




前言
因为今年要接手运维公司一套ClickHouse生产集群,为了能更好的运维ClickHouse,计划先提前好好学习下这块知识,推出一个ClickHouse学习系列,记录学习过程,也希望能在某些方面帮助到对此有需求的朋友。
一、ClickHouse介绍
ClickHouse是一个用于OLAP(联机分析处理)的开源 列式数据库,ClickHouse通常被简称为CK。
对ClickHouse的介绍,通常描述为其为俄罗斯IT搜索引擎公司Yandex为Yandex.Metrica网络分析服务开发的,Yandex.Market使用ClickHouse来监控网站的可访问性和KPI。俄罗斯的Yandex相当于中国的百度,在俄语市场占有很高的搜索引擎份额,是俄罗斯最受欢迎的搜索引擎。ClickHouse允许分析实时更新的数据,2016年开始走红,Apache Spark此时也恰好处于鼎盛时期,2016年6月ClickHouse成为Apach旗下托管的开源数据库软件。
ClickHouse 主打的就是一个快,登录ClickHouse官网首页,主页最醒目的位置就是突出其快的特点。
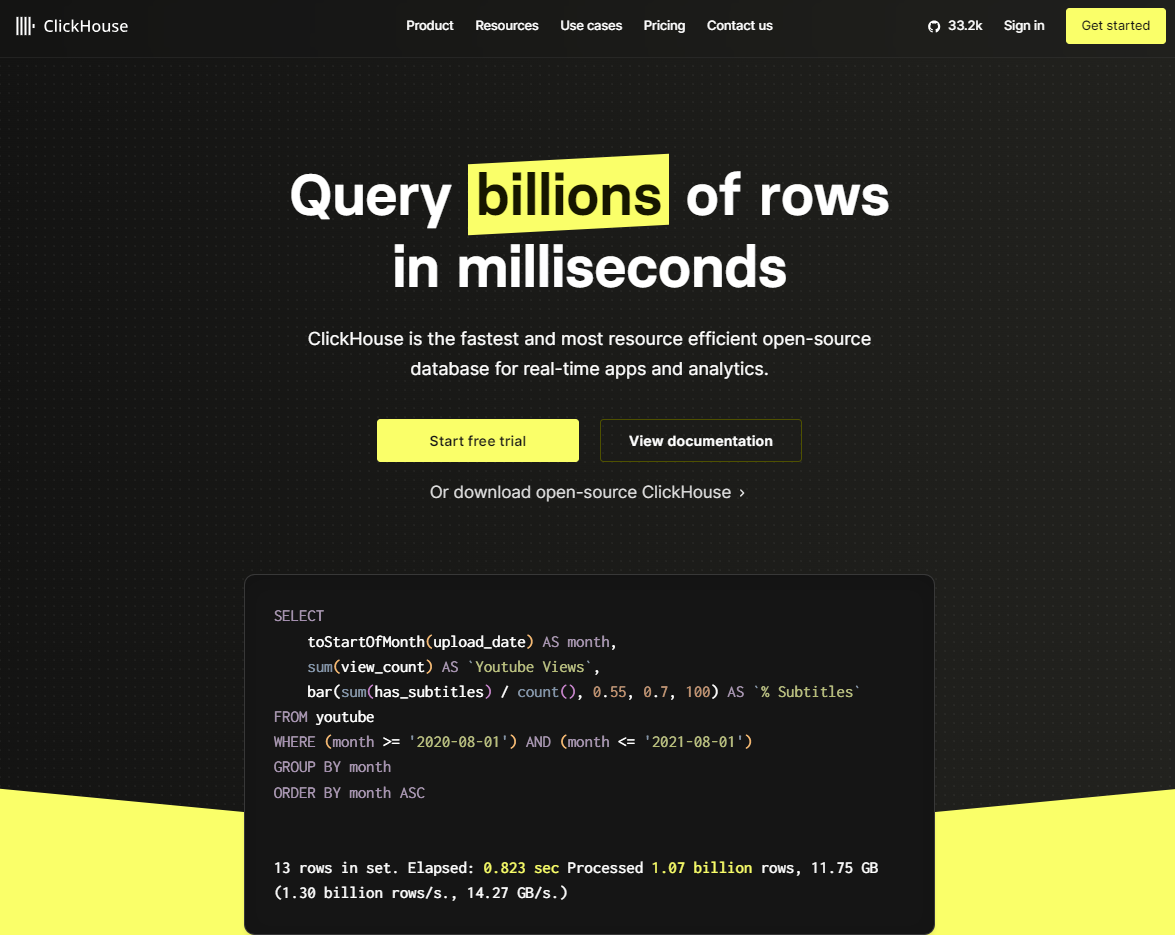
能有多块呢,在ClickHouse主页显示的这段SQL中,显示查询在0.823秒内完成,处理了大约10.7亿行数据,数据量为11.75 GB,处理速度为每秒1.30亿行或14.27 GB。
ClickHouse目前也是非常流行,其在github显示 star达到 33.2K。
说个题外话,根据网上查询到的资料,Yandex(俄语:Яндекс,NASDAQ:YNDX)是一家俄罗斯互联网企业,旗下的搜索引擎曾在俄国内拥有逾60%的市场占有率。ClickHouse最初是为Yandex Metrica(世界第二大Web分析平台) 而开发的,旨在处理大规模数据分析场景下的实时查询,ClickHouse的第一个原型在2009年出现,2014年底,Yandex.Metrica 2.0版发布。新版本有一个用于创建自定义报告的接口,并使用ClickHouse存储和处理数据。
2021年9 月 20 号,ClickHouse的创建者 Alexey 在 GitHub 宣布他们决定正式从 Yandex 独立,成立一个公司:ClickHouse, Inc,总部设在美国加州旧金山,以持续发展ClickHouse,最初由Index Ventures、Benchmark Capital和Yandex共投资 5000 万美元。2021年10月Coatue Management、Altimeter Capital等B轮融资2.5亿美元,使公司估值达20亿美元。
俄乌战争爆发后,ClickHouse公司突然在官网上发表了一篇官宣文章:We Stand With Ukraine,原文链接:https://clickhouse.com/blog/we-stand-with-ukraine/,表态其在政治立场上支持乌克兰,其在俄罗斯的工程团队也迁移到了荷兰首都阿姆斯特丹。
让我们想到了Oracle官网在俄乌战争中对乌克兰的支持,关闭其对俄罗斯的MOS服务,让我们清醒的认识到,科学无国界,真的就是一句假话。
我们暂且不谈政治因素,仅从技术方面讨论ClickHouse,相较于Spark、Hadoop,ClickHouse更轻量。
自2017 年ClickHouse被引入国内,国内如阿里巴巴、腾讯、字节、携程、有赞、快手等国内许多头部大厂都在深度使用ClickHouse 技术,《福布斯》(2020年)列出的最大IT公司名单,超过一半的公司都在以某种方式使用ClickHouse。
