




刚接触Doris的同学,经常会有以下的疑问:
• 数据磁盘快用满了,怎么办
• 数据误删了数据如何恢复
• 副本损坏了该怎么修复
• be节点新增存储目录或者新增be节点,存量的tablet数据会移动过去吗?
笔者针对以上问题,梳理了Doris磁盘空间管理、数据副本管理的一些知识点。既是笔者的阶段性总结,也希望能给屏幕前的读者带来一些帮助。
磁盘空间管理
Doris 的数据磁盘空间如果不加以控制,会因磁盘写满而导致进程挂掉。因此Doris 监测磁盘的使用率和剩余空间,通过设置不同的警戒水位,来控制 Doris 系统中的各项操作,尽量避免发生磁盘被写满的情况。该章节将主要介绍:
1. 如何避免磁盘空间满
2. 如果空间满了,怎么清理数据
3. 如果误删数据怎么办
基本原理
BE 定期(每隔一分钟)会向 FE 汇报一次磁盘使用情况。FE 记录这些统计值,并根据这些统计值,限制不同的操作请求。
在 FE 中分别设置了 高水位(High Watermark) 和 危险水位(Flood Stage) 两级阈值。危险水位高于高水位。当磁盘使用率高于高水位时,Doris 会限制某些操作的执行(如副本均衡等)。而如果高于危险水位,则会禁止某些操作的执行(如导入)。
FE 参数
高水位:
storage_high_watermark_usage_percent 默认 85 (85%)
storage_min_left_capacity_bytes 默认 2GB
当磁盘空间使用率大于 storage_high_watermark_usage_percent
,或者 磁盘空间剩余大小小于 storage_min_left_capacity_bytes
时,该磁盘不会再被作为以下操作的目的路径:
• Tablet 均衡操作(Balance)
• Colocation 表数据分片的重分布(Relocation)
• Decommission
危险水位:
storage_flood_stage_usage_percent 默认 95 (95%)
storage_flood_stage_left_capacity_bytes 默认 1GB
当磁盘空间使用率大于 storage_flood_stage_usage_percent
,并且 磁盘空间剩余大小小于 storage_flood_stage_left_capacity_bytes
时,该磁盘不会再被作为以下操作的目的路径,并禁止某些操作:
• Tablet 均衡操作(Balance)
• Colocation 表数据分片的重分布(Relocation)
• 副本补齐
• 恢复操作(Restore)
• 数据导入(Load/Insert)
BE 参数
危险水位:
storage_flood_stage_usage_percent 默认 90 (90%)
storage_flood_stage_left_capacity_bytes 默认 1GB
当磁盘空间使用率大于 storage_flood_stage_usage_percent
,并且 磁盘空间剩余大小小于 storage_flood_stage_left_capacity_bytes
时,该磁盘上的以下操作会被禁止:
• Base/Cumulative Compaction。
• 数据写入。包括各种导入操作。
• Clone Task。通常发生于副本修复或均衡时。
• Push Task。发生在 Hadoop 导入的 Loading 阶段,下载文件。
• Alter Task。Schema Change 或 Rollup 任务。
• Download Task。恢复操作的 Downloading 阶段。
磁盘空间释放
当磁盘空间高于高水位甚至危险水位后,很多操作都会被禁止。此时可以尝试通过以下方式减少磁盘使用率,恢复系统。
• 删除表或分区:通过删除表或分区的方式,能够快速降低磁盘空间使用率,恢复集群。注意:只有
DROP
操作可以达到快速降低磁盘空间使用率的目的,DELETE
操作不可以。DROP TABLE tbl;
ALTER TABLE tbl DROP PARTITION p1;• Be扩容:扩容后,数据分片会自动均衡到磁盘使用率较低的 BE 节点上。扩容操作会根据数据量及节点数量不同,在数小时或数天后使集群到达均衡状态。
• 修改表或分区的副本:可以将表或分区的副本数降低。比如默认3副本可以降低为2副本。该方法虽然降低了数据的可靠性,但是能够快速的降低磁盘使用率,使集群恢复正常。该方法通常用于紧急恢复系统。请在恢复后,通过扩容或删除数据等方式,降低磁盘使用率后,将副本数恢复为 3。修改副本操作为瞬间生效,后台会自动异步的删除多余的副本。
