






1. 行列混查的优化器架构
In-Memory Column Index(简称 IMCI)是云原生数据库PolarDB MySQL用于复杂SQL查询加速度的技术,它通过为PolarDB存储引擎增加列格式的索引,再结合并行向量化执行的SQL算子,将实时数据上的复杂分析性能提升1到2个数量级。让客户可以在单一PolarDB上同时运行事务处理和复杂分析负载,简化业务架构并降低使用成本。
IMCI虽然利用了新的索引存储格式和SQL执行引擎算子,却同时保留了100%的MySQL语法兼容,用户无需做任何语法修改即可实现透明复杂查询加速,这是通过PolarDB的SQL解析器和优化器独特架构来实现的:
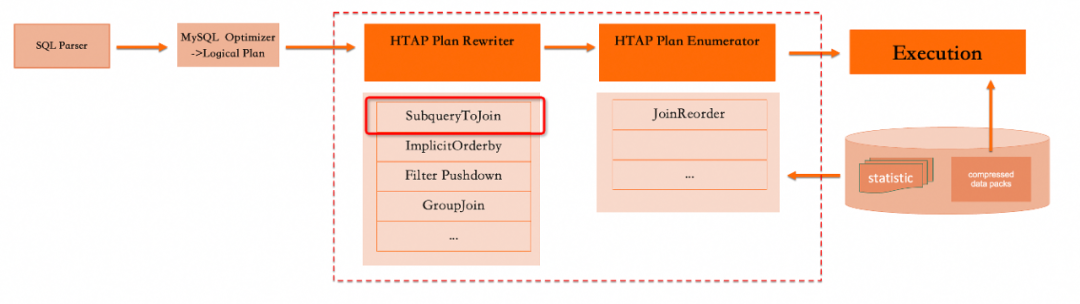
2. 关联子查询的作用
3. 关联子查询的介绍:一个例子
SELECT COUNT(*) FROM t1WHEREt1.c1 > (SELECT MAX(t2.c2)FROM t2WHERE t1.c1 = t2.c1); -- subquery
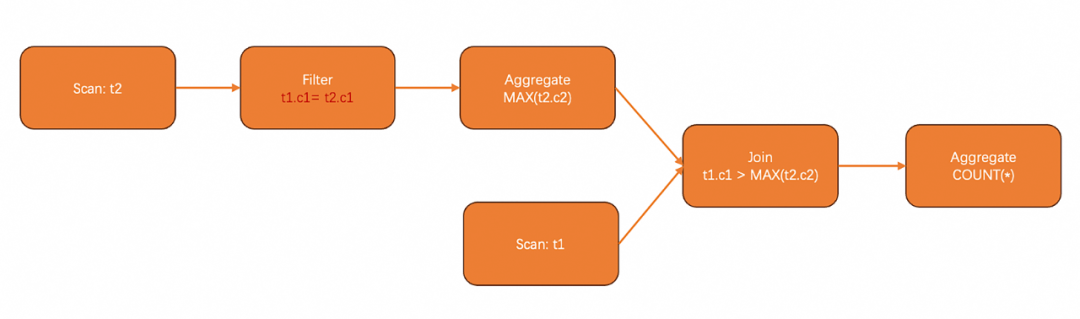
SELECT COUNT(*)FROM t1,(SELECT t2.c1 as c1, MAX(t2.c2) as max_c2FROM t2GROUP BY t2.c1) AS tmpWHEREt1.c1 = tmp.c1 AND t1.c1 > tmp.max_c2;
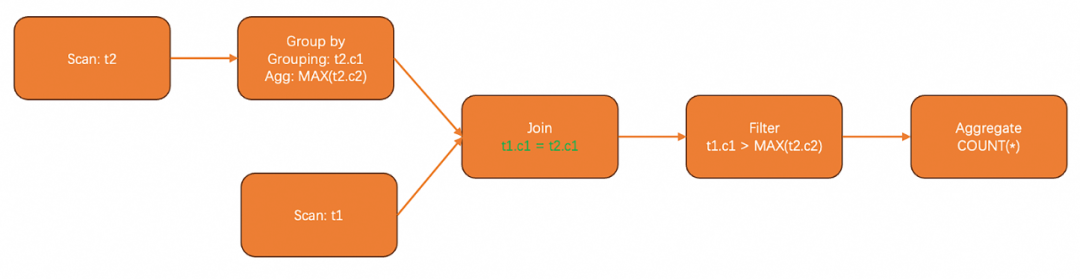
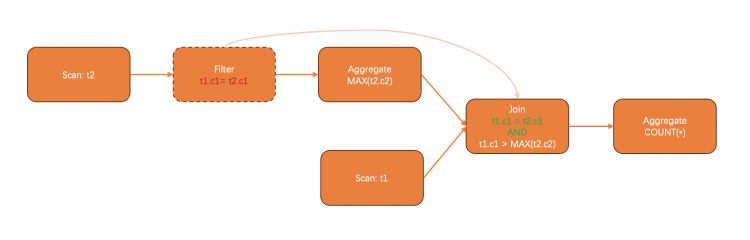
通过对比这个通过SQL改写完成的子查询去关联的查询计划,其实可以发现,这个改写其实只是做了一件简单的事情:把带有关联的filter向上提,直到提到一个能够直接获取关联项的位置,如下图所示。
