




任何文本要通过计算机处理,都得转换为计算机能理解的数字,常用办法是转换为一个向量。今天专门谈一谈文本向量化转换,包括了当前各种常见的模型。
1. One-hot编码
谈文本向量化,基本都会提到one-hot编码,他是理解向量化的基础,就像我们学数学先要学1,2,3一样。但由于其明显的缺点,实际工程中真正使用不多。
假设我们要向量化的文本里有N中不同的词,One-hot编码的思想是构造一个N维向量,每个词对应向量中一个位置,该位置为1其他位置全为0的向量就代表该词。比如有两个文本“Youare a very good man”“We are verylucky, lucky”,其中有8个不同的词,其各自的向量表示为:You:[1,0,0,0,0,0,0,0], Are: [0,1,0,0,0,0,0,0], a: [0,0,1,0,0,0,0,0],very: [0,0,0,1,0,0,0,0],good:[0,0,0,0,1,0,0,0], man:[0,0,0,0,0,1,0,0],We:[0,0,0,0,0,0,1,0], lucky:[0,0,0,0,0,0,0,1]
你已经看出来了,当词库非常大的时候,比如有1万个词,这样的表示方法每个词向量长度为1万,其中除了一个位置为1其它9999个位置全是0,太过于稀疏,储存和计算都不方便。
2. Bag of Words模型
Bag of Words也叫词袋模型,其思想基于one-hot编码,就像把词放在袋子里,不考虑文本里词与词之间的顺序,一个句子对应的向量就是各个词one-hot编码的叠加,上面“Youare a good man”对应向量是[1,1,1,1,1,1,0,0],“Weare very lucky, lucky”对应向量是[0,1,0,1,0,0,0,2].
该模型优点是简单易用,但有one-hot编码同样的问题,另外一个大的缺点是没考虑词与词之间的关系,而自然语言处理中词之间的关系十分重要。
3. TF-IDF模型
从Bag of Words模型中可看出其考虑了词的频率,比如lucky在第二个文本中出现了2次,向量中对应位置为2,可认为词频越高该词重要性越高。但有的词如a,the, very等在各个文本中经常出现,其重要性并不高,Bagof Words模型表示并不准确,因此有了TF-IDF模型。
TF-IDF的核心思想是:如果一个词在该文本中出现频率高但在其他文本中出现频率低,表明改词在该文档中独有,则其重要性越高。像a,the, very这样的词,在每个文本中出现的频率都高,其最终重要性并不高。
TF-IDF分两部分,TF为Term Frequency,即一个词在该文本中出现的频率,IDF为Inverse Document Frequency,即逆文本频率,简单理解就是文本总数除以含有该词的文本数。两部分乘起来作为向量中对应词的最终值。
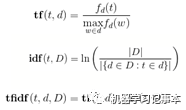
4. Word2Vec模型
Word2Vec隆重登场!前面3个模型都有一个重要的缺陷,没有考虑词与词之间的上下文关系,Word2Vec专门来解决此问题。Word2Vec的思想是如果两个词之间关系越紧密,对应的向量距离也应该越近,比如“猫”和“狗”的向量之间距离应该比“猫”和“苹果”向量之间的距离近。
如何从词转换成Word2Vec向量,我会单独分一篇文章详细讲解,这里简要介绍一下。其仍然从词的one-hot编码出发,通过训练神经网络找出神经网络权重矩阵,矩阵中每一列就对应一个词的向量。Word2Vec有两种训练方法获取最终向量,一是Skip-Gram,以一个词为中心预测其上下文的词,神经网络训练的输入为中心词,输出为上下文词;另一个叫CBOW,从上下文词语预测中心词。实际实现时为了加快训练速度,采用了两个加速算法,一个叫NegativeSample,另一个叫HierarchicalSoftmax。
Word2Vec的另一个优点是你可以指定所得向量的长度,这样可以降低下一步机器学习的复杂度。
5. GloVe模型
GloVe全称Global Vectors for WordRepresentation,是斯坦福大学提出的通过非监督学习获取词向量的方法,官网见https://nlp.stanford.edu/projects/glove其基本思想是先构建一个词汇表的共现矩阵,假设一共有V个词汇,共现矩阵大小为V*V,第i行第j列表示以第i个中心词wi ,第j个背景词 wj出现的次数。接下来是常规的机器学习方法,定义一个损失函数并最小化,得到中心词向量vj与背景词向量vi 的和作为中心词向量的表示。
实际应用中,GloVec和Word2Vec的性能区别不大,有论文专门做了比较,GloVe对于较大的数据集训练会更快。
6. FastText模型
FastText是一个文本分类模型,分类过程中同时产生了词向量,其模型框架和Word2Vec的CBOW非常类似。
介绍FastText不得不提n-gram。Word2Vec中把每个单词当成最小组成部分,比如bird和birds被看成两个不同词,但实际上这两个词联系很紧密,如果能把粒度分得再细一些会更好。n-gram从字符级别来分词,如果n取3,birds的3-gram(也叫trigram)表示为<bir,ird, rds>,这样bird和birds的表示就有很多相同的地方,FastText就用n-gram来表示单词。
FastText的训练同样有输入层、隐含层和输出层。输入层是整个文档的所有词的n-gram特征表示,隐含层对这些特征向量叠加取平均,输出层用softmax分类器进行分类。模型详细内容参照https://github.com/facebookresearch/fastText
以上就是当前文本向量化中主流的模型,其中Word2Vec应用最广泛,我目前项目中也使用Word2Vec,下一篇文章详细解释Word2Vec。