ALTER TABLE tbl MODIFY PARTITION p1 SET("replication_num" = "2");• 删除多余文件:当 BE 进程已经因为磁盘写满而挂掉并无法启动时(此现象可能因 FE 或 BE 检测不及时而发生)。需要通过删除数据目录下的一些临时文件,保证 BE 进程能够启动。以下目录中的文件可以直接删除:这种操作会对 从 BE 回收站中恢复数据 产生影响。
• log/:日志目录下的日志文件。
• snapshot/: 快照目录下的快照文件。
• trash/:回收站中的文件。
• 删除数据文件(危险!!!):当以上操作都无法释放空间时,需要通过删除数据文件来释放空间。数据文件在指定数据目录的
data/
目录下。删除数据分片(Tablet)必须先确保该 Tablet 至少有一个副本是正常的,否则删除唯一副本会导致数据丢失。假设我们要删除 id 为 12345 的 Tablet:• 找到 Tablet 对应的目录,通常位于
data/shard_id/tablet_id/
下。如:data/0/12345/• 记录 tablet id 和 schema hash。其中 schema hash 为上一步目录的下一级目录名。如下为 352781111:
data/0/12345/352781111• 删除数据目录:
rm -rf data/0/12345/• 删除 Tablet 元数据:
./lib/meta_tool --operation=delete_header --root_path=/path/to/root_path --tablet_id=12345 --schema_hash= 352781111
数据删除恢复
数据删除恢复包含两种情况:
1. 用户执行命令
drop database/table/partition
之后,再使用命令recover
来恢复整个数据库/表/分区的所有数据。这种修复将会把FE上的数据库/表/分区的结构,从catalog回收站里恢复过来,把它们从不可见状态,重新变回可见,并且原来的数据也恢复可见;2. 用户因为某些误操作或者线上bug,导致BE上部分tablet被删除,通过运维工具把这些tablet从BE回收站中抢救回来。
上面两个,前者针对的是数据库/表/分区在FE上已经不可见,且数据库/表/分区的元数据尚保留在FE的catalog回收站里。而后者针对的是数据库/表/分区在FE上可见,但部分BE tablet数据被删除。
下面分别阐述这两种恢复。
FE参数
• catalog_trash_expire_second:FE的catalog在回收站中默认保留一天
BE参数
• max_garbage_sweep_interval:如果磁盘占用已达到 危险水位(Flood Stage) 的90%,则会清理 所有 trash文件和过期snapshot文件。该参数为最大的自动执行的时间间隔
• min_garbage_sweep_interval:如果磁盘占用已达到 危险水位(Flood Stage) 的90%,则会清理 所有 trash文件和过期snapshot文件。该参数为最小的自动执行的时间间隔
• trash_file_expire_time_sec:默认情况下,BE回收站中的数据最长保留3天(见BE配置
config.trash_file_expire_time_sec
)。
Drop 恢复
Doris为了避免误操作造成的灾难,支持对误删除的数据库/表/分区进行数据恢复,在drop table或者 drop database 或者 drop partition之后,Doris不会立刻对数据进行物理删除,而是在FE的catalog回收站中保留一段时间(默认1天,可通过fe.conf中catalog_trash_expire_second
参数配置),管理员可以通过RECOVER命令对误删除的数据进行恢复。
注意,如果是使用drop force
进行删除的,则是直接删除,无法再恢复。
恢复数据
执行RECOVER
命令之后,原来的数据将恢复可见。
# 恢复名为 example_db 的 database
RECOVER DATABASE example_db;
# 恢复名为 example_tbl 的 table
RECOVER TABLE example_db.example_tbl;
# 恢复表 example_tbl 中名为 p1 的 partition
RECOVER PARTITION p1 FROM example_tbl;