ClickHouse使用C编程语言编写,因为C继承了很多C语言的特性,可以和底层硬件打交道,所以其性能方面表现很强。
另外ClickHouse作为一款OLAP数据库软件,支持类SQL查询,能够使用 SQL 查询实时生成分析数据报告,支持多种函数,支持数组和嵌套数据结构等。
ClickHouse拥有多种特性,接下来,我们将详细聊聊ClickHouse的一些主要特性。
二、ClickHouse特性
2.1 列式存储
我们都知道在传统行式数据库系统中,数据是按照行进行存储的,处于同一行中的数据总是被物理的存储在一起,比如我们日常比较熟悉的Oracle、DB2、MySQL、SQL Server等关系型数据库,都是采用行式存储的。
与行式数据存储相比,列示存储具有如下一些特性:
-
数据存储方式: 与传统的行式数据库不同,列式数据库将每一列的数据存储在一起。这意味着对于给定的表,每一列都存储在独立的数据文件中。
-
IO优化: 当执行查询时,只有参与查询的那些列会被加载到内存中。这样可以大幅减少不必要的数据读取,因为不涉及查询的列数据不会被读取,从而优化了IO性能。
-
压缩: 列式存储由于数据的同质性,使得数据压缩算法(如LZ4、ZSTD等)更加高效,能够显著减小存储空间。
-
向量化执行: ClickHouse通过对列数据进行批处理来实现向量化查询执行,这意味着它可以一次处理一列中的多个值,从而提高处理速度。
-
数据分区: ClickHouse支持水平分区,可以将数据分散在不同的分区中,每个分区包含一个或多个列的数据。这有助于并行查询和数据管理。
假设我们有一个名为events的表,其中包含以下列:
event_date (日期)、event_type(事件类型)、event_count (事件数量)
如果我们想要查询某个日期范围内的所有事件类型及其数量,我们可能会执行类似于以下的SQL查询:
SELECT event_type, sum(event_count)
FROM events
WHERE event_date >= '2023-01-01' AND event_date <= '2023-01-31'
GROUP BY event_type;
在这种情况下,ClickHouse会执行以下操作:
-
读取优化: 只读取event_date、event_type和event_count这三列的数据文件。
-
压缩和解压: 读取时,只解压这三列的数据,其他列的数据保持压缩状态,不参与处理。
-
批处理: 系统会以向量化的方式处理每一列的数据,例如,sum(event_count)会在内部以批量形式计算,而不是逐行处理。
通过以上方式,ClickHouse能够高效地处理大量数据的分析查询,这也是其在OLAP场景下备受青睐的原因之一。
接下来,我们将用一副图来详细对比行式存储和列式存储的差异,如下图所示。
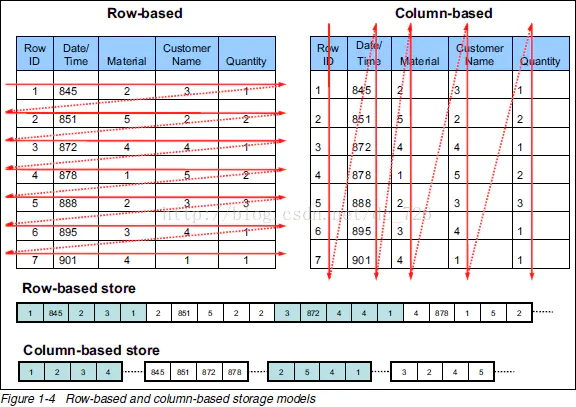
这幅图清楚地展示了行式存储和列式存储两种不同的数据库存储模型。
行式存储:
- 在行式存储中,每一行的数据是连续存储的。这意味着一个完整的数据记录(例如,一个包含Date/Time、Material、Customer Name和Quantity的记录)是一个接一个地存放的。
- 这种存储方式适合于事务处理系统(如传统的关系数据库管理系统),因为它能够快速写入新记录和修改现有记录。
