




前言
最近在看 PGConf.EU 相关视频,今天刷到了 Julian Markwort: PostgreSQL Replication: 20 Pitfalls and Solutions (PGConf.EU 2023),十分不错的议题,分享了在流复制和逻辑复制场景下,20 大陷阱与对应的解决方案,收回颇丰,在此也分享给各位读者。
WAL related Pitfalls
WAL Recycle
首先提到的是 WAL Recycle,即 WAL 的回收与复用,默认情况下,主库会在检查点回收"不再需要"的 WAL,但是这个"不再需要"只是主库的想法,假如备库挂了许久,主库便很有可能将备库仍然需要的日志给回收,导致流复制场景下常见的 WAL xxxx has been removed 的报错。
binary replication is just continuous recovery
(continuous) recovery only works if there are no gaps in WAL
if the primary recycles WAL, the replicas can’t use it any more to catch up
解决方案是提前开启归档、调大 wal_keep_size (但是多大够用?) 以及复制槽。

Archiving
归档问题老生常谈了,前阵子才刚写一篇 小心!孤儿归档也可能将数据库整死! ,失败的归档会导致堆积,撑爆磁盘,解决方案是做好监控 (pg_stat_archiver)、 确保 pg_wal 所在盘符足够大亦或是可以快速扩容。

Replication Slots
复制槽也十分熟悉,也会导致类似的磁盘撑爆问题,从 restart_lsn 之后开始保留,解决方案是做好监控 (pg_replication_slots.restart_lsn)、max_slot_wal_keep_size 限制复制槽最大保留数量

Replication of Replication Slots
复制槽老生常谈的毛病——无法复制到备库,所以一旦切换之后,原有的复制槽就丢失了
if your primary breaks and you promote a replica, that new primary doesn’t know anything about the slots on the old primary
解决方案是使用 pg_failover_slots 插件、patroni,另外 17 也即将支持 failover slots

Parameter Dance
其次是相关参数

我在之前也写过类似文章,在备库,以下参数必须比主库大:
max_prepared_transactions max_locks_per_transaction max_wal_senders max_worker_processes max_connections
在 14 以前的版本,如果备库的这些参数比主库小,备库会直接罢工,在 14 的版本之后做了相关优化,当主库上修改了上面五个参数,并且比备库上的值更小时,不会再导致备库宕库了,而是改为暂停恢复 (现象很迷惑),当备库参数修改成大于或等于主库后便会继续自动恢复。
所以解决方案也就明了了,如果要增大,先增大备库的参数。反之亦然,先减小主库的参数。
作者还提到了 wal_level 和 track_commit_timestamp,试了一下果然如此,涨知识了!
postgres=# select pg_xact_commit_timestamp('2144');
ERROR: could not get commit timestamp data
HINT: Make sure the configuration parameter "track_commit_timestamp" is set on the primary server.Switchover related Pitfalls
Split Brain
接下来是 Switchover 相关陷阱,第一个是脑裂——有两个节点同时认为自己是主节点,并且同时承担业务数据,对于脑裂各个 HA 软件都有自己的解决方案,比如 repmgr 的 witness 见证节点以及 location 参数,Patroni 的 watchdog 机制等等,pgpool-ll 也有类似 watchdog 机制。
Supports configuring a Witness server to avoid split brain scenario.
Integration with Linux watchdog for avoiding split-brain syndrome.

Timeline Switches
时间线类似穿越

如果备库 B 的数据落后于 A,此时 A 崩了,并且提升 B 为新主,那么原先的 A 可能无法直接以备库的角色加入,原因不难理解

要想让原主顺利变为备,我们只需要消除差异部分,这正是 pg_rewind 做的事情,消除红色差异部分
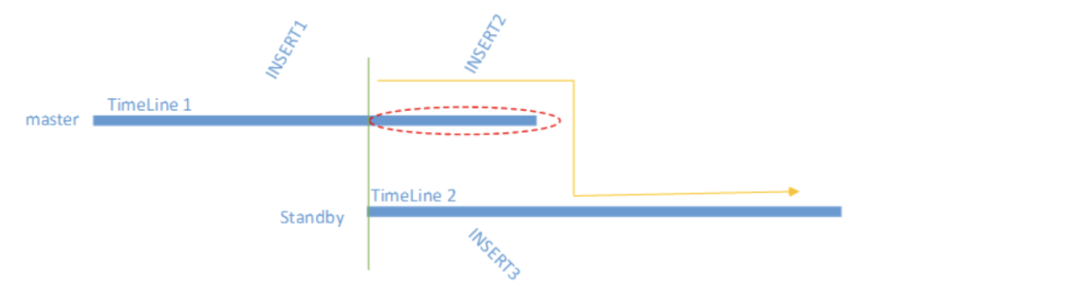
但是使用 pg_rewind 你必须要开启 FPI,并且要确保分叉点之后的 WAL 是连续的,缺一不可,另外,也是最为重要的点,必须要开启 wal_log_hints,但是矛盾的是,你开启了这个参数,又会导致 WAL 写放大,所以你也可以选择另外一个简单粗暴的解决方式——重建,代价就是大库慢得抠脚。
除了 pg_rewind,你还可以借助 pg_waldump,感兴趣的读者可以阅读 Recovering from a Split Brain
pg_waldump … |
grep COMMIT | awk '{ print $8; }' | sed ’s/,//'
> committed_txids.txt