# 以name和id恢复 table
RECOVER TABLE [db_name.]table_name table_id;
• 该操作仅能恢复之前一段时间内删除的元信息。默认为 1 天。(可通过fe.conf中
catalog_trash_expire_second
参数配置)• 如果恢复元信息时没有指定id,则默认恢复最后一个删除的同名元数据。
• 可以通过
SHOW CATALOG RECYCLE BIN
来查询当前可恢复的元信息。
BE tablet 数据恢复
从 BE 回收站中恢复数据
用户在使用Doris的过程中,可能会发生因为一些误操作或者线上bug,导致一些有效的tablet被删除(包括元数据和数据)。
为了防止在这些异常情况出现数据丢失,Doris提供了回收站机制,来保护用户数据。
用户删除的tablet数据在BE端不会被直接删除,会被放在回收站中存储一段时间,在一段时间之后会有定时清理机制将过期的数据删除。默认情况下,在磁盘空间占用不超过危险水位(Flood Stage) 的90%时,BE回收站中的数据最长保留3天(见BE配置config.trash_file_expire_time_sec
)。
BE回收站中的数据包括:tablet的data文件(.dat),tablet的索引文件(.idx)和tablet的元数据文件(.hdr)。数据将会存放在如下格式的路径:
/root_path/trash/time_label/tablet_id/schema_hash/
•
root_path
:对应BE节点的某个数据根目录。•
trash
:回收站的目录。•
time_label
:时间标签,为了回收站中数据目录的唯一性,同时记录数据时间,使用时间标签作为子目录。
当用户发现线上的数据被误删除,需要从回收站中恢复被删除的tablet,需要用到这个tablet数据恢复功能。
BE提供http接口和 restore_tablet_tool.sh
脚本实现这个功能,支持单tablet操作(single mode)和批量操作模式(batch mode)。具体操作可参考:数据恢复与删除
修复缺失或损坏的 Tablet
在某些极特殊情况下,如代码BUG、或人为误操作等,可能导致部分分片的全部副本都丢失。这种情况下,数据已经实质性的丢失。但是在某些场景下,业务依然希望能够在即使有数据丢失的情况下,保证查询正常不报错,降低用户层的感知程度。此时,Doris可以通过使用空白Tablet填充丢失副本的功能,来保证查询能够正常执行。
当确认数据已经无法恢复后,可以通过使用空白副本填补缺失副本,即通过生成空白副本来进行"恢复"。具体操作可参考:数据恢复与删除
注:该操作仅用于规避查询因无法找到可查询副本导致报错的问题,无法恢复已经实质性丢失的数据
数据副本管理
Doris集群内部有一套完善的副本管理策略。该章节将主要介绍Doris 数据副本均衡、修复方面的调度策略。
FE参数
• balance_slot_num_per_path:balance 时每个路径的默认 slot 数量,默认为1,可以动态调整;
• schedule_slot_num_per_hdd_path:对于HDD盘,默认分配给每块磁盘用于副本修复的 slot 数目。该数目表示一块磁盘能同时运行的副本修复任务数。如果想以更快的速度修复副本,可以适当调高这个参数。单数值越高,可能对 IO 影响越大。
• schedule_slot_num_per_ssd_path:对于SSD盘,默认分配给每块磁盘用于副本修复的 slot 数目。该数目表示一块磁盘能同时运行的副本修复任务数。如果想以更快的速度修复副本,可以适当调高这个参数。单数值越高,可能对 IO 影响越大。
名词解释
1. Replica:分片的副本,默认一个分片有3个副本。
2. Healthy Replica:健康副本,副本所在 Backend 存活,且副本的版本完整。
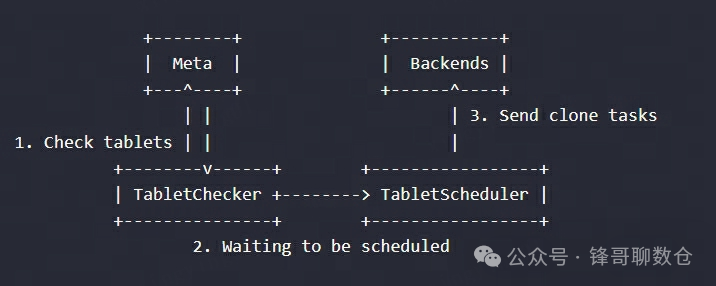
3. TabletChecker(TC):TabletChecker 作为常驻的后台进程,会定期检查所有分片的状态。对于非健康状态的分片,将会交给 TabletScheduler 进行调度和修复。修复的实际操作,都由 BE 上的 clone 任务完成。FE 只负责生成这些 clone 任务。
• 默认每 20 秒进行一次全量检查。(Config.tablet_checker_interval_ms)
• 最大等待调度任务数和运行中任务数为 2000(Config.max_scheduling_tablets)。当超过 2000 个tablet,则跳过检查。