- 行式存储的劣势在于查询大量数据时可能会较慢,因为即使只需要访问记录中的少数几个字段,也必须读取整行的数据。
列式存储:
- 列式存储将每一列的数据连续存储。也就是说,同一列的所有条目都被放在一起,如图中的Date/Time列、Material列等。
- 这种存储方式适合于分析型数据库系统,如ClickHouse,因为它可以快速读取某一列的数据,这对于分析和报告特别有用,因为这些操作通常只涉及表的一部分列。
- 列式存储的优势在于它可以有效压缩数据,因为列中的数据往往具有高度的相似性,这使得压缩算法能够有效减少所需的存储空间。
- 另一个优势是执行查询时,如果只需要特定的几列数据,那么数据库可以快速读取必要的列,而不必加载整个记录。
在图中的下方,还展示了一个行式和列式存储的物理表示,可以看出行式存储是按照1、2、3…的顺序存放每一行的数据,而列式存储则是按照列来存放数据,即先存放所有的Date/Time数据,然后是所有的Material数据,依此类推。
2.2 DBMS特性
ClickHouse几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复等功能。
1.SQL支持:
- ClickHouse几乎支持标准SQL的全部语法,这使得从其他数据库系统迁移到ClickHouse或者使用传统的数据库技能进行操作变得相对容易。
- DDL (数据定义语言)操作:允许用户创建、修改、删除表和数据库结构。这包括创建表(CREATE TABLE),修改表结构(ALTER TABLE),和删除表(DROP TABLE)等操作。
- DML (数据操纵语言)操作:涵盖了数据的查询(SELECT),插入(INSERT),更新(UPDATE),和删除(DELETE)等操作。尽管ClickHouse主要用于OLAP场景,但它也支持在一定程度上的事务性操作。
- 函数支持:ClickHouse提供了丰富的内置函数,包括数学函数、字符串函数、聚合函数以及时间和日期函数等,以支持复杂的数据处理和分析需求。
2.用户管理及权限控制:
- 用户管理功能允许管理员创建和管理数据库用户,为不同的用户分配不同的角色和权限。
- 权限管理系统允许细粒度的权限控制,可以指定哪些用户可以访问哪些数据,以及他们能进行哪些操作。这对于保障数据安全和合规性非常重要。
- ClickHouse支持角色基的访问控制(RBAC),管理员可以通过角色将权限分配给用户,简化了权限管理。
3.数据的备份与恢复:
- ClickHouse支持数据备份,可以将数据导出到文件中,以便进行灾难恢复。备份可以是全量的也可以是增量的。
- 数据恢复过程涉及将备份的数据重新导入到ClickHouse中,以恢复到某个特定的时间点的状态。
- ClickHouse的备份和恢复策略可以通过使用第三方工具或者自定义脚本来实现自动化,确保数据安全。
4.附加特性:
- 支持数据的分区和分片,这有助于管理大规模的数据集,提高查询效率和数据处理的速度。
- 提供了监控和分析工具,帮助用户理解查询性能和优化数据库操作。
- 支持数据复制和跨多个集群的数据分布,确保了高可用性和数据的持久性。
ClickHouse提供了一个全面、灵活和强大的DBMS平台,适用于需要高速数据分析和报告的应用场景。它结合了传统SQL数据库的易用性与现代列式数据库的高性能特点,使其成为处理大规模分析工作负载的理想选择。
2.3 多样化引擎
如果熟悉MySQL的朋友都知道,MySQL具有表引擎的概念,比如Innodb、MyISAM、Memory 等引擎。ClickHouse也有引擎的概念,和MySQL不同的是,ClickHouse除了具有表引擎,还有库引擎的概念,接下来我们来聊一聊ClickHouse的库引擎和表引擎,以及和MySQL的引擎对比。
