




上篇汇总介绍了文本向量化的主要模型,今天详细谈谈其中的word2vec。此文也是我对之前学习word2vec的整理,写作之前又从新拜读了几位知乎大神的文章。
自然语言处理(NLP)中,语言模型(Language Model)是一个很重要的领域,很多研究成果也从中而来,word2vec就是一个例子。语言模型的任务就是根据已知文本预测后续文本,广泛应用于语音识别、机器翻译和文本摘要等。我们根据语言模型的发展,一步步看word2vec的来龙去脉。
语言模型主要包括两类,一是基于计数的模型,二是在连续空间计算预测的模型。
1. n-gram语言模型
n-gram模型是基于计数的模型,即基于语料库中词与词之间的频率及其他统计量来预测。已知前t个词,需要预测第t+1个词,遍历词库中各词出现在t+1位置的概率,概率最大的词即为预测结果。利用Bayes公式,第t+1位置各词出现的概率可根据前t个词的概率求出,n-gram模型假设(Markov假设)第t+1个词的概率只和前n-1个词相关,这样就减少了模型计算量。前n-1个词的具体概率值通过词库中该词出现的次数统计近似获得。给定一个词库,计算好这些概率值,下次对新的词需要预测后续内容时,利用之前计算好的概率值就可算出后续词的概率,从而选择概率大的词做为预测。为尽量避免使用数学公式,此处没列出Bayes公式和Markov假设公式。
n-gram模型的缺点是词库中各种组合太多,计算量太大,此外,模型主要考虑词或词串之间的匹配,没从语法或语义上考虑,因此有了下面的神经概率语言模型。
2. 神经网络语言模型
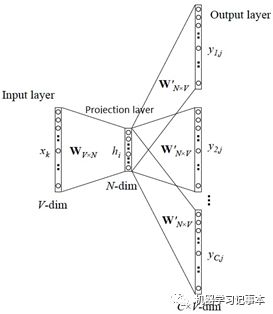
神经网络语言模型属于在连续空间计算预测的模型。2003年Bengoi等人在ANeural Probabilistic Language Model论文中提出了前馈神经概率语言模型,并开始使用词向量,其模型结构如下:
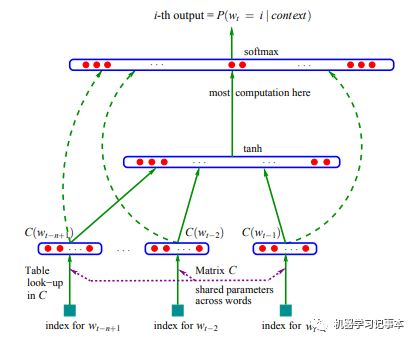
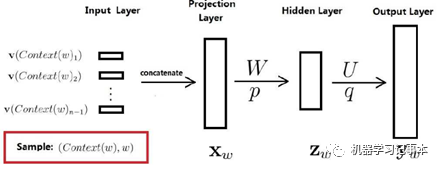
用下图能更容易说明一些,整个网络分为4层,输入层、投影层、隐藏层和输出层。
来源:https://blog.csdn.net/itplus/article/details/37969519
对语料库中任意词w,其前n-1个词记为Context(w),这样(Context(w),w)就是一个训练样本,其中Context(w)为输入,w为标签。Context(w)中每个词有一个初始向量,共n-1个,所有n-1个向量前后连接起来组成一个新的向量,就是投影层的x。
隐藏层z=tanh(Wx+ p)
输出层y=Uz+ q
输出层的y是一个语料库长度大小的向量,再使用softmax归一化,第i个位置的值就代表当输入是Context(w)时,下一个词为语料库中第i个词的概率。我们知道Context(w)的下一个词是w,就可以用传统的机器学习套路,最小/大化目标函数,不断训练更新获取模型中的参数v,W,p,U,q,其中v就是我们要寻找的各个词的向量表示。
很容易想到,既然有前馈神经网络模型,就会有人尝试循环神经网络RNN(Recurrent Neural Network),这里就不展开讲了。
