




语音识别系列前三篇分别介绍了基本原理、混合模型、端到端模型中的CTC模型和Transducer模型。此篇是系列最后一篇,讲讲基于Attention机制(注意力机制)的端到端模型。
复习Attention
Attention机制毫不夸张地说是近几年机器学习中的大热门,热门的原因确实是因为它在各种场景中能提高模型的准确率。Attention本身的机制和结构不是本篇文章的重点,网上介绍的文章很多,我公众号之前也专门写了一篇文章介绍 ELMo、Attention、Transformer究竟在讲什么?
为方便理解本篇介绍的各种基于Attention的语音识别模型,对需要复习Attention的读者,我在此再系统列举一下当初提出Attention的基本论文和网上解释得最直观和系统的文章链接。最典型的Attention有两大类,一是Bahdanau等提出的用于机器翻译的Bahdanau Attention,二是Transformer模型中的Self-Attention。
Bahdanau Attention:
原始论文:https://arxiv.org/pdf/1409.0473.pdf
可视化解释:https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
Transformer:
原始论文:Attention Is All You Need:https://arxiv.org/abs/1706.03762
可视化解释:http://jalammar.github.io/illustrated-transformer/
回到主题,近5年基于Attention的语音识别模型相关论文众多,本篇主要列举有代表性的模型结构。很多模型只是在基本结构上做修改,或者训练时使用一些特定的技巧,不一一列举。为方便分类,把基于Bahdanau Attention的记为Attention#1,基于Transformer Self-Attention的记为Attention#2。
Attention#1:LAS
全称:Listen, Attend and Spell
论文:https://arxiv.org/pdf/1508.01211.pdf (2015年)
作者机构:Carnegie Mellon University, Google Brain
一句话总结模型结构:和Bahdanau Attention的seq-to-seq翻译模型结构一致
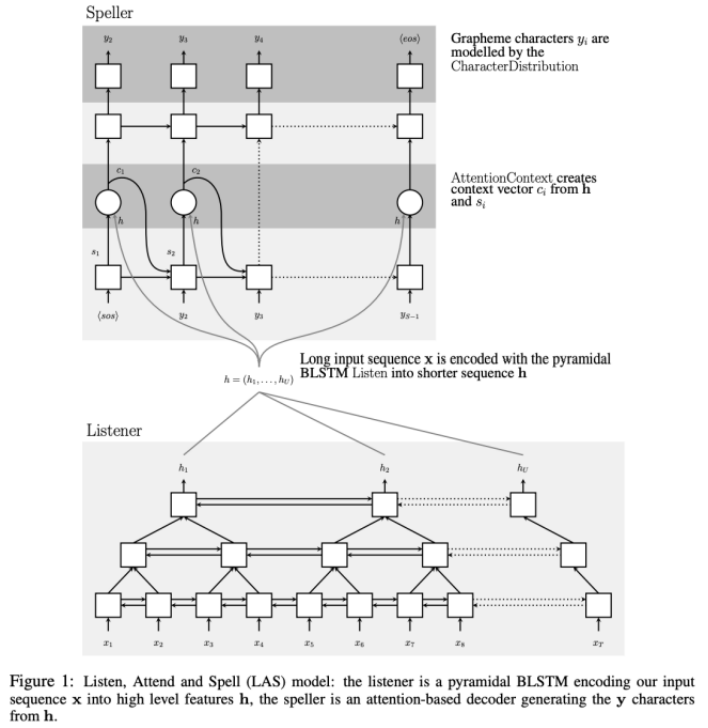
Listener:也就是encoder,接受语音数据,在传统seq-to-seq翻译模型上作修改,使用金字塔形的双向LSTM,可减少计算复杂度,加快训练收敛速度。
Attend and Spell: 也就是decoder,使用基于Attention的LSTM,把从encoder得到的信息解码为文本。
实验结果:
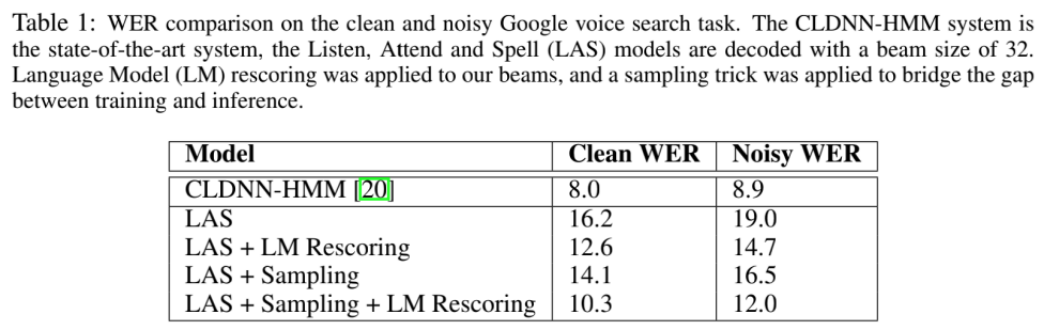
其中,CLDNN-HMM是DNN/HMM混合模型,LM Rescoring是加上语言模型,Sampling是训练中以一定概率从前面预测结果采样作为后续预测输入。从中可以看出,各种情况下性能都差于混合模型。
Attention#1:对LAS的改进
论文:https://arxiv.org/abs/1609.06773 (2017年)
作者机构:Carnegie Mellon University等
一句话总结模型结构:联合使用CTC和Attention