1.库引擎
首先,让我们聊聊ClickHouse的库引擎。在ClickHouse中,库引擎相对比较简单。最基本的是Ordinary,它就像一个普通的文件夹,你的数据就存储在这里,没有什么特别之处。然后是Atomic,它的亮点在于支持原子DDL操作,这就像是给你的数据变更加了一个“安全网”,确保所有的变更都是一气呵成的,没有半途而废的情况。
Atomic 数据库引擎是在 ClickHouse 的更新版本中引入的。它支持非阻塞的表结构更改,允许对表进行原子重命名,并且在DROP TABLE操作中不会立即删除数据,而是将其标记为删除,稍后由后台清理进程删除。这使得Atomic引擎在进行表结构更改或管理表时更为安全和灵活。
Ordinary 数据库引擎是传统的 ClickHouse 数据库引擎,它不具备Atomic引擎的一些高级特性,如原子表结构更改等。
在 ClickHouse 的较新版本中,Atomic 数据库引擎是默认的数据库引擎。这意味着当你创建新的数据库时,如果没有指定引擎类型,ClickHouse 会默认使用 Atomic 引擎。
创建库引擎的实例如下:
1) Ordinary引擎:
--创建Ordinary引擎时需注意,Ordinary首字母需要大写,不然会抛出异常。
-- 创建一个Ordinary数据库的示例:
CREATE DATABASE mydb ENGINE = Ordinary;
2) Atomic引擎允许执行原子的DDL操作,意味着这些操作要么完全应用要么完全不应用,不会有中间状态。
-- 创建一个Atomic数据库的示例:
CREATE DATABASE mydb ENGINE = Atomic;
除了Ordinary和Atomic,ClickHouse官方提到还支持以下库引擎,分别是:
- MySQL
- MaterializeMySQL
- Lazy
- PostgreSQL
- MaterializedPostgreSQL
- Replicated
- SQLite
2.表引擎
接下来是表引擎,这是ClickHouse真正闪耀的地方。我们有MergeTree系列,它们就像是强大的工具箱,为你的数据提供高效的存储、查询和维护能力。MergeTree特别擅长处理巨量数据,而且它还能够让数据自动分区和复制,这对于分析任务来说是非常有用的。
与此相反,MySQL里的InnoDB和MyISAM则更像是多面手。InnoDB支持事务,这就像是让你的数据操作更加严谨和安全,确保你的每一步操作都可以按照期望进行。MyISAM则速度飞快,但它不支持事务,就像是一个没有安全带的赛车手。
如果我们要做一个快速比较:
-
事务处理:ClickHouse的
MergeTree不处理事务,而MySQL的InnoDB则是事务处理的佼佼者。 -
锁定和并发:
MergeTree不需要行锁,因为它主要用于读取大量数据。而InnoDB提供了行级锁定,这对于需要同时写入和读取的应用来说非常关键。 -
数据格式:ClickHouse存储的是列数据,当你需要分析大量数据时,这种方式能更快地读取相关列。MySQL存储的是行数据,这使得它在处理交易和CRUD操作时更为高效。
-
数据复制和分布式处理:ClickHouse天生就支持分布式处理,
MergeTree让复制和分布式查询变得简单。MySQL则需要额外配置来实现这些功能。接下来我们将提供一些表引擎创建实例,如下所示。
