





对一个机器学习实践者来说,机器学习就是应该用起来,而不是停留在理论上。春节即将来临,让我们来干点有趣的事情,看看怎么用机器学习写春联。
机器写春联回顾
让计算机写春联其实不是什么新鲜玩意儿,微软亚洲研究院2008年就发表了《基于统计机器翻译的中文对联生成系统》,使用基于短语的统计框架,根据输入的上联生成多个下联,然后对下联进行排序选出最好的结果。近两年百度、腾讯、阿里也开始推出了用AI写春联的系统。春联是对联的一种,这里我们扩展开来看如何写对联。
从翻译系统说起
有趣的是,我们可以把机器学习写对联看成一个机器翻译系统,普通的机器翻译比如把一句中文翻译成英文,如果我们把中文看成上联,翻译后的英文看成下联,其实道理是一样的。翻译系统让机器不断学习源语言和目标语言的训练数据得到一个模型,就可以翻译新的句子,同样我们让机器不断学习上联和下联得到一个模型,给它一个新的上联就能生成对应的下联。这看起来是顺理成章的事,但当初第一个想到这个点子的人还是不简单,也很巧妙。
有了这个思想,现在用机器学习做翻译系统都比较成熟了,我们借鉴现成的技术就能创建一个对联生成系统。当前翻译系统最流行的模型应该数seq2seq模型(sequence to sequence),即把翻译看成从一个源语言sequence序列进行编码,然后解码变成目标语言sequence,Google翻译系统也是这么干的。我们接下来先介绍一下seq2seq模型,然后看看怎么用Tensorflow实现这个模型,最后试验一下看看模型生成的对联结果。
seq2seq模型
seq2seq模型最早由论文https://arxiv.org/abs/1409.3215 提出,从下图中可看出,模型的输入端有一个Encoder进行编码,编码后的中间状态通过一个Decoder进行解码得到输出。如果是翻译系统,输入就是源语言,输出是目标语言;如果是问答系统,输入就是问的问题,输出为回答的答案;如果是对联生成系统,输入是上联,输出则是下联。
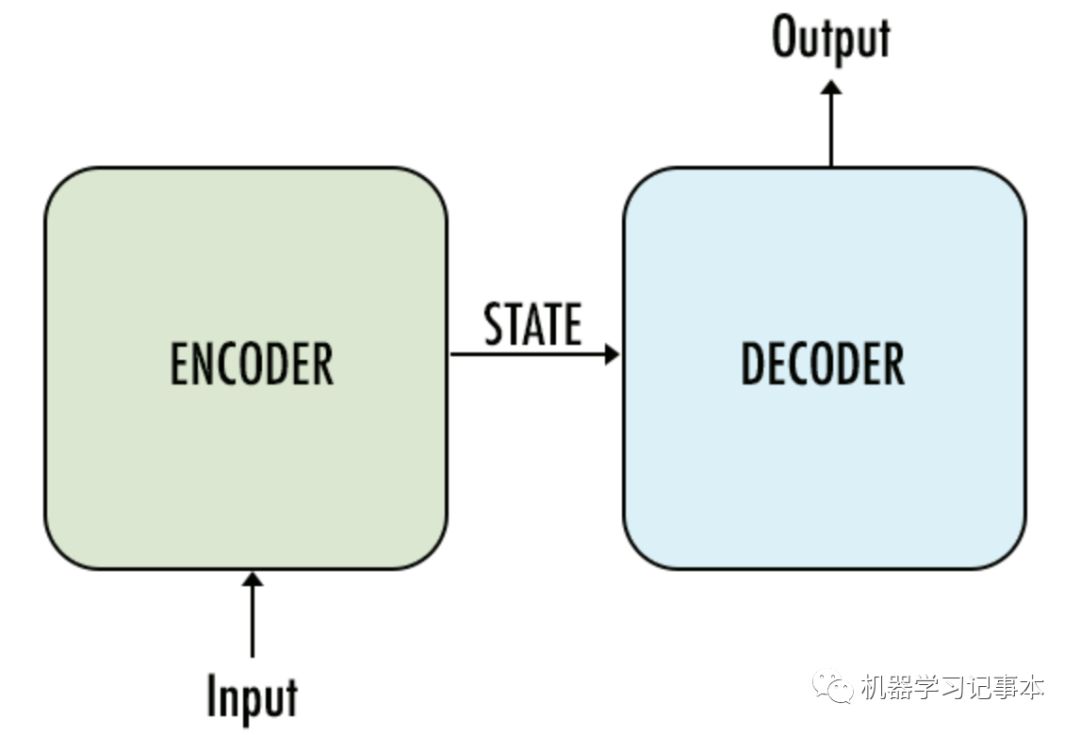
seq2seq模型图
拿问答系统为例子,模型就长下面这个样:
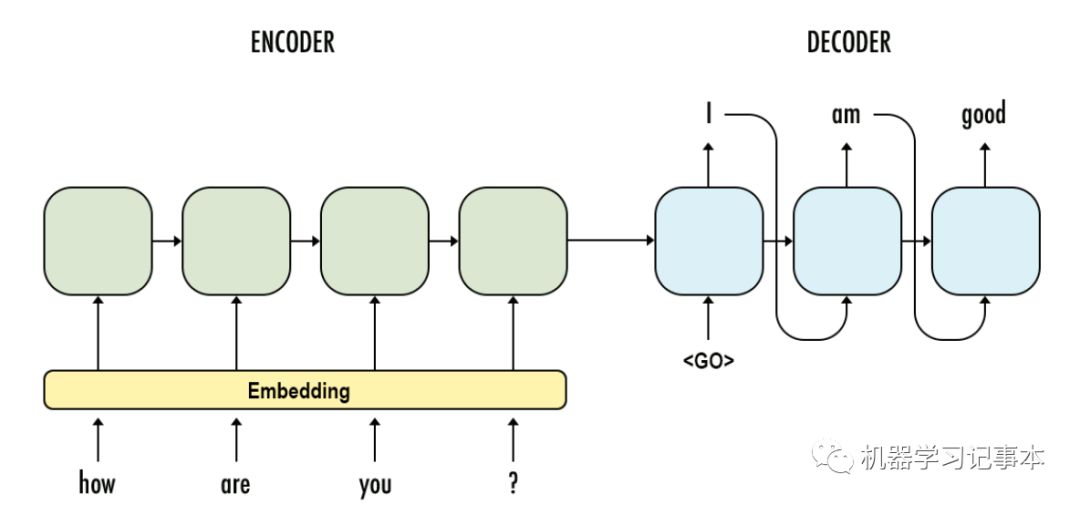
问答系统模型图
使用算法及RNN
有了seq2seq模型,具体怎么实现Encoder和Decoder呢?