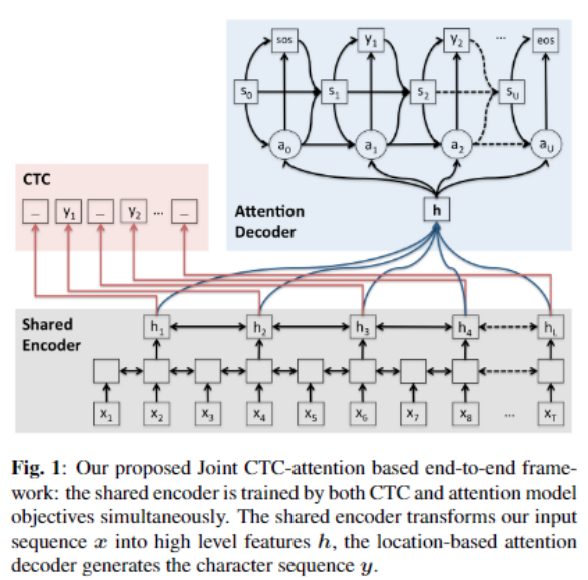
模型利用CTC和attention的优点,在encoder输出上加入CTC。损失函数是CTC和attention损失函数的加权和:
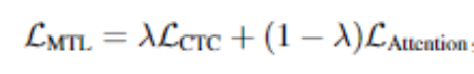
实验结果:
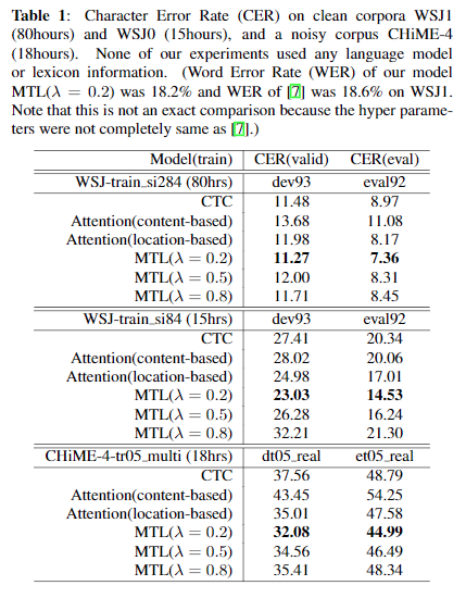
优于单独的CTC或者Attention。
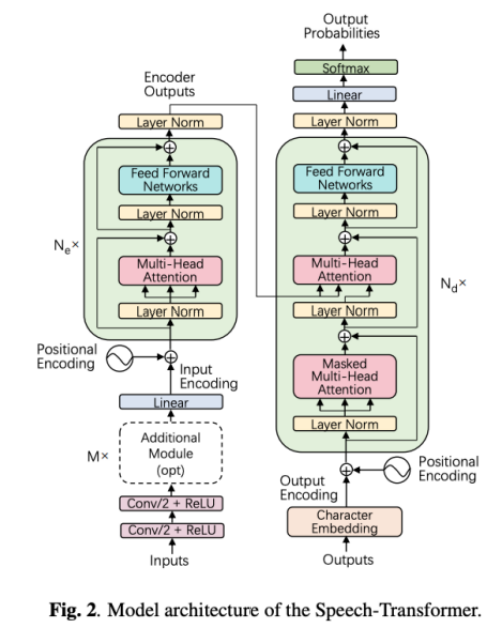
Attention#2:标准Transformer
论文:http://150.162.46.34:8080/icassp2018/ICASSP18_USB/pdfs/0005884.pdf (2018年)
全称:Speech Transformer
作者机构:中科院自动化所,中科院大学
一句话总结模型结构:标准Transformer + 输入使用卷积网络(CNN)
实验结果:
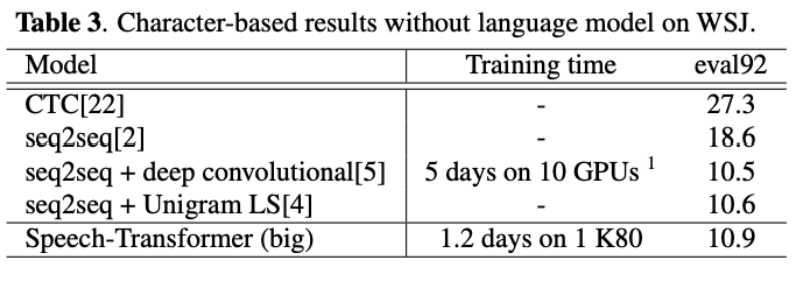
和其他两个seq-to-seq性能相当,但没有和混合模型以及LAS模型比较。
Attention#2:对Transformer的改进
论文:https://arxiv.org/abs/1904.13377 (2019年)
作者机构:Carnegie Mellon University等
一句话总结模型结构:对Transformer结构做局部改进,另加一些技巧
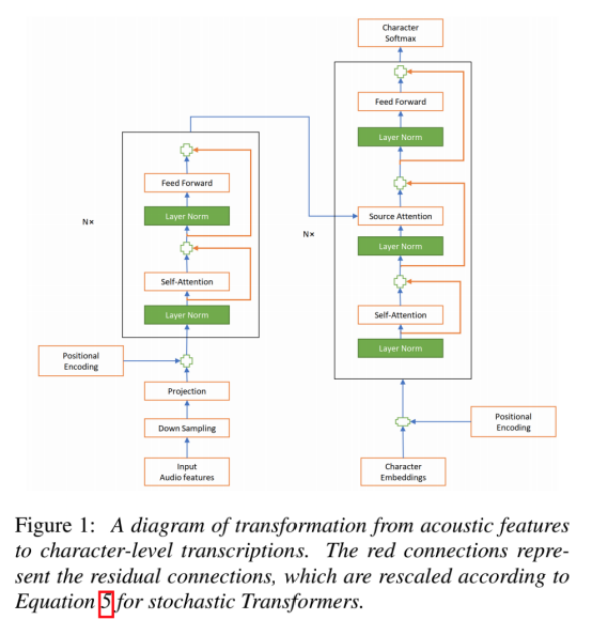
具体改进:
1. 随机加入residual layer。
2. encoder层数多于decoder层数(实验证明有效)。
3. 加入正则化。