• 最大均衡任务数为 100(Config.max_balancing_tablets)。当超过 100后,将不再产生新的均衡任务
• 每块磁盘用于均衡任务的 slot 数目为2。这个 slot 独立于用于副本修复的 slot
• 一个 clone 任务超时时间范围是 3min ~ 2hour(min_clone_task_timeout_sec~max_clone_task_timeout_sec)。具体超时时间通过 tablet 的大小计算。计算公式为 (tablet size) (5MB/s)。当一个 clone 任务运行失败 5(Config.tablet_further_repair_max_times))次后,该任务将终止。
4. TabletScheduler(TS):是一个常驻的后台线程,用于处理由 TabletChecker 发来的需要修复的 Tablet。同时也会进行集群副本均衡的工作。
• TabletScheduler 每1秒进行一次调度(Config.tablet_schedule_interval_ms)
• TabletScheduler 每次调度最多 50 个 tablet(Config.schedule_batch_size)
5. TabletSchedCtx(TSC):是一个 tablet 的封装。当 TC 选择一个 tablet 后,会将其封装为一个 TSC,发送给 TS。
6. Storage Medium:存储介质。Doris 支持对分区粒度指定不同的存储介质,包括 SSD 和 HDD。副本调度策略也是针对不同的存储介质分别调度的。
下图是一个简化的工作流程:
副本修复
在Doris运行中可能由于操作不当或者软件Bug导致副本不一致,为此Doris设计了副本修复机制。
TabletChecker 作为常驻的后台进程,会定期检查所有分片的状态。对于非健康状态的分片,将会交给 TabletScheduler 进行调度和修复。修复的实际操作,都由 BE 上的 clone 任务完成。FE 只负责生成这些 clone 任务。
下面这张图是 Doris 副本检查及副本恢复的整体流程图:
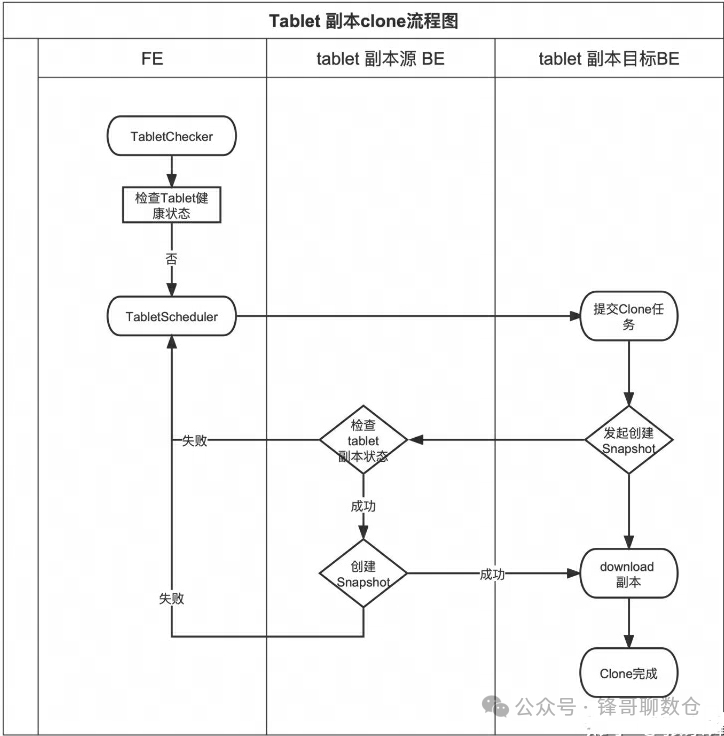
FE 的 tablet 检查进程(TabletChecker),会定期的对所有分片进行检查,然后会将不健康的分片,交给Tablet调度进程去完成调度和修复。下面我们主要介绍一下 FE 怎么生成调度任务及BE怎么完成Clone 和修复。首先Doris要找到一个目标BE,可以用来Clone 一个新的副本
1. 找到一个可用的 BE 及副本存放路径,作为副本Clone的目标节点
• 在副本丢失的情况下,Doris要选择一个有副本丢失的 tag
• 根据副本分布情况,如果没有副本丢失 tag 的,这种应该抛出异常
• 如果删除多余的副本,这时候需要找出一个多余副本的标签
• 首先这个 BE 是要 Alive 的
• 应该将现有副本的 BE 节点排除在外,因为同一个 BE 只能有一个副本。
• 选择一个 proper tag BE
• 这个目标 BE 要有可以使用执行 Clone 任务的 Slot
• 找到一个可以用来 Clone 副本的合适的路径,这里要考虑磁盘容量和使用百分比。目标是要找到一个负载(ClusterLoadStatistics(CLS))相对低的路径,这里TabletScheduler 会每隔 20s (tablet_checker_interval_ms)更新一次 CLS
2. 向目标 BE 发送克隆任务
• 目标 BE 提交 Clone task 任务
• 判断 tablet 副本是否存在,如果不存在则开始 Clone 一个新的 tablet
• 向源 BE 发送一个创建Snapshot的请求。这里源 BE 之所以要创建Snapshot,是因为在 clone 修复的时候,可能有数据写导致Clone 失败,通过创建快照来避免这个问题。
• 源 BE 检查 tablet 状态及版本等是否正常,如果源 BE 的tablet 副本状态、版本等都是正常的,执行创建Snapshot,并返回
• 目标 BE 从源 BE 下载刚才创建的Snapshot到本地,完成副本恢复
TabletChecker 逻辑如下:
runAfterCatalogReady
|--> handleRunningTablets
|--> selectTabletsForBalance
| |--> //如果关闭了tablet均衡及调度则放弃
| |--> if (Config.disable_balance || Config.disable_tablet_scheduler) return