和n-gram模型比,神经网络语言模型通过词向量来体现词之间的相似性,这是个质的改进。
3. 神经网络语言模型改进及word2vec
2013年,以Mikolov为代表的Google团队发表了著名的论文Efficient Estimation of Word Representations in Vector Space,揭开了word2vec的序幕。该团队认为之前的神经网络模型计算开销太大,主要原因在于隐藏层,他们提前了两个新的模型,去掉了隐藏层。
3.1 Continuous Bag-of-Words模型
该模型简称CBOW模型,其根据上下文预测中心词。其简化模型如下图:
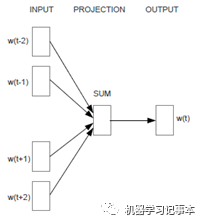
接下来我们具体分析word2vec生成的过程。常见论文有两种解释方法,主要区别是输出层是随机生成的向量还是one-hot编码。
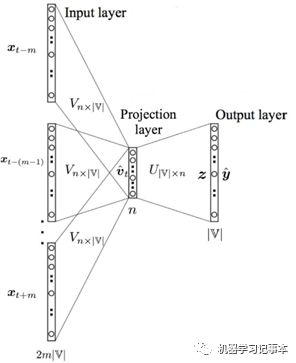
输入层为随机生成向量的计算过程:
1) 输入层: 2m×n 个节点,上下文共2m 个词的n维向量;
2) 投影层:n 个节点,上下文共 2m 个词的词向量相加求得的平均值;
3) 投影层到输出层的连接边:输出词矩阵 U,大小|V|×n;
4) 输出层: |V|个节点,通过softmax,第 i 个节点代表从2m个词预测出中心词为第i个词的概率。
5) 输出层预测出的中心词和2m词真实的中心词做比较,不断更新模型参数,最终得到的更新后的输入层向量就是各个词的向量。
输入层输入为one-hot编码的计算过程:
1)输入层: 2m×|V|个节点,2m个词的one-hot 编码;
2)输入层到投影层矩阵V:n×|V|维;
3)投影层:n 个节点,上下文2m 个词的one-hot 表矩阵V相乘后得到的词向量求和再求平均,即 V*x 求和再求平均;
4)投影层到输出层的矩阵U: |V|×n维;
5)输出层: |V|个节点,通过softmax归一化,第 i 个节点代表从2m个词预测出中心词为第i个词的概率。
6)输出层预测出的中心词和2m词真实的中心词做比较,不断更新模型参数,最终矩阵V中的每列n维向量就是语料库中对应词的向量,一共|V|个。
比较上面两种结构,我们发现本质是一样的,输入层为one-hot编码时,和输入层与投影层之间矩阵V(初始值随机生成)相乘后只保留了1对应向量的部分,即该词的向量,和随机生成输入词的向量本质一样。
知乎上有个很好的例子,一步步展示以one-hot为输入如何生成向量,我照搬过来,知乎链接地址为https://www.zhihu.com/question/44832436/answer/102527991作者:crystalajj
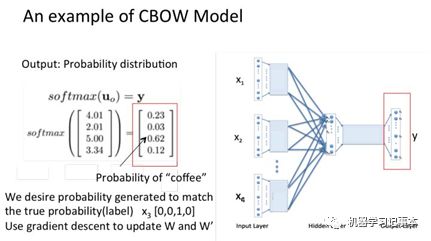
假设我们现在的Corpus是这一个简单的只有四个单词的document:{I drink coffee everyday}我们选coffee作为中心词,window size设为2也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