4. 子查询去关联的算法
在上节一开始的查询计划表示中,我们将其中的nested loop join称之为dependent join(在SQL Server中称之为apply,下文可能会部分使用该术语),其与普通的join的区别在于:
● outer plan引用了inner plan输出的行(例如上文中的t1.c1 = t2.c1)。
上文中提到,我们去关联的基本想法就是把关联项一直向上提,直到关联项越过dependent join,这样就消去了这一个关联项,下文我们将通过多条规则的组合来达成消去任意关联子查询的目标,接下来将以dependent join的outer plan的根节点为标准对规则进行分类,如果我们能够处理任意类型的根节点,那么通过反复应用规则,一定可以将查询的关联项消去。
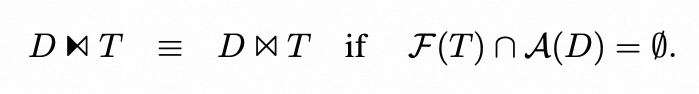
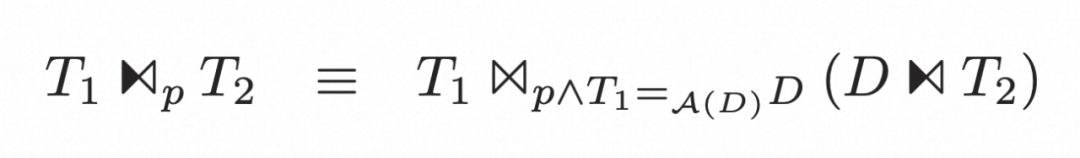
▶︎ Filter和Project
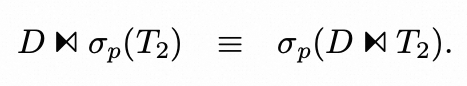
就是普通的谓词下推的逆操作。
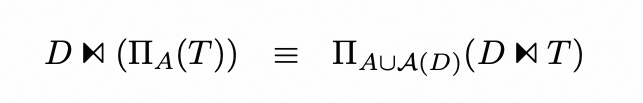
▶︎ Group By
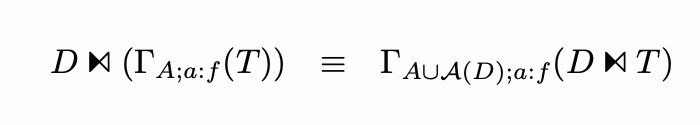
对于 A={∅} 的情况,也就是scalar aggregation,情况有一些不一样:首先,下推后的inner join要改为outer join;其次,部分聚合函数需要做改写,比如这条SQL:
SELECT c_custkey, (SELECT COUNT(*)FROM ORDERSWHERE o_custkey = c_custkey) AS count_ordersFROM CUSTOMER;