| |--> //TabletScheduler 每次调度最多 50 个 tablet(Config.schedule_batch_size)
| |--> //最大均衡任务数为 100(Config.max_balancing_tablets)。当超过 100后,将不再产生新的均衡任务
| |--> //通过needAddBalanceNum来判断是否继续执行
| |--> needAddBalanceNum = Math.min(Config.schedule_batch_size - getPendingNum(), Config.max_balancing_tablets - getBalanceTabletsNumber());
| |--> addTablet
| | |--> 最大等待调度任务数和运行中任务数为 2000(Config.max_scheduling_tablets)。当超过 2000 个tablet,则跳过检查。
| | |--> if(pendingTablets.size() > Config.max_scheduling_tablets || runningTablets.size() > Config.max_scheduling_tablets) return AddResult.LIMIT_EXCEED;
|--> schedulePendingTablets
| |--> currentBatch=getNextTabletCtxBatch
| | |--> //TabletScheduler 每次调度最多 50 个 tablet(Config.schedule_batch_size)
| | |--> while (list.size() < Config.schedule_batch_size && slotNum > 0) list.add(tablet);
| |--> for (TabletSchedCtx tabletCtx : currentBatch)
| |--> scheduleTablet(tabletCtx, batchTask);
| | |--> handleTabletByTypeAndStatus
| | | |--> //如果副本异常则进行修复
| | | |--> if (tabletCtx.getType() == Type.REPAIR) handleReplica()
| | | |--> //否则进行副本均衡
| | | |--> else doBalance(tabletCtx, batchTask)
| | | | |--> //if DISK_BALANCE
| | | | |--> diskRebalancer.createBalanceTask(tabletCtx);
| | | | |--> //if BE_BALANCE
| | | | |--> rebalancer.createBalanceTask(tabletCtx);
| | | | | |--> //一个 clone 任务超时时间范围是
| | | | | |--> //3min ~ 2hour(min_clone_task_timeout_sec~max_clone_task_timeout_sec)
| | | | | |--> //if getBalanceType==BE_BALANCE
| | | | | |--> createCloneReplicaAndTask
| | | | | |--> //else
| | | | | |--> createStorageMediaMigrationTask
| |--> //end for loop
TabletScheduler逻辑如下:
public TabletScheduler(Env env, SystemInfoService infoService, TabletInvertedIndex invertedIndex,
TabletSchedulerStat stat, String rebalancerType) {
//每1秒进行一次调度(Config.tablet_schedule_interval_ms)
super("tablet scheduler", Config.tablet_schedule_interval_ms);
this.env = env;
this.infoService = infoService;
this.invertedIndex = invertedIndex;
