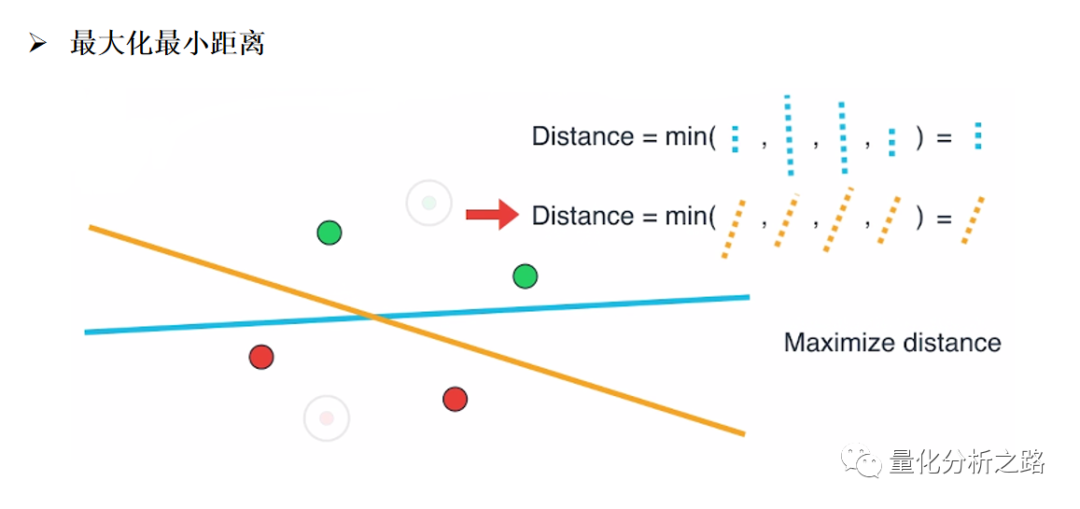
支持向量机算法是根据训练样本,寻找最优超平面的过程。以二维的坐标点为例,支持向量机算法是要找个一条直线将两类坐标点分开。而这种分割的直线是有无数条的,但在这些直线中,如果距离坐标点太近,那么噪声的扰动将对分类结果产生较大的影响,因此我们可以定义,SVM 算法即是找到其中距离训练样本最远的那条直线,也称作最优直线。
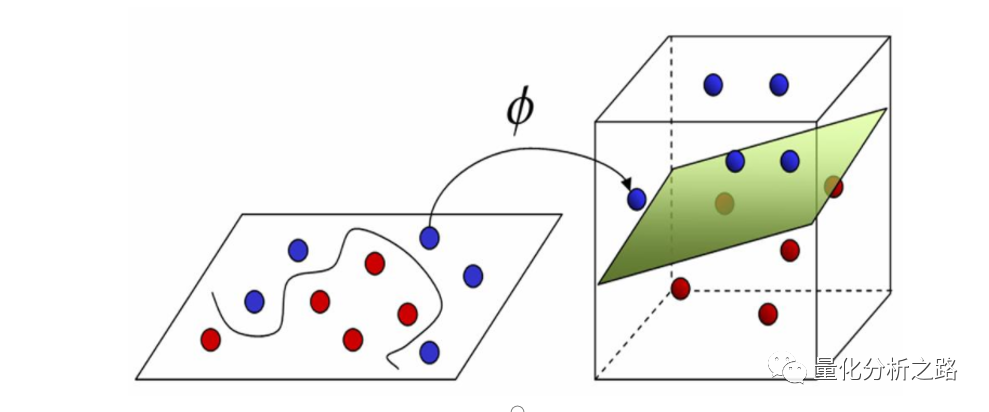
在二维的视角下,我们永远无法用一条线来解决某些问题,如左图所示。但是如果增加一个新的维度𝑥1 ∙ 𝑥2,如右图所示,就可以得到新的数据点分布,从而可以轻松地用一个截面将这两类点分开