SELECT c_custkey, COUNT(*)FROM CUSTOMER LEFT JOIN ORDERS ON o_custkey = c_custkeyGROUP BY c_custkey;
SELECT c_custkey, COUNT(o_orderkey) -- 用orders表的主键(not null)代替FROM CUSTOMER LEFT JOIN ORDERS ON o_custkey = c_custkeyGROUP BY c_custkey;
▶︎ Join
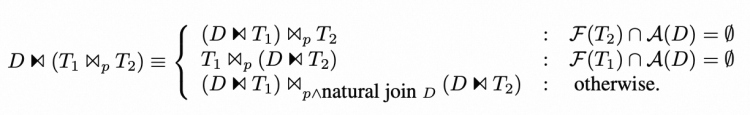
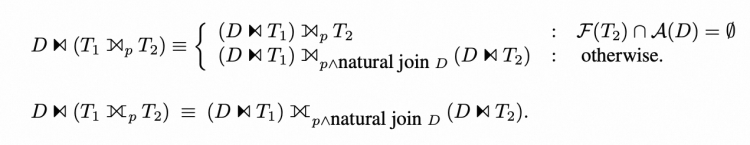
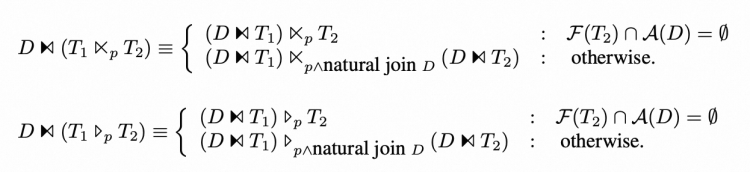
还有一些其他的下推规则,在这里因为篇幅原因不做赘述,感兴趣的话可以参考原论文。[2]
selectCOUNT(*)fromlineitem l1wherel_quantity < (selectavg(l_quantity) as l_avgfromlineitem l2wherel1.l_partkey = l2.l_partkey);
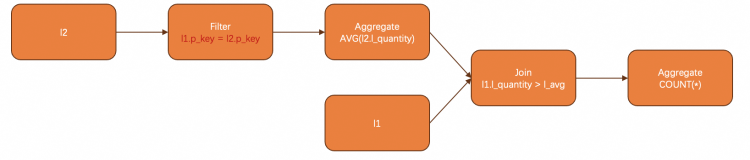
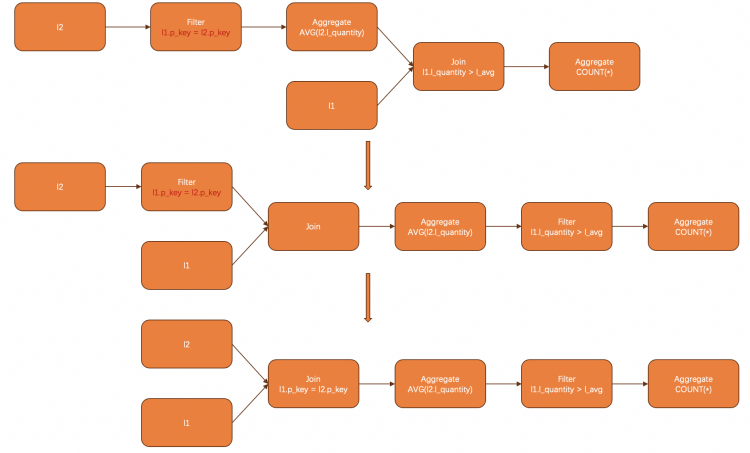
这个例子中,我们通过应用两条规则将groupby和filter拉到join上方之后,关联项被消除,也就完成了子查询的去关联。
SELECTc1,(SELECT t2.c2 FROM t2 LEFT JOIN t3 ON t2.c1 = t3.c1 AND t3.c3 = t1.c3 GROUP BY t2.c2)FROM t1;
