




问题引入
常见的激活函数有sigmoid, relu,Leaky ReLU等,上次我们介绍了sigmoid和tanh,今天讲一下relu函数,那么这个函数的优点是啥呢?
问题解答
Relu激活函数的表达式如下:
此函数的图像和导数的图像如下所示:
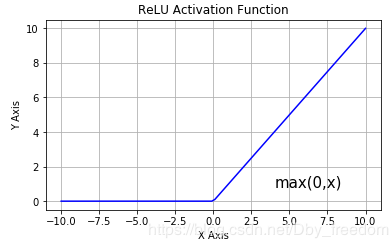
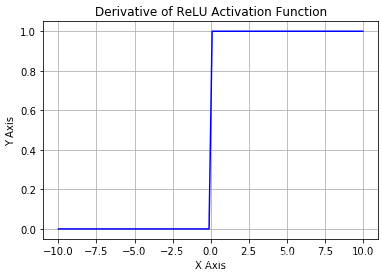
可以看到这个函数的梯度在大于1的时候是保持恒定的。这样不会造成梯度的消失现象。
优点如下:
在区间变动很大的情况下,ReLu 激活函数的导数或者激活函数的斜率都会远大于 0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中,使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。 sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。 需注意,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会产生这个问题。
参考
https://baijiahao.baidu.com/s?id=1653421414340022957&wfr=spider&for=pc
喜欢就关注一下啦~~~

文章转载自百面机器学习,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