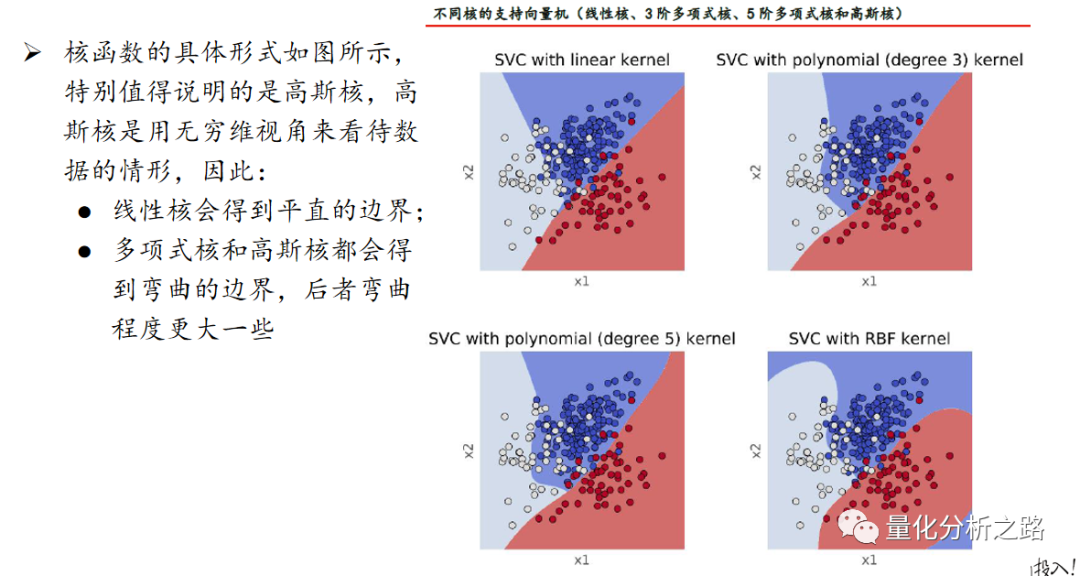
我们上面所介绍的是支持向量分类器,而支持向量机的思路也是刚才介绍的“超平面分类” 以及“引入更多的维度”,所不同的是引入了核(kernel)的方法来计算超平面。
常用的核分为三种,线性核、多项式核以及高斯核。
二: 决策树
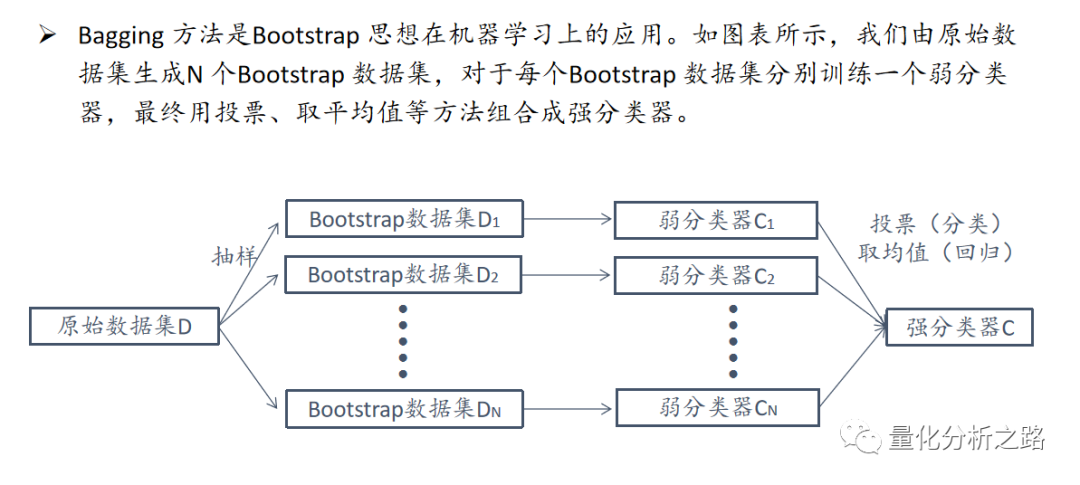
在众多机器学习方法中,决策树(decision tree)是最贴近日常生活的方法之一,我们平时经常用到决策树的朴素思想;
决策树的优势主要包括:
训练速度快;
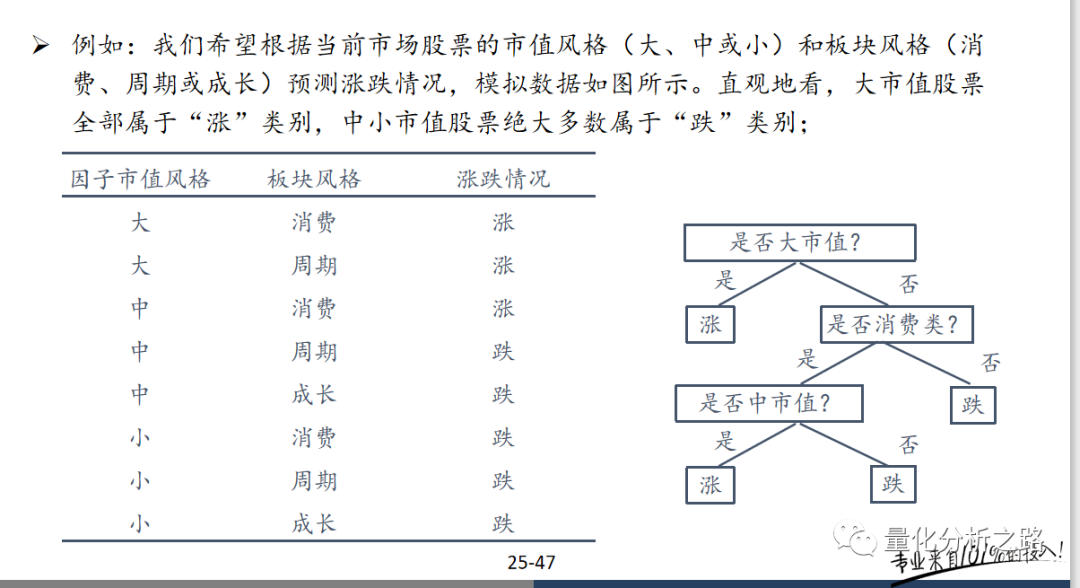
可以处理非数值类的特征,如股市投资中的板块风格(消费、周期和成长);