根据标量子查询的语义,我们可能会转换出如下形状的执行计划:
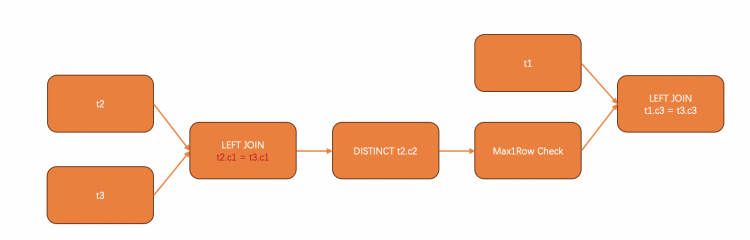
下图展示OuterJoin的情形,semi与anti semi的join的规则与outer join几乎没有区别。
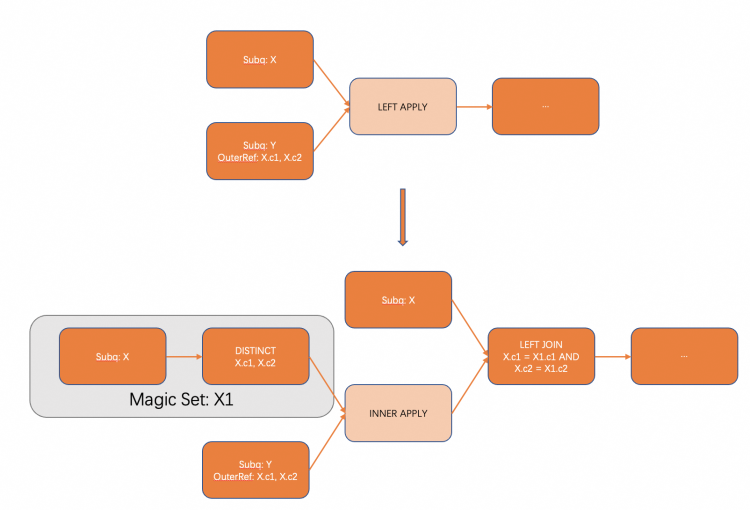
select*fromt1 left join t2 on(t1.a + t2.a =selectafromt3wheret1.a = t3.a and t2.b = t3.b)
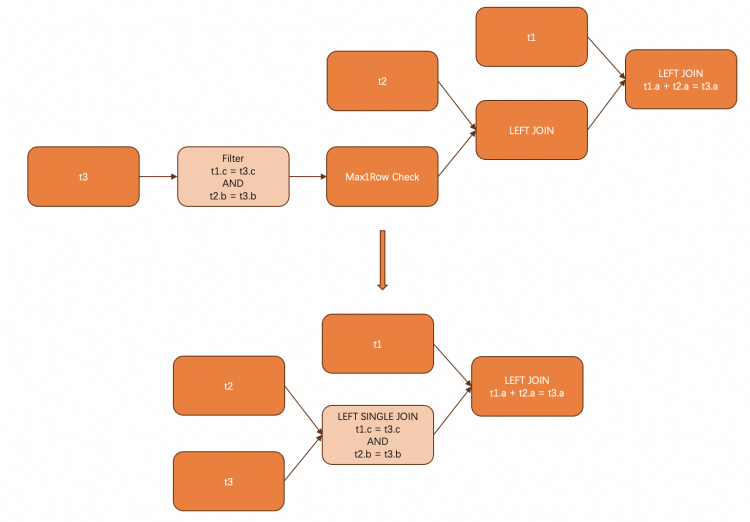
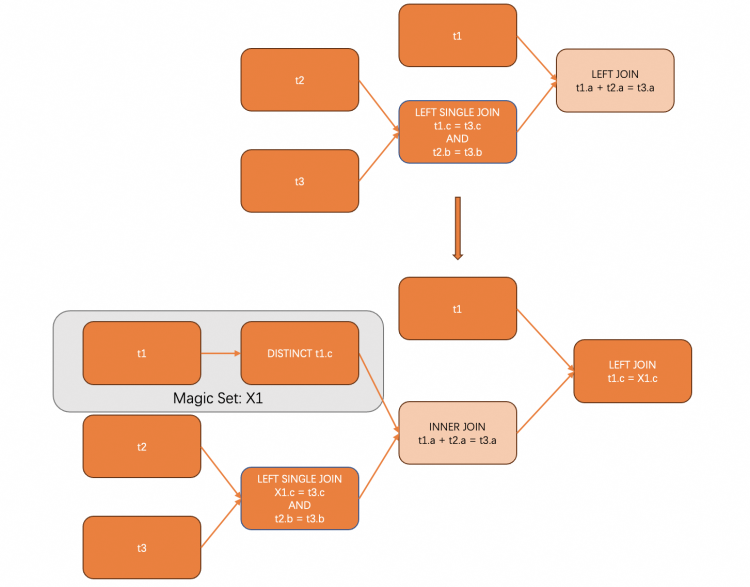
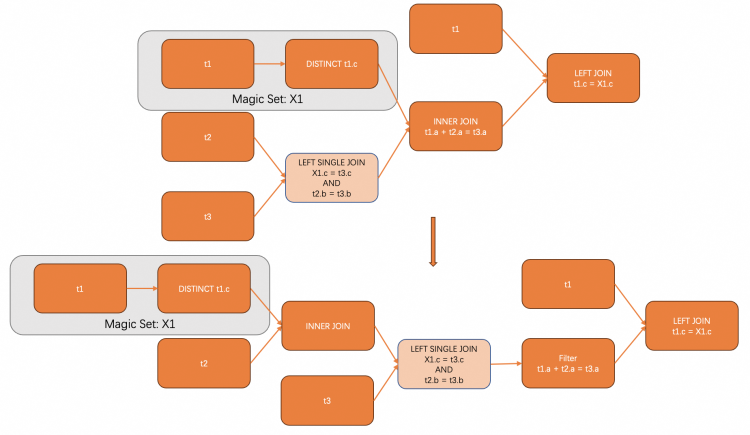
5. 未来工作
SELECT c_custkeyFROM customerWHERE 1000000 <(SELECT SUM(o_totalprice)FROM ordersWHERE o_custkey = c_custkey)
SELECT c_custkeyFROM customer,(SELECT o_custkey, SUM(o_totalprice)FROM ordersGROUP BY o_custkeyHAVING 1000000 < SUM(o_totalprice)) AS agg_resultWHERE c_custkey = agg_result.o_custkey另一种则是先做join,再做group by。
SELECT c_custkeyFROM customer LEFT JOIN orders ON c_custkey = o_custkeyGROUP BY c_custkeyHAVING 1000000 < SUM(o_totalprice);
