




数据库管理155期 2024-02-26
数据库管理-第155期 记一次发生在备库上的故障处理(20240226)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Associate: Database(Oracle与MySQL)
国内某科技公司 DBA总监
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、认证技术专家、年度墨力之星,ITPUB认证专家,OCM讲师
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭。
最近一直在写Oracle Vector DB和AI Vector Search相关的内容,预计还有好几篇。其实今天也在纠结是继续写这个系列还是换点其他东西,由于早上心情不大好,换个心情写点其他的东西。
1 故障概览
这是一套用于Exadata一体机的4节点X86灾备RAC集群,也就是之前做19c RAC部署演示的那套集群。GI和DB都是19.16。最近发生过几次凌晨某个实例异常重启的现象。主要告警如下(通过EMCC告警,截取message部分):
message:Internal error (ORA 600 [ktuGetTemprsp:no tso]) detected in /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/alert/log.xml message:Operational error (PMON (ospid: 15...) detected in /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/alert/log.xml
一直没排查出个端倪,随即开了个SR排查。
2 Bug 34988484
经过SR检查通过AHF收集的相关信息后,给出了以下的日志分析:
2024-02-22T00:34:31.005788+08:00 Errors in file /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/trace/xxdbdg1_ora_43974.trc (incident=1888472) (PDBNAME=PDB_XXXXX): ORA-00600: internal error code, arguments: [ktuGetTemprsp:no tso], [1461], [], [], [], [], [], [], [], [], [], [] PDB_XXXXX(18):Incident details in: /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/incident/incdir_1888472/xxdbdg1_ora_43974_i1888472.trc ...... 2024-02-22T00:36:38.637866+08:00 Errors in file /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/trace/xxdbdg1_cl03_1196.trc (incident=1886296) (PDBNAME=PDB_XXXXX): ORA-00600: internal error code, arguments: [ktuGetTemprsp:no tso], [6113], [], [], [], [], [], [], [], [], [], [] PDB_XXXXX(18):Incident details in: /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/incident/incdir_1886296/xxdbdg1_cl03_1196_i1886296.trc 2024-02-22T00:36:39.824052+08:00 Cause - 'Instance is being terminated due to fatal process death (pid: 223, ospid: 1196, CL03)'2024-02-22T00:34:31.005788+08:00 Errors in file /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/trace/xxdbdg1_ora_43974.trc (incident=1888472) (PDBNAME=PDB_XXXXX): ORA-00600: internal error code, arguments: [ktuGetTemprsp:no tso], [1461], [], [], [], [], [], [], [], [], [], [] PDB_XXXXX(18):Incident details in: /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/incident/incdir_1888472/xxdbdg1_ora_43974_i1888472.trc ...... 2024-02-22T00:36:38.637866+08:00 Errors in file /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/trace/xxdbdg1_cl03_1196.trc (incident=1886296) (PDBNAME=PDB_XXXXX): ORA-00600: internal error code, arguments: [ktuGetTemprsp:no tso], [6113], [], [], [], [], [], [], [], [], [], [] PDB_XXXXX(18):Incident details in: /u01/app/oracle/diag/rdbms/xxdbdg/xxdbdg1/incident/incdir_1886296/xxdbdg1_cl03_1196_i1886296.trc 2024-02-22T00:36:39.824052+08:00 Cause - 'Instance is being terminated due to fatal process death (pid: 223, ospid: 1196, CL03)'