上面问答系统模型图里,输入输出都是一个个句子。句子是有时序的序列,很容易想到RNN网络(Recurrent Neural Network)。粗略地讲,就是先把输入的句子转换为计算机能计算的向量V1(words representation),用RNN网络(Encoder)把该向量转换成另外一个中间向量V2,然后用另一个RNN网络(Decoder)把中间向量转换为输出向量V3,最后把V3转换为输出的最终句子。当然具体实现时要考虑正则化、dropout等,这里不展开讲。
RNN在自然语言处理中是一个很重要的算法,如果要看详细解释请前往http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/ ,该作者写的系列文章都讲得很到位,在NLP方面影响力挺大,其开源项目https://github.com/dennybritz下载量也不小。此处简单介绍一下RNN和几个相关算法的背景和关系。在RNN提出来之前,普通的神经网络系统在处理句子时没考虑各字词之间的关系,这显然不符合语言的特性,RNN模型把句子看成一个有时间前后关系的序列,并且能记住前面已经处理的内容(有记忆),之后又发展出了双向的RNN即BRNN和多层的RNN。但后来大家发现这个基本的RNN模型在具体求解过程中存在梯度爆炸或者梯度消失问题,简单说就是在计算模型具体参数时要么最后参数不断相乘越来越大(爆炸),要么越来越小(消失),导致模型很难算出来。所以大拿们有提出了两个改进的模型LSTM(Long Short Term Memory)和GRU(Gated Recurrent Units),其不同的地方在于改变了隐藏层计算方法,比如增加了遗忘门,忘掉之前的一些数据。目前用的最多的应该是LSTM。到此为止你大概知道了RNN、LSTM和GRU的来龙去脉,目前最流行的基于Attention的模型也是在它们上面一点点进化而来的。
系统实现
上面讲了如何用RNN/LSTM/GRU实现Encoder和Decoder,即实现seq2seq模型。这一节讲讲如何在代码层面上实现。
具体实现我在基于LSTM的翻译系统基础上修改而成,下面是翻译系统模型:
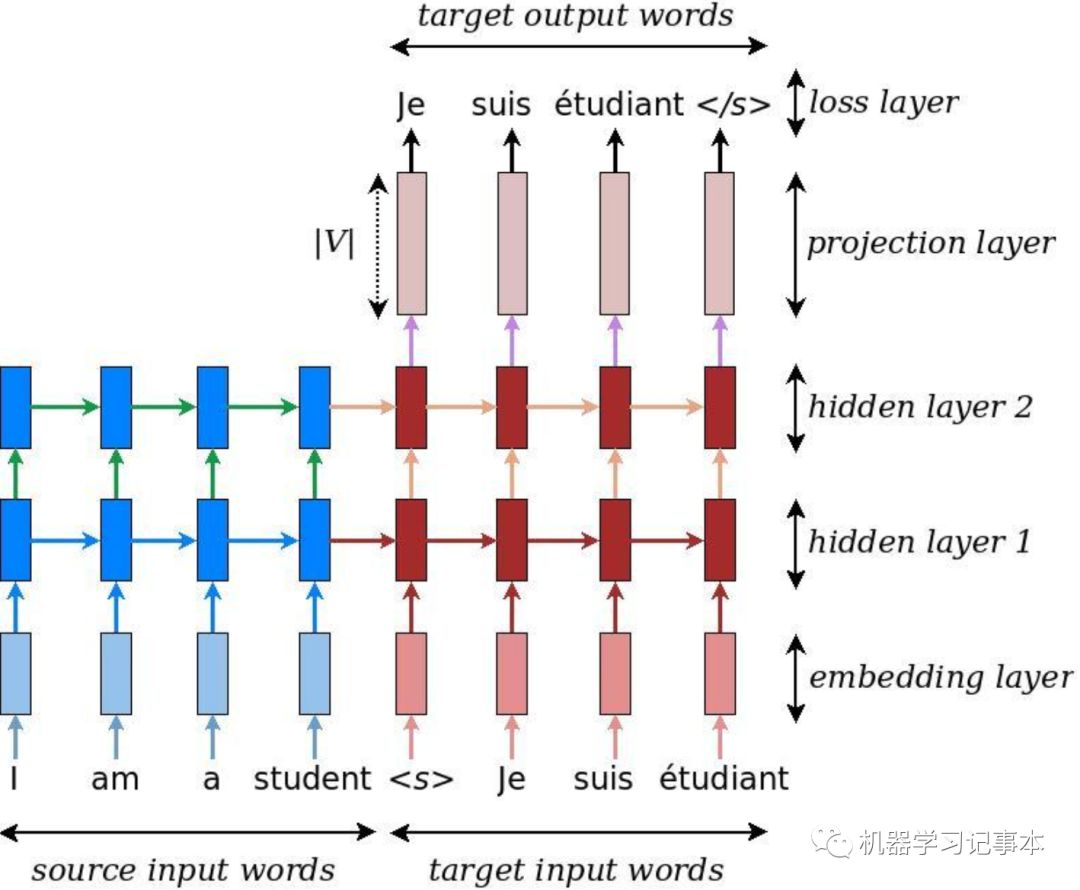
机器翻译模型图
来源:https://github.com/tensorflow/nmt#training--how-to-build-our-first-nmt-system
左边蓝色部分是Encoder,通过LSTM实现,右边红色部分是Decoder,通过另个一个LSTM实现。Encoder的输出作为Decoder最开始的输入,不断预测出一个一个的单词。
春联上联通过word2vec转换为向量,实现时向量长度取200,如果不熟悉word2vec的可翻翻我之前的文章复习一下。
