




问题引入
分类问题是一个机器学习中最基本的问题,但是我们在实际的项目或者比赛中可能会遇到一些情况,就是某些样本对应的标签特别多,某些样本的标签特别少。而且整体上标签的分布是呈现出一个长尾分布的状态,但这个时候如何对于这个模型进行建模呢?
问题解答
对于上面的问题我们可以理解成一个长尾问题,如按照 class frequency 排序, 可以将 frequency 较高的 class/label 称之为 head label, frequency 较低的 class/label 称之为tail label. 下图是一个例子:
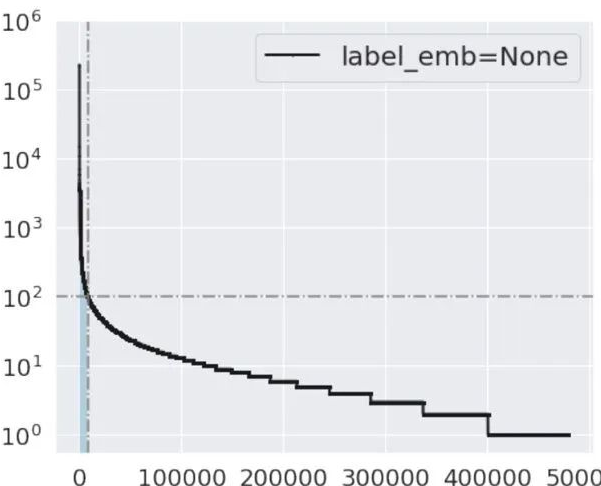
1.最常用的技巧,up-sampling 或 down-sampling, 其实在 long tail 的 data 做这两种 sampling 都不是特别好的办法. 由于 tail label 数据非常 scarce, 如果对 head label 做 down-sampling 会丢失绝大部分信息. 同理, 对 tail label 做 up-sampling, 则引入大量冗余数据. 这里有篇文章对比了这两种采样方法。 可以参考文献1
2.divide-and-conquer, 即将 head label 和 tail label 分别建模. 比如先利用 data-rich 的 head label 训练 deep model, 然后将学到的样本的 representation 迁移到 tail label model, 利用少量 tail label data 做 fine-tune. 具体做法可以参考文献2
3.对 label 加权, 每个 label 赋予不同的 cost. 如给予 head label 较低的 weight, 而 tail label 则给予较高的 weight, 但是这个权重是怎么设置的呢?其实也不太好定呀。有关可以参考文献3
参考
[1] learning-to-model-the-tail
[2] deepxml: scalable & accurate deep extreme classification for matching user ueries to advertiser bid phrases
[3] extreme multi-label learning with label features for warm-start tagging, ranking & recommendation
喜欢就关注一下啦~~~