即是进程发生ORA-00600 [ktuGetTemprsp:no tso],并且随后PMON slave (CLnn)进程在清理资源时crash实例。
这里匹配到了对应的Bug 34988484 - [TXN MGMT LOCAL] ORA-600 [ktugettemprsp:no tso] even with patch 34615905 applied ( Doc ID 34988484.8 )。对应修复如下图:
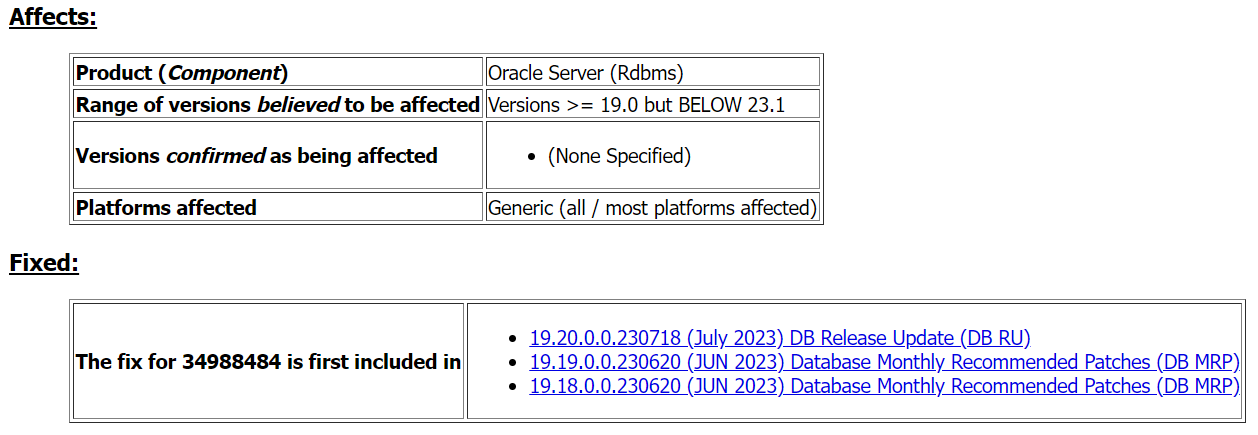
由于最近没有打补丁的停机窗口,且主库在同样版本运行了1年有余,因此先尝试整体重启了整个集群:
oracle: srvctl stop database -db xxdbdg root: /u01/app/19.0.0/grid/bin/crsctl stop cluster -all ...... /u01/app/19.0.0/grid/bin/crsctl start cluster -all oracle: srvctl start database -db xxdbdg
就目前情况而言从上次故障到现在并未再出现异常,如果大家也遇到类似问题可以尝试一下重启集群这个方法。
3 Service on Standby
就目前版本而言,在备库的PDB是无法通过以下命令随CDB启动而自动启动的:
alter pluggable database pdb_xxx open [instances=xxxxx];
alter pluggable database pdb_xxx save state [instances=xxxxx];
这次备库故障由于连着两天挂了两个实例,导致一个PDB的服务没有启动,引起某些使用physical standby读写分离能力的业务出了点小问题。因为之前添加备库service的时候是使用下面的命令:
srvctl add service -db xxdbdg -pdb PDB_XXXXX -s XXXDB -preferred xxdbdg1,xxdbdg2 srvctl start service -db xxdbdg -s XXXDB
这种配置方式备库的service也不会随实例启动而启动,需要在service配置过程中加上-role physical_standby,操作方式如下:
#新建服务
srvctl add service -db xxdbdg -pdb PDB_XXXXX -s XXXDB -preferred xxdbdg1,xxdbdg2 -role physical_standby
srvctl start service -db xxdbdg -s XXXDB
#修改服务
srvctl modify service -db xxdbdg -s XXXDB -role physical_standby
4 AHF的小问题
在处理上面的问题的时候,需要使用AHF中的tfactl来处理相关问题,结果出现了下面的问题:
tfactl diagcollect -srdc dbrac Error: suptools/srdc directory does not exist for oracle
以前是没有出现过相关问题的,最近更新了版本至最新的24.1.0.0.0:

看报错信息应该是目录问题,而suptools是repository的下级目录(根据经验),因此排查解决流程如下:
find / -name repository /usr/lib64/python2.7/site-packages/gi/repository /u01/app/grid/oracle.ahf/data/repository /u01/app/grid/tfa/repository ls -l /u01/app/grid/oracle.ahf/data/repository/suptools/srdc total 20 drwxr----t 2 grid root 6 May 16 2023 user_grid drwxr----t 2 oracle root 6 May 16 2023 user_oracle drwxr----t 2 root root 16384 Feb 26 09:36 user_root ls -l /u01/app/grid/tfa/repository/suptools/srdc total 0 drwxr----t 2 root root 6 Feb 22 10:19 user_root
这里发现/u01/app/grid/tfa/repository/suptools/srdc目录下没有user_oracle、user_grid目录,因此手工创建:
mkdir /u01/app/grid/tfa/repository/suptools/srdc/user_oracle chown oracle /u01/app/grid/tfa/repository/suptools/srdc/user_oracle -R mkdir /u01/app/grid/tfa/repository/suptools/srdc/user_grid chown grid /u01/app/grid/tfa/repository/suptools/srdc/user_grid -R
再次执行tfa diagcollection命令并没有再报错。
对比主库,AHF版本23.11.0.0.0,压根就没有/u01/app/grid/tfa这个目录,因此这里不知道是升级过程中出现的问题还是普通X86集群和Exadata上有啥区别。
总结
本期针对在备库上实例异常重启对应的BUG、备库PDB与service的问题和AHF异常进行了梳理、总结。
老规矩,知道写了些啥。
