




最近组里在轮流阅读和讲解Python编程规范,大家都觉得提高程序运行性能、节约程序运行时间至关重要。试想一个模型训练如果需要4天,提高一倍性能只需要两天,不仅大幅度缩短项目周期,还能节约不少电费!于是大家买来《Python高性能编程》学习学习。我花了几天时间选重点读了一遍,把重要的知识点做了笔记,记录分享一下。
1
第1章 理解高性能Python
这章实际上是理解计算机底层计算、存储、通信的逻辑,只有理解了这个逻辑,才能从根本上理解程序运行的性能,是哪些因素影响程序运行快慢。
计算机底层组件三部分
计算单元:1.每个周期能进行的操作次数;2.每秒能完成多少个周期
存储单元:1.能存多少数据;2.能以多快的速度进行读写
两者之间的连接:能以多快的速度把数据从一个地方移动到另一个地方
计算
多核CPU并不一定能提升程序运行速度,除非多核能同时进行计算任务。
Python充分利用多核性能的主要障碍在于全局解释器锁GIL:一个Python进程一次只能执行一条指令,无论当前有多少个核心。这意味着在任意时间点只有一个核心在执行Python指令。
我自己的延伸理解:
启动一个Python进程process,如果是计算密集型任务,即使使用多线程thread,由于同一时间只有一个thread能使用当前的CPU进行计算,多线程并不能提高计算速度。但如果是IO密集型任务,线程#1在计算期间线程#2可以处理IO,同理线程#1在处理IO时线程#2可以计算,能提高任务处理速度。
如果启动多个进程,每个进程可以使用不同的CPU核实现并行计算,整个计算速度相应提高。
存储
以下两幅图来自网络,方便了解计算机多级存储的层次结构和读写速度比较
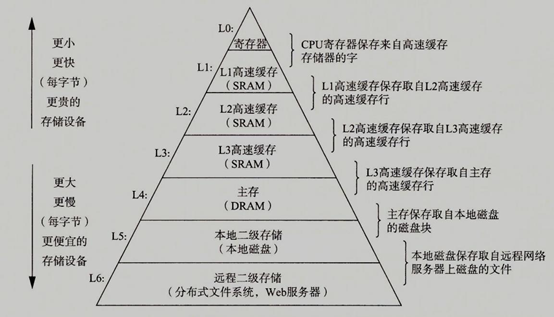

通信
前端总线:RAM和L1/L2缓存之间的连接
外部总线:硬件设备(如硬盘、网卡)通向CPU和系统内部的主干线,比前端总线慢
GPU:由于GPU通常是一个外部设备,通过PCI总线通信,速度远远慢于前端总线
异质架构:一种在前端总线上同时具有CPU和GPU的计算机架构在兴起
2
第2章 通过性能分析找到瓶颈
各种性能分析工具介绍
Unix time命令:记录程序执行耗费的各方面的时间
cProfile模块:一个标准库内建的分析工具,可测量每一个函数运行所花费的时间
line_profiler:分析CPU密集型性能的最强大的工具,可对函数进行逐行分析
memory_profiler:可逐行测量内存使用率
heapy:查看Python堆对象的数量及每个对象的大小
dowser:可在一个web页面展示实时的变量数量实例图
dis:查看CPython虚拟机中运行的字节码,显示代码的跳转点、操作地址、操作名、操作参数
同一段代码在同一个机器温度低的时候可能比温度高的时候运行要快!