MergeTree引擎:
-
MergeTree是ClickHouse最常用的表引擎,它支持高效的数据插入和查询操作。
-
创建一个MergeTree表的示例:
CREATE TABLE mytable ( Date Date, Key Int, Value Float32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(Date) ORDER BY Key;
Log引擎:
-
Log引擎适用于存储少量数据。
-
创建一个Log表的示例:
CREATE TABLE mytable ( Key Int, Value String ) ENGINE = Log;
Memory引擎:
-
Memory引擎将所有数据存储在内存中。
-
创建一个Memory表的示例:
CREATE TABLE mytable ( Key Int, Value String ) ENGINE = Memory;
Distributed引擎:
-
Distributed引擎用于在多个节点上分布式存储和查询数据。
-
创建一个Distributed表的示例:
CREATE TABLE mytable ( Date Date, Key Int, Value Float32 ) ENGINE = Distributed(cluster, database, table, sharding_key);
与ClickHouse相比,MySQL的存储引擎主要影响表的存储和行为。例如:
InnoDB引擎:
-
MySQL的默认事务型引擎,支持ACID事务、行级锁定和外键。
-
创建一个InnoDB表的示例:
CREATE TABLE mytable ( id INT PRIMARY KEY, value VARCHAR(100) ) ENGINE=InnoDB;
MyISAM引擎:
-
MyISAM是MySQL的一个非事务型引擎,它曾经是MySQL的默认引擎,提供了高速存取。
-
创建一个MyISAM表的示例:
CREATE TABLE mytable ( id INT PRIMARY KEY, value VARCHAR(100) ) ENGINE=MyISAM;
所以,根据你的需求,如果你是在处理大量的数据分析任务,ClickHouse的MergeTree可能是你的最佳选择。但如果你的工作更侧重于事务处理和行级操作,MySQL的InnoDB可能更适合你。
记住,选择合适的工具很重要,这和选择合适的车子一样。你不会开赛车去买菜,也不会开卡车参加F1赛车。了解你的数据和你的需求,然后选择最适合你的引擎。
2.4 高吞吐写入特性
ClickHouse 使用类似LSM Tree的机制进行数据存储,数据写入时为追加操作,并在后台通过合并排序进行压缩整理。
ClickHouse的写入性能是如何利用类LSM(Log-Structured Merge-tree)树结构来实现高效写入的呢。
首先,想象一下你有一本书,你要写入新的内容。在传统的数据库中,你可能需要找到书中的空白部分或者覆盖旧内容。这就像是随机写入,需要在书的不同部分跳来跳去。但是,如果你有一个空白的笔记本,你只需要从第一页写到最后一页,这就是顺序写入,这种方式非常高效。
ClickHouse的写入方式就像是在这个空白的笔记本上写入数据。当你导入数据时,ClickHouse不是随机地写入硬盘的不同部分,而是将数据顺序追加到硬盘的末尾。这就像是在笔记本的最后一页继续写入,直到填满了所有页。现在,为什么这么做效率这么高呢?