可以实现非线性分类,有些问题在其他算法下无解,但是使用决策树可以轻松解决;
三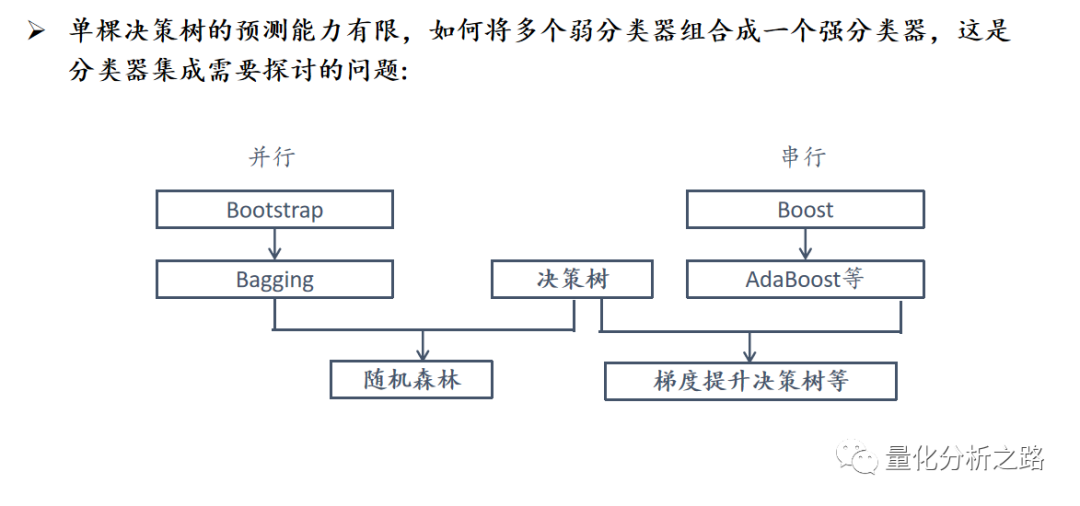
三 : KNN算法
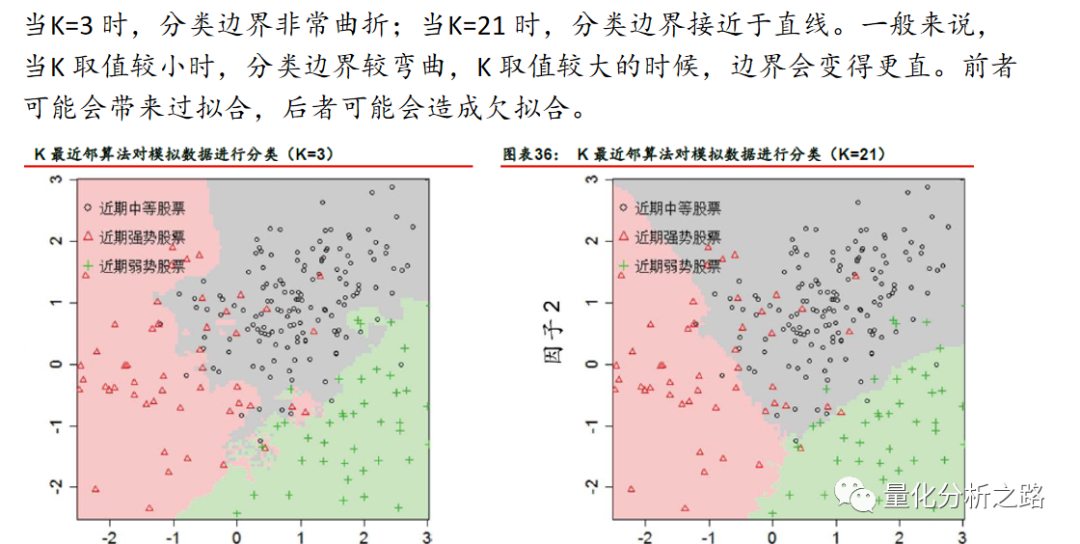
如果两个样本的各个特征都非常接近,那么它们很可能属于同一类别。换句话说,每个样本所属的类别和其“邻居”差不多。我们不妨根据上述思想,制定出一套新的分类规则:每个点对应的类别应当由其周围最近邻的K 个邻居的类别决定——这就是K 近邻(K-nearest neighbor,KNN)算法。
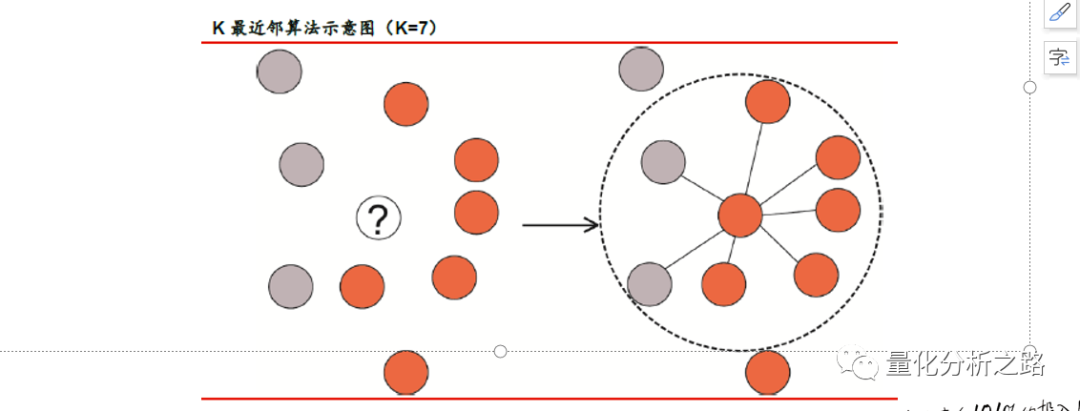