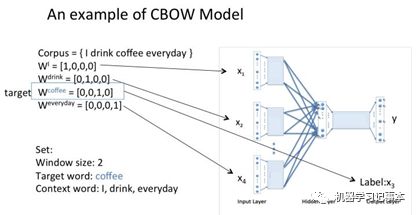
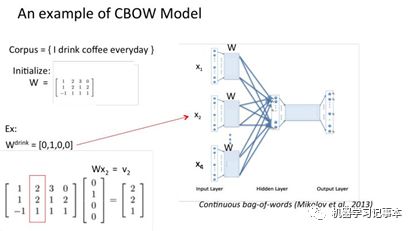
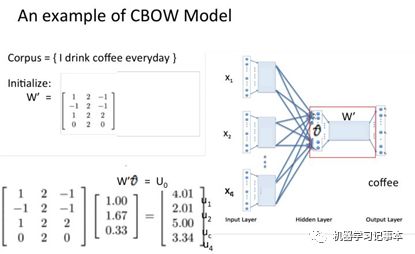
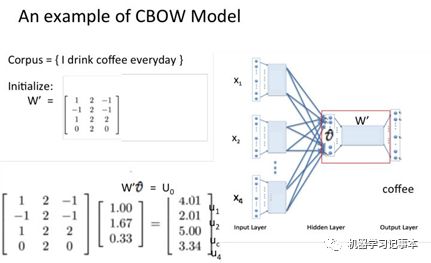
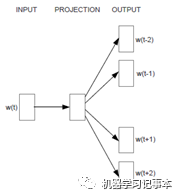
3.2 Continuous Skip-gram模型
Skip-gram模型思路和CBOW模型相反,即根据中心词预测上下文词。简化模型图如下:
细节图如下:
算法过程和CBOW类似,不再累述。
4. 算法改进
由于上述模型中最后都用softmax归一化,实际计算中softmax开销太大,Mikolov提出了两个改进算法,其目的是减少投影层到输出层的计算开销。
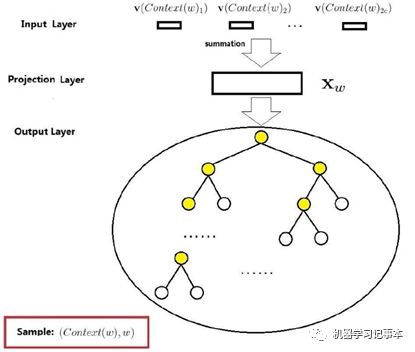
4.1 Hierarchical Softmax
其主要思想是用Huffman树替代输出层的softmax,用于CBOW时模型如下图:
来源:https://blog.csdn.net/itplus/article/details/37969519
语料库中的词当Huffman树的叶子节点,利用投影层x和Huffman树来定义输入是Contex(w)时,输出是w的概率函数,细节不展开。Hierarchical Softmax也可用于Skip-gram,不同之处是输入层是一个中心词的向量。
4.2 Negative sampling
Negative Sampling是使用随机负采样,其目的也是提高计算速度,并提高词向量的质量。
之前所有算法中训练样本都是(Contex(w),w),即都是正样本,我们需要生成一些负样本,负样本采集原则是使语料库中的高频词被选的概率大,即带权采样。然后计算过程中增大正样本概率,降低负样本概率,不断迭代目标函数计算出各词向量。
本文从基本的n-gram语言模型开始,到基本神经网络语言模型介绍如何生成词向量,然后重点描述了Mikolov等人在改进的CBOW和Skip-gram模型上提出了word2vec,并使用了Hierarchical Softmax和Negative Sampling算法优化的计算开销。学习和整理过程中主要参考了以下文章,受益匪浅:
Efficient Estimation of Word Representations in Vector Space,Tomas Mikolov等
全面理解word2vec:https://zhuanlan.zhihu.com/p/33799633
word2vec中的数学原理详解:https://blog.csdn.net/itplus/article/details/37969519
word2vec是如何得到词向量的:https://www.zhihu.com/question/44832436/answer/102527991
秒懂词向量Word2vec的本质:https://zhuanlan.zhihu.com/p/26306795