这是因为硬盘(无论是旧式的HDD还是现代的SSD)在顺序写入时速度最快。随机写入需要硬盘的读写头在盘面上移动到特定的位置,这会浪费时间。但是顺序写入就像是读写头在一个固定的轨迹上持续移动,这大大减少了寻找时间,提高了吞吐量。
现在,写入数据后,这些数据就变成了不可变的,就像是你写完笔记本的一页,你就不能再改变它了。在ClickHouse中,这些不可变的数据块会定期进行一种称为“Compaction”的过程。在这个过程中,多个旧的数据块会被合并和排序,形成新的、更大、更有序的数据块。这就像是你在笔记本的多页内容之间做索引和整理,使得它们更容易查询。
通过这种方式,ClickHouse可以保持高速的写入性能,并且由于数据是顺序写入的,即使是在较慢的硬盘上,也能保持良好的性能。这种写入方式不仅速度快,而且由于数据是按照顺序存储的,所以在你需要读取数据时,也能够快速访问,这对于执行大规模分析查询是非常重要的。
所以,当我们谈论ClickHouse的高吞吐和写入能力时,我们是在讨论它如何巧妙地利用硬件特性,以及它的设计如何符合高效数据处理的需求。这就是为什么即使在传统硬盘上,ClickHouse也能提供如此出色的性能。
在ClickHouse的官网https://clickhouse.com/docs/zh/introduction/performance对于ClickHouse性能有这样一段描述,翻译成中文内容如下:
建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。
2.5 数据分区与线程级并行特性
ClickHouse通过将数据划分为多个分区和索引粒度,利用多CPU核心进行并行处理,从而极大降低查询延时并优化大数据查询性能。然而,这种设计对于高并发查询业务不太适用,因为单条查询可能占用多个CPU,导致并发查询的处理能力降低。
让我们深入理解ClickHouse是如何实现其卓越的查询性能的,尤其是当它处理大规模数据集时。
首先,我们来谈谈ClickHouse的数据分区。想象一下,你有一个巨大的书架,而不是把所有的书随意摆放,你按照类别把它们分成不同的部分,或者在这里,我们称之为“分区”(partitions)。每个分区包含相关的数据集,这样你就能更快地找到你需要的信息。在ClickHouse中,这些分区帮助我们管理和查询数据,因为每次查询只需要查看包含相关数据的分区,而不是整个数据库。
接着,每个分区都被进一步细分为所谓的“索引粒度”(index granularity)。这就好比你不仅按类别分区书籍,还给每个类别的书做了详细的索引,让你能快速翻到特定的章节。在ClickHouse中,索引粒度使得我们能够高效地定位到数据的具体位置,这样查询操作就只需处理包含所需数据的小部分数据块,而不是整个数据集。
现在,让我们来讨论并行处理。假设你有一个团队来帮你管理这个巨大的书架。如果你需要找特定的信息,整个团队可以分头行动,每个人查找书架的一部分。ClickHouse正是这样工作的,它利用服务器上的所有CPU核心来并行处理数据。这就像是让你的整个团队同时行动,每个人都在快速地处理他们的任务。结果?即使面对庞大的数据集,ClickHouse也能够迅速返回查询结果,因为它把一个大任务分解成许多小任务,然后同时执行。
但是,正如任何系统都有其优势和局限性一样,ClickHouse在并行处理单条查询时表现得非常出色,因为它可以使用整台机器的所有CPU资源。然而,这种方法的代价是,如果你试图同时执行多条查询,每条查询都会竞争相同的CPU资源。因此,如果你的业务需要高查询每秒(QPS)——即同时运行大量的查询——ClickHouse可能不是最佳选择,因为在这种情况下,资源可能会迅速饱和,导致性能下降。
总之,ClickHouse通过将数据划分为分区和索引粒度,加上其能够在所有CPU核心上并行处理查询的能力,成为了处理大量数据和复杂查询的强大工具。但是,对于那些需要高并发查询的场景,你可能需要考虑不同的策略或技术来补充ClickHouse的这一点限制。
接下来,我将提供一些示例,对上述特性进行举例说明:
1.分区与索引粒度示例
假设我们管理着一个电子商务平台的数据库,我们有一个包含订单数据的巨大表。为了优化查询性能,我们可以按月对订单进行分区。
创建分区表的示例:
CREATE TABLE orders (
order_id UInt64,