实验结果:
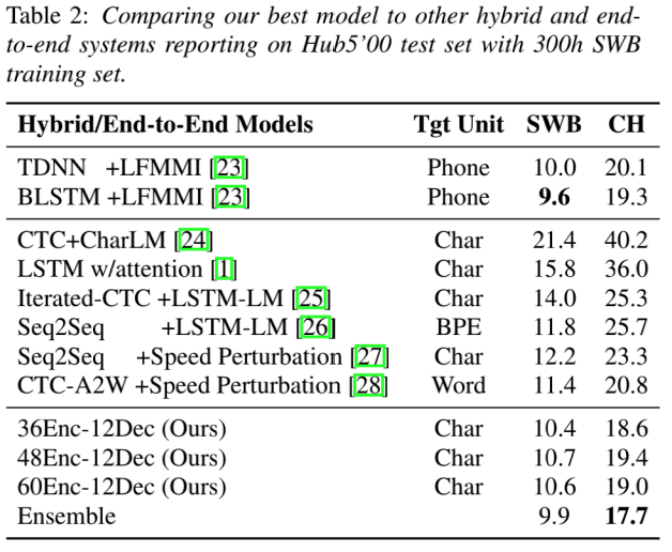
好于LSTM with attention(LAS),差于LSTM with LFMMI。
Attention#1&2:同时使用两种Attention
论文:https://arxiv.org/abs/1803.09519 (2018年)
作者机构:Karlsruhe Institute of Technology
Carnegie Mellon University
一句话总结模型结构:把LAS中encoder替换为Self-Attention
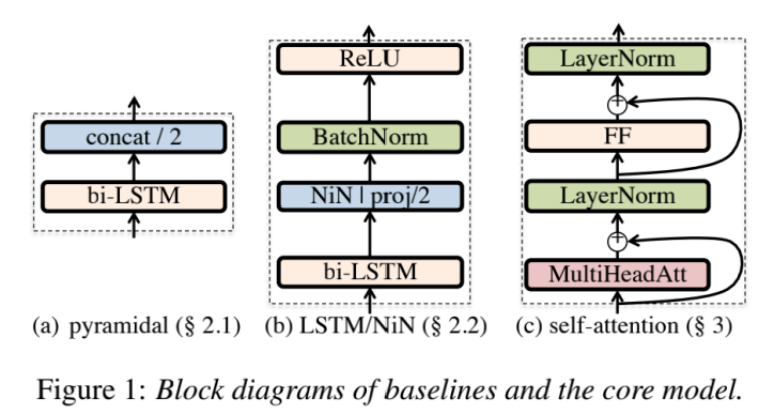
(a):原LAS中的encoder(第一个比较的baseline)
(b):另一论文对LAS中encoder的改进(第二个比较的baseline)
(c):本论文的enocer结构,使用Transformer Self-Attention
模型中使用的一些技巧:
1. 对每一Self-Attention改变形状进行降采样。
2. 尝试不同方法提供序列位置信息。
3. 对Attention加偏移量,从而限制Attention值。
实验结果:
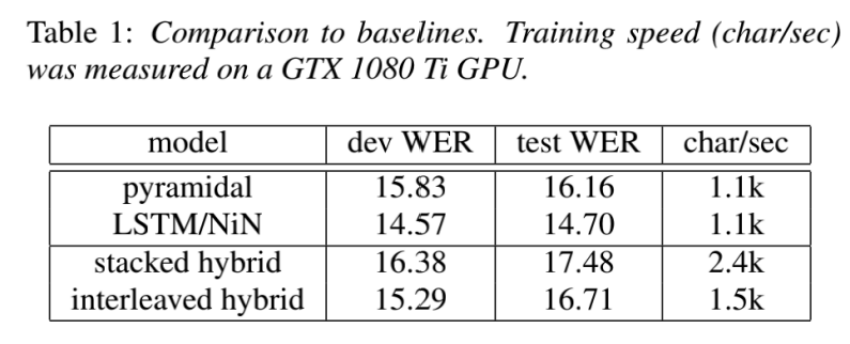
pyramidal: 第一个baseline,LAS原始模型
LSTM/NiN: 第二个baseline
stacked/interleaved hybrid: 本论文两种不同位置信息算法,从结果看WER和原结构相当,只是计算度加快了。
结合之前介绍的CTC、Transducer模型,和本次基于Attention的模型, 已经囊括了目前端到端模型的全貌。它们之间的性能比较怎么样呢?