Switchover Implications for Autovacuum
关于这一点我之前文章也有提及,备库和主库的统计信息有很多是不同的

autovacuum launcher 定期读取 stats collector 进程收集的统计信息文件以决定何时触发 autovacuum,而备库是不包含此类统计信息文件的,因此假如有个表在主库上即将达到了触发阈值就快要进行 vacuum/analyze 了,结果这个时候做了一个 switchover 或者 failover,新的主库由于没有统计数据,需要新的活动才可以触发收集,因此这个表就会被"延迟"清理,时间可能就增加了一倍。
作者还特别强调了
the same problem occurs even in standalone databases that do crash recovery
即使在进行崩溃恢复的独立数据库中也会出现同样的问题
所以解决方案就是切换之后,做一个 ANALYZE,以及监控好 autovacuum 以及表膨胀。

Transaction Loss after Failover
关于这个话题,作者花了不少笔墨
by default, PostgreSQL does not wait for replication feedback from replicas
you can accidentially promote replicas that have not received all transactions
默认异步情况下,主库提交不会等待备库的 ACK,因此如果做了 failover,你可能会丢失部分事务,解决方案比如选择 LSN 最大的备库进行 promote,或者使用同步,但是同步提交会增加延迟
如果备库挂了,主库的写入还会阻塞 (目前还不支持类似的最大可用模式,自动降级),可以选择搭建一个 potential 的节点

但是,关于同步提交,作者还提到了另外一个陷阱!
synchronous commit only waits for replicas to confirm COMMIT WAL records
同步提交只等待备库确认 COMMIT,所有其他记录都是异步的,因此仍有可能丢失一些变更,就好像在 COMMIT 之前崩溃的单个实例一样。关于这一点,我下来还需要看下代码,对于这块是如何处理的

Read-Only-Replicas related Pitfalls
Consistency when querying replicas
关于这一点,看作者所写即可,异步模式下,备库可能还看不到主库已经提交的变更,这一点不言而喻,因此有严格读写一致的场景,需要配置为 remote_apply。

同步模式下,你可能在其中一个备库下看到对应的数据,但是主库还在等待其他备库的回应 (Qurom)。解决方案:

Vacuum and Replication Conflicts
这一点是关于流复制冲突的,之前也有很多文章讲解,三板斧:max_standby_streaming_delay、复制槽 + hot_standby_feedback 让主库刀下留人、vacuum_defer_cleanup_age (不推荐,高版本已移除),不过要注意,max_standby_streaming_delay 不等同于查询在被取消前可以运行的最长时间。
Note that max_standby_streaming_delay is not the same as the maximum length of time a query can run before cancellation; rather it is the maximum total time allowed to apply WAL data once it has been received from the primary server. Thus, if one query has resulted in significant delay, subsequent conflicting queries will have much less grace time until the standby server has caught up again.

Prepared Transactions and Recovery
此处作者提到一点,十分重要,笔者之前也不知道,关于两阶段事务的,2PC 会复制到备库,所以即使 switchover 之后,也还在那里。
there was a bug related to recovery in hot_standby with prepared transactions in PG 13 and 14
作者提到的这个 BUG 我搜了一下,https://www.postgresql.org/message-id/743b9b45a2d4013bd90b6a5cba8d6faeb717ee34.camel%40cybertec.at,在 13 和 14 中进行了修复,按照作者的原话
This only occur when you have a prepared statement just in the very last wal segment before your crash happens or you switch over.
Hot Standby doesn’t work
这一点直接看结论吧,简而言之:子事务 + 长事务的组合会导致备库查询雪崩,之前文章也提及过多次。感兴趣的读者可以了解一下 XLOG_RUNNING_XACTS,可以帮我们溯源长事务。