order_date Date,
customer_id UInt64,
total_amount Decimal(10, 2)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(order_date)
ORDER BY (customer_id, order_date);
在这个表中,我们使用toYYYYMM(order_date)函数来定义分区键,这样所有同一个月份的订单都会存储在同一个分区中。这意味着如果我们想要查询一个特定月份的订单,ClickHouse只会查看那个月份对应的分区,而不是整个表,大大提高了查询效率。
2.并行处理示例
现在,如果我们要对过去一年的订单总金额进行统计分析,ClickHouse会将这个任务分散到多个CPU核心上执行。如果我们的服务器有16个核心,ClickHouse会尝试利用所有这些核心来并行处理查询。
并行查询的示例:
SELECT
toMonth(order_date) AS month,
sum(total_amount) AS total
FROM orders
WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY month
ORDER BY month;
在这个查询中,ClickHouse会在不同的CPU核心上并行处理不同的分区,每个核心处理一部分数据,然后将结果合并,这样即使是大量数据,查询响应时间也非常快。
3.高并发场景示例
对于高并发查询的场景,假设你的平台在特定促销期间,同时有很多用户想要查看他们的订单历史。如果有数百个这样的查询同时发起,每个查询都会尝试使用所有可用的CPU核心,这会导致资源争抢。
在这种情况下,我们可能需要使用ClickHouse的其他功能,如利用其max_threads设置来限制单个查询可以使用的最大线程数,或者优化我们的查询逻辑,尽量减少同时执行的复杂查询数量。
调整并发设置的示例:
SET max_threads = 4; -- 限制查询只能使用4个线程
这个设置可以帮助我们平衡单个查询的资源使用和整体的并发能力,但这也可能会增加单个查询的响应时间。
以上示例展示了ClickHouse如何在单查询性能和并发处理之间取得平衡,以及我们如何根据具体应用场景调整配置以最大化性能。
三、ClickHouse场景限制
3.1 ClickHouse适用场景
大数据分析:
- ClickHouse是为处理大规模数据集设计的,特别适合进行快速的数据分析和报告。如果你的业务涉及到大量的数据挖掘和复杂的分析查询,ClickHouse将是一个优秀的选择。
实时数据处理:
- 由于其高效的数据插入和查询能力,ClickHouse非常适合需要实时或接近实时数据处理的应用,比如监控、日志分析和在线分析处理(OLAP)。
历史数据的长期存储和查询:
- ClickHouse的高压缩率和列式存储机制使其成为长期存储和查询历史数据的理想选择,尤其是当存储空间成本是一个考虑因素时。
分布式系统:
- 对于需要横向扩展的系统,ClickHouse的分布式处理能力可以帮助你轻松扩展到多个节点,同时保持查询的高效率。
3.2 ClickHouse不适用场景
在线事务处理(OLTP):
- 如果你的应用主要是事务性的,需要频繁的数据更新、删除和行级锁定(例如电子商务网站的订单处理),那么传统的关系型数据库(如MySQL、PostgreSQL)可能更适合你的需求。
高并发短查询:
- 虽然ClickHouse在处理单个复杂查询时表现出色,但对于需要同时处理大量简单查询的场景(高QPS),它可能不是最佳选择。这是因为每个查询都会尽量使用所有可用的CPU资源,这可能导致资源争抢和性能瓶颈。
小数据集应用:
- 对于只处理小量数据的应用,ClickHouse的强大功能可能是过剩的。在这种情况下,轻量级数据库或传统的SQL数据库可能更合适,因为它们在配置和资源使用上可能更为简单和高效。
强一致性要求:
- 如果你的应用需要严格的事务支持和强一致性保证,ClickHouse可能不符合这些要求。它主要优化了读取性能和数据分析,而不是事务处理。
选择正确的工具来满足你的特定需求是至关重要的。ClickHouse在数据分析和处理大规模数据集方面表现卓越,但对于其他类型的工作负载,考虑其特性和限制是非常重要的。无法做到药治百病,所以要针对不同的场景选择不同的数据库。