Encoder-Decoder核心源码我用了https://github.com/deep-diver/EN-FR-MLT-tensorflow, 我的源码https://github.com/ChenYang-ChenYang/EN-FR-MLT-tensorflow 是其一个分支, 我只是修改了输入和输出部分,重构了代码把公共部分、训练和预测放到了3个文件seq2seq_model_core.py, couplet_training.py, couplet_prediction.py里,方便单独训练或者预测。如果要用jupyter notebook看,所有代码在dlnd_language_translationv2.ipynb文件中。我在Readme文件里以开始描述了如何使用本项目,后面部分我保留了父分支的关于机器翻译的内容。
实验结果
是驴是马拉出来看看吧!
如果你想试试,可以下载源码,创建一个python3.6 的环境,装上Tensorflow1.12,直接就可以训练一个模型,然后给任意上联,运行couplet_prediction.py输出下联。我在最新的Tensorflow1.12上测试过,其他版本没试。
训练数据在data文件夹中,来源自https://go.ctolib.com/wb14123-couplet-dataset.html,包括70000多副对联。在此要特别感谢数据提供者,简直是业界良心啊!
我在i7 CPU、32G内存机器上跑一轮训练大概需要1小时10分钟,分别试过跑1轮,2轮,4轮和10轮的结果。训练1轮的模型结果基本没法用,2轮和4轮结果就已经不错了,下面是用训练10轮(大概12小时)后的模型测试的一些比较好的结果,上联我输入,下联机器生成:

上面中间4副春联的上联是不是特别眼熟,每年过年大街小巷到处都是。我印象最深的是”花开富贵家家乐”,小时候邻居家就这幅,每天路过都看一遍,一辈子都忘不了,不过当时的下联是”灯照吉祥岁岁欢”。从测试结果看,对仗普遍都不错,但是连续的字比如”家家乐”,机器没有学到生成连续的对仗。
有人可能会问横批呢,由于训练数据中只有上下联没有横批,所以模型没法生成横批。要是有训练数据,道理也是一样的,把横批当成标签训练就是。
总结
我们从用机器学习做翻译的模型开始介绍,嫁接到写对联上,从中你了解到了seq2seq模型的原理,以及RNN相关算法的来龙去脉,RNN是NLP中最重要的算法之一。然后我们介绍了具体实现和实验结果。如果你有兴趣,不妨下载源码运行试试。最后也是最重要的,当然要提前祝你新年快乐了,拜个早年!欢迎转发给感兴趣的朋友看看。