端到端模型总体比较一
论文:https://arxiv.org/abs/1707.07413(2017年)
作者机构:百度
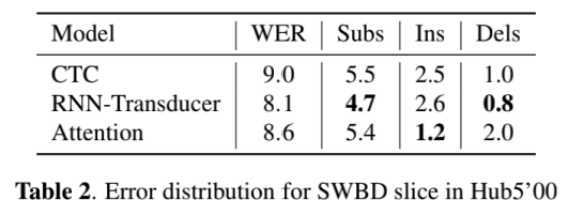
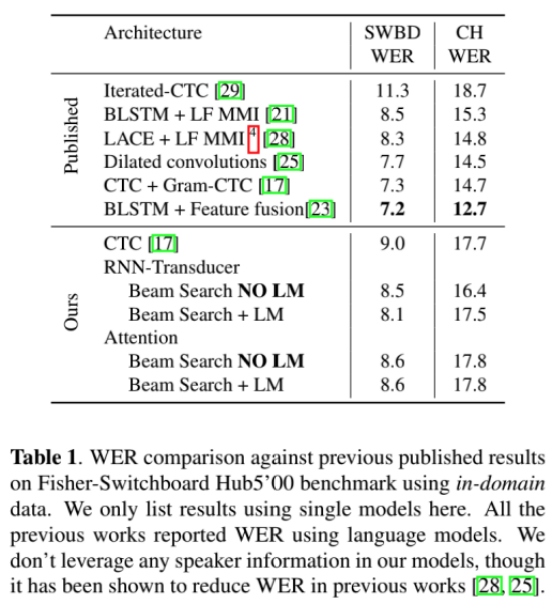
实验在SWBD上测试,Transducer模型取得的结果最好。
端到端模型总体比较二
论文:https://pdfs.semanticscholar.org/6cc6/8e8adf34b580f3f37d1bd267ee701974edde.pdf (2019年)
作者机构:Google,Nvidia
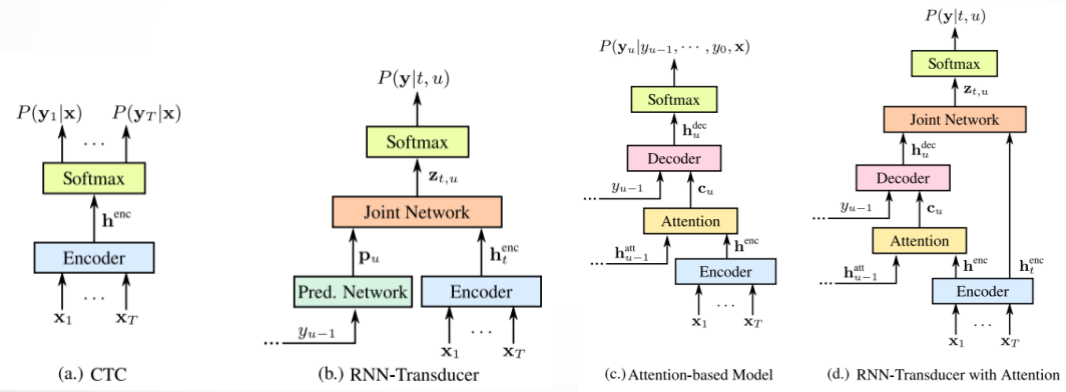
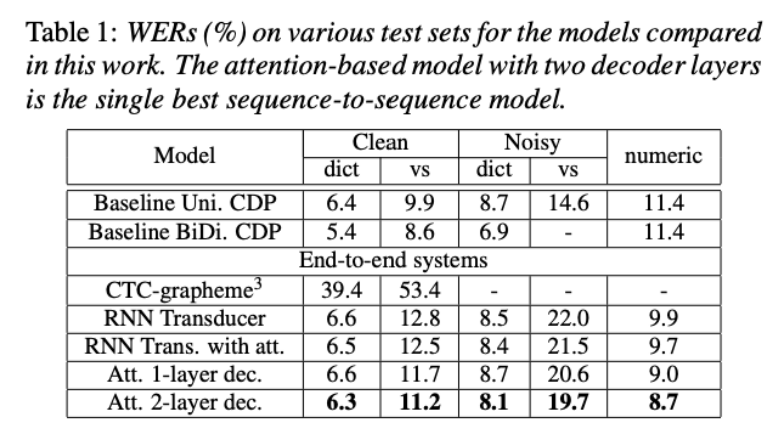
此实验是在Google自己的一个测试集上做的。
1. Attention based(LAS)在4个模型中最好。
2. 没有加入Transformer比较。
3. Baseline是CTC+语言模型,4个模型均未加额外的语言模型。
总结
本文列举了具有代表性的基于Attention机制的语音识别基本模型,以及在其上的改进,同时总体比较了各种端到端模型的性能。从实验结果来看,没有一种模型结构能在各种测试集上都优于其他模型,具体选用还得根据实际情况。
到此,关于语音识别系列的文章告一段落。