这两种不同的算法在不同的数据量下性能差异很大,目前IMCI总是选择后者,也就是先join再groupby的方式进行去关联,因为LEFT JOIN可能产生大量数据,因此在部分情况下的效率不够好。后续IMCI会通过将这类优化引入到基于代价的查询优化中,通过查询代价从这两种算法中选择更好的那一种。
在开头我们讲过,IMCI直接引入子查询去关联的动机是:
SELECT *FROM customerWHERE (SELECT COUNT(*) FROM orders WHERE o_custkey = c_custkey) > 1
如果这个子查询能使用o_custkey上建立的二级索引的话,这个nested loop join实际上可以很快完成,我们也就不必历经万难消除它了!实际上,index join正是一种很特殊的关联子查询(子查询的代价很小),后期IMCI能够利用索引加速查询之后,我们可以让部分查询以关联子查询的方式直接执行,甚至可以通过构造关联子查询的方式加快查询的执行效率。
上文提到的所有涉及到的查询,基本都可以用关系代数表达,但是SQL中往往包含一些关系代数无法表达的操作,例如order by, limit等等,后续IMCI将继续拓展子查询去关联的功能,尽量让所有的关联子查询都能高效的在IMCI上执行。
参考文献
[1] Mostafa Elhemali, César A. Galindo-Legaria, Torsten Grabs, and Milind M. Joshi. 2007. Execution strategies for SQL subqueries.
/ END /



 点击 阅读原文 了解 云原生数据库PolarDB
点击 阅读原文 了解 云原生数据库PolarDB