3
第3章 列表和数组
列表和元组使用了相同的数据结构,主要区别是:
列表是动态数据,它们可变且可以重设长度(改变内部元素个数)
元组是静态数据,不可变
元组缓存于Python运行时环境,每次使用元组时无须访问内核去分配内存
同一个列表或元组内可以接受混合数据类型,这样会带来一些额外的开销。
高性能编程的一个要点:通用代码会比为某个特定问题设计的代码慢很多。
对次序未知的列表/元组最优查询时间是O(logn),插入时间O(1)。
列表
当一个大小为N的列表第一次需要添加数据时,Python会创建一个新的列表,分配M个空间,M>N,是为了给未来添加预留空间,然后旧列表数据复制到新列表中,旧列表被销毁。当N不断增长到M的时候,会创建一个拥有更多额外空间的新列表。
额外分配的空间一般非常小,但是累加起来就不可忽略。
元组
两个元组合并在一起成一个新元组,复杂度是O(n),但不需要为新生产的元组分配额外的空间。
Python是一门垃圾收集语言,会自动回收不再使用的变量。但对长度1-20的元组,即使不再被使用,其空间也不会立即还给系统,而是待未来使用,减少对操作系统的申请动作。
4
第4章 字典和集合
对字典和集合基于键值查询的时间是O(1),插入时间也是O(1)。
实际速度取决于其使用的散列函数,若散列函数运行慢,对应在字典和集合上的操作也会变慢。
数据插入
使用散列函数将键值转变为一个列表的索引,找到对应要插入的位置。
数据删除
当一个散列值从列表删除,会写一个特殊值表示该位置为空,其后可能有别的值会插入使用,后者在散列表改变大小的时候被删除。
改变大小
字典或集合的默认最小长度是8,即使你保存3个值,Python仍然分配8个元素。每次改变大小,空间增大为原理的4倍,直到50000个元素时,之后每次增加为原来的2倍。
一个实验
import math
def test1(x):
returnmath.sin(x)
from math import sin
def test2(x):
returnsin(x)
def test3(x, sin=math.sin):
returnsin(x)
速度从快到慢依次是test3,test2,test1。
test1为了找sin经历了两次字典查询,一次查math模块,一次在math模块中查找sin函数。
test2 显示导入sin函数,该函数可在全局命名空间中被直接访问,只需要在全局命名空间中查找sin函数。
test3只需要在第一次被定义时查找,之后被作为一个本地变量被保存,无须查找。但是test3不是惯用写法,如果在循环中需要多次调用,可以在循环前用一个本地变量保存对函数的引用,如下:
local_sin = sin
for i in range(n):
result+= local_sin(i)
5
第5章 迭代器和生成器
本章总体就是在说利用迭代器由于不需要把所有数据读入内存,性能好于使用列表。
以下从网络上摘取迭代器和生成器的描述,复习一下:
源自:https://www.runoob.com/python3/python3-iterator-generator.html
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器。
迭代器对象可以使用常规for语句进行遍历,也可以使用 next() 函数。
使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
6
第6章 矩阵和矢量运行
内存碎片问题
原生Python不支持矢量操作,因为:1.Python列表存储的是指向实际数据的指针;2.Python字节码没有针对矢量操作进行优化,for循环无法预测何时使用矢量操作能带来好处。
每次进行矩阵操作时要进行多次查找,比如grid[5][2]要先对列表查找索引5,返回指针指向数据的位置,然后再找索引2,得到实际数据存储的位置。如果数据不是在一个连续的存储块内,就需要花更多的内存传输开销,强制CPU在传输过程中等待。这个就是内存墙问题(内存性能严重限制CPU性能的发挥)。
array
使用array代替列表能减轻这一问题,因为array对象可以在内存中顺序存储数据。但使用array类型创建数据列表比list要慢,因为array对象存储的数据是一个非常底层的抽象,使用时需要转换为Python兼容的版本,需要额外的开销。
numpy
正确的解决方法就是使用numpy—它能将数据连续存储在内存并支持数据的矢量操作。
numexpr
numpy对矢量操作的一个缺陷是一次只能做一个操作,比如A*B+C,先算A*B,得到结果存在一个临时矢量中,然后计算+C。numexpr则将整个表达式编译为非常高效的代码并运行。
7
第7章 编译成C
把程序编译为C语言运行,提高性能。由于我暂时没有这项需求,未阅读本章。
8
第8章 并发
并发很多时候和I/O操作相关,并发允许我们在等待一个I/O操作完成的时候执行其他操作,帮助我们把这段浪费的时间利用起来。即使是在单CPU单线程程序上!