Logical Replication Related Pitfalls
接下来是逻辑复制相关陷阱。
Logical Replication Conflicts
逻辑复制场景下,订阅端是可写的,因此冲突也就在所难免,比如表结构不一致,数据类型不一致等等引发的冲突

解决方案是
ensure nobody writes to your subscriber, e.g. by using different roles with only SELECT privileges
DDL trouble
众所周知,目前逻辑复制还无法对 DDL 进行复制,存量模式可以通过 pg_dump --schema-only 手动复制,增量模式变更需要手动保持同步,当然也可以考虑使用 pg_ddl_deploy 和 pglogical。
long running Transactions and Snapshots
大事务对于逻辑复制的危害众多,此处不再赘述。还有一个点,长事务会阻止逻辑解码,试想一下,假如现在有这样一个操作流:
T1时刻:开启一个长事务,做了相关更改,但不提交
👇
T2时刻:开启逻辑解码
👇
T3时刻:T1事务提交
那么是否可以将 T1 ~ T3 这段时间的操作解析出来?实际上这是个伪命题,会一直阻塞。
the initial table copy worker has to create a snapshot
it needs to wait for all previous transactions to finish.
and it needs to keep track of all transactions created in the meantime
另外在初始拷贝数据期间,原表还可以继续增删改,所以还需要追踪这个期间创建的事务,不难想象,如果存在长事务,快照可能会变得特别大 (xip_list)。
其次搭配 old_snapshot_threshold 的话,你可能会看到一些特别费解的现象。

max_replication_slots and table sync workers
默认情况下,订阅端会同步发布端的表数据,每个表一个 sync worker,每个 sync worker 又会在发布端创建一个复制槽,因此你至少需要 1 + max_sync_workers_per_subscription 个复制槽,同时你还要考虑 max_logical_replication_workers 和 max_worker_processes 全局参数的影响,假如进程槽数量不够,你看到的现象就是卡住了——这一点可以通过观察等待事件。
作者提到了一点
you need as many max_replication_slots on the subscriber as you have tables to sync, if you want to be on the safe side

在某些情况下 (尤其是当存在许多小表时),这个数组并不会被快速清理,为了安全,需要在订阅端上将 max_replication_slots 设置为与需要同步的表一样多的大小。
long running transactions and apply (PG < 14)
众所周知,逻辑复制处理大事务一直比较头疼,不仅会导致性能下降,还会导致延迟。从 13 版本以来,每个大版本在对大事务的处理方面都有显著的提升。但是 13 只是解决了内存使用相关的问题,并没有解决延迟方面的问题,因为所有累积的变更仅在事务提交的时候才一股脑发送给订阅端,在 14 正式引入了"流式"传输,即未提交的事务也会流式传输到订阅端。
具体细节可以参照 逻辑复制大事务处理演进
Conclusion
最后作者还提到了其他几个鲜为人知的问题:
升级之后由于 LSN 和时间线都重新开始了,所以归档目录要切换到一个全新的地方,不然文件可能就会被覆盖,PITR 也同样会有问题。

pg_rewind 不仅确保表数据文件与主库匹配,它还会复制无法通过比对 WAL 重建的配置文件和目录,作者建议将 log 目录单独存放。


小结
收获颇丰!这是笔者见过的干货最多的关于复制专题的分享,希望各位读者也能够细细品味,慢慢消化。
让我们划下重点:
切换之后,记得做个 Analyze 同步提交只等待备库确认 COMMIT,所有其他记录都是异步的,因此仍有可能丢失一些变更,就好像在 COMMIT 之前崩溃的单个实例一样。 在 13 和 14 中,流复制 + 2PC 有 BUG,会导致致命错误 为了安全,需要在订阅端上将 max_replication_slots 设置为与需要同步的表一样多的大小 升级之后归档目录要切换到一个全新的地方 建议将 log 目录单独存放,pg_rewind 可能会覆盖,丢失关键的日志 切换之后,shared_buffers 里面热块和原主库不同,建议使用 pg_prewarm 备库一些参数必须比主库大
参考
Julian Markwort: PostgreSQL Replication: 20 Pitfalls and Solutions (PGConf.EU 2023)
Feel free to contact me
微信公众号:PostgreSQL学徒 Github:https://github.com/xiongcccc 微信:_xiongcc 知乎:xiongcc 墨天轮:https://www.modb.pro/u/39588