四 : K-means算法
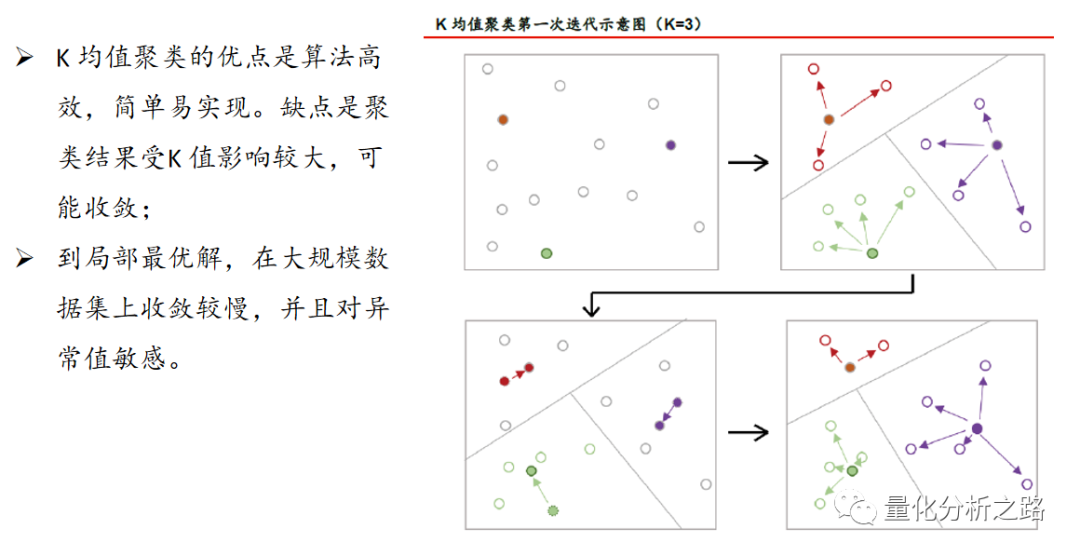
K 均值聚类从全体样本中挖掘出K 个不同的簇,相当于将全体样本分成K 类,每个簇的中心是簇中样本的均值,故称K均值。下图展示了一次K-Means方法的迭代过程:
图中的空心原点是待分类的样本点,我们希望将它们分成3 类,即K=3。首先随机确定3 个点作为质心,如左上图中的红色、绿色和蓝色点。
然后,为每个样本点寻找距离其最近的质心,并将其分配给该质心所对应的簇,如右上图所示。
随后,选取每个簇中所有点的平均值做为该簇新的质心,左下图给出了各簇质心更新的位置移动。
由此得到第一次迭代的分类结果,如右下图所示。重复迭代多次,直到簇不发生变化或达到最大迭代次数为止。