使用并发,典型情况下用“事件循环”来管理程序中什么时候该运行什么东西,通常有两种方式:回调和future。
实现异步的Python库
gevent:Python 2.7
tornado:Facebook为HTTP服务器端和客户端开发的库
asyncio:Python3支持,定义了协程,可以理解为比线程thread更小的单位
9
第9章 multiprocessing模块
CPython默认没使用多CPU,一部分原因是Python被设计用于单核领域,另一部分原因是实际上有效的并行化是相当困难的,并行编程常常被认为是一种艺术!
multiprocessing模块让你使用基于进程和线程的并行处理,在队列上共享任务,以及在进程间共享数据。
主要集中于单机多核的并行(对多机并行来说,有更好的选择),对于CPU密集型问题,在多进程上进行并行。
对于I/O密集型问题,使用上一章讲的gevent\tornado\asyncio更恰当。
multiprocessing主要组件
进程:当前进程的派生(forked)拷贝
池:包装了进程和线程
队列:一个先进先出的队列允许多个生成者和消费者
管理者:一个单向或者双向的在两个进程间的通信渠道
ctypes:允许在进程派生(forked)后,在父子进程间共享原生数据类型
同步原语:锁和信号量在进程间同步控制流
注意:multiprocessing中做随机数生成时,如果使用的Python原生random,在派生拷贝(fork)时,它会在每一个新进程中强制调用random来为随机数生成器做种子。如果使用的是numpy的random,必须显示地调用,否则每一个进程中会生成一样的随机数序列。
进程间通信的方法
串行的解决方案作为基线
使用multiprocessing.Pool
使用multiprocessing.Value作为标记
使用外部的键值对存储引擎Redis作为标记
使用multiprocessing.RawValue作为标记
使用mmap模块作为标记
同步文件:使用lockfile
lock = lockfile.FileLock(filename)
lock.acquire()
… do something for the file
Lock.release()
同步变量
multiprocessing.Value在进程间共享一个整数,尽管Value有锁,自身防止了同时读和写,但没有提供一个原子的递增操作,可以使用multiprocessing.Lock,和lockfile.FileLock用法类似。
10
第10章 集群和工作队列
集群的好处
扩展计算需求,动态扩容和减容
提高可靠性,一组服务器失效另一组可以马上顶上
缺陷
复杂、难以管理和维护
数据同步和延迟
集群化解决方案
Parallel Python
IPython的ipcluster
使用GO编写的高性能分布式消息平台NSQ
其他工具
11
使用更少的RAM
array
要在array上做计算,不会发生整体上的节省,如果你想要把数组传递给一个外部进程或者只使用一些数据,比使用list会大大节约RAM
getsizeof()
大部分(并不是全部)Python对象可以使用sys.getsizeof(obj) 获取对象使用的内存情况,得到的值只报告了一部分开销,常常只是其父对象的开销。
asizeof()
asizeof() 会遍历容器的层级结构并对它发现的每个对象做出最好的猜测,但它的速度相当慢,并且不能计算幕后的内存分配。
Python3对Unicode对象的存储明显比Python2少。Python2中对每一个Unicode字符使用相同数量的字节数,Python3使用更少的字节数来表示更低阶的字符,即更常见的字用更少的字节数。
对文本的存储和查询
set比list使用更多的RAM,但是查询更快,更有效的是用树结构,实验中从消耗1.1GB下降到254MB。
12
现场教训
本章是几个公司的负责人关于系统性能特别是Python性能的经验教训分享,请自行阅读。
以上就是我认为的全书重点,如果你对某一部分感兴趣,可以再仔细阅读、理解。