this.colocateTableIndex = env.getColocateTableIndex();
this.stat = stat;
//根据配置选择对应的策略
if (rebalancerType.equalsIgnoreCase("partition")) {
this.rebalancer = new PartitionRebalancer(infoService, invertedIndex, backendsWorkingSlots);
} else {
this.rebalancer = new BeLoadRebalancer(infoService, invertedIndex, backendsWorkingSlots);
}
// if rebalancer can not get new task, then use diskRebalancer to get task
this.diskRebalancer = new DiskRebalancer(infoService, invertedIndex, backendsWorkingSlots);
}
注1:副本修复的主要思想是先通过创建或补齐使得分片的副本数达到期望值,然后再删除多余的副本。
注2:一个 clone 任务就是完成从一个指定远端 BE 拷贝指定数据到指定目的端 BE 的过程。
注3:Doris 在选择副本节点时,不会将同一个 Tablet 的副本部署在同一个 host 的不同 BE 上。保证了即使同一个 host 上的所有 BE 都挂掉,也不会造成全部副本丢失。
注4:所有和调度相关的信息都不会持久化,包括处于 CLONE 状态的副本。如果 MASTER FE 宕机或者切主,则当前的所有调度任务丢失。
副本均衡
理想情况下,Doris的数据是按照分片粒度均匀打散到各个Be节点的。但是如果表的副本数发生变化或者集群发生扩缩容,分片副本还能保持均衡状态吗?
答案是肯定的,并且不需要人工介入,Doris 会自动进行集群内的副本均衡。
目前支持两种均衡策略,负载/分区。
• 负载均衡适合需要兼顾节点磁盘使用率和节点副本数量的场景;
• 分区均衡会使每个分区的副本都均匀分布在各个节点,避免热点,适合对分区读写要求比较高的场景。但是,分区均衡不考虑磁盘使用率,使用分区均衡时需要注意磁盘的使用情况。
策略只能在fe启动前配置 tablet_rebalancer_type ,不支持运行时切换。
负载均衡
负载均衡的主要思想是,对某些分片,先在低负载的节点上创建一个副本,然后再删除这些分片在高负载节点上的副本。同时,因为不同存储介质的存在,在同一个集群内的不同 BE 节点上,可能存在一种或两种存储介质。Doris要求存储介质为 A 的分片在均衡后,尽量依然存储在存储介质 A 中。所以Doris根据存储介质,对集群的 BE 节点进行划分。然后针对不同的存储介质的 BE 节点集合,进行负载均衡调度。
同样,副本均衡会保证不会将同一个 Tablet 的副本部署在同一个 host 的 BE 上。
BE 节点负载
Doris用 ClusterLoadStatistics(CLS)表示一个 cluster 中各个 Backend 的负载均衡情况。TabletScheduler 根据这个统计值,来触发集群均衡。Doris当前通过 磁盘使用率 和 副本数量 两个指标,为每个BE计算一个 loadScore,作为 BE 的负载分数。分数越高,表示该 BE 的负载越重。
磁盘使用率和副本数量各有一个权重系数,分别为 capacityCoefficient 和 replicaNumCoefficient,其 和恒为1。其中 capacityCoefficient 会根据实际磁盘使用率动态调整。当一个 BE 的总体磁盘使用率在 50% 以下,则 capacityCoefficient 值为 0.5,如果磁盘使用率在 75%(可通过 FE 配置项 capacity_used_percent_high_water
配置)以上,则值为 1。如果使用率介于 50% ~ 75% 之间,则该权重系数平滑增加,公式为:
capacityCoefficient= 2 * 磁盘使用率 - 0.5
该权重系数保证当磁盘使用率过高时,该 Backend 的负载分数会更高,以保证尽快降低这个 BE 的负载。
TabletScheduler 会每隔 20s 更新一次 CLS。可以看到每个机器以及每个目录都有一个标签Class:


其中一些列的含义如下:
• Available:为 true 表示 BE 心跳正常,且没有处于下线中
• UsedCapacity:字节,BE 上已使用的磁盘空间大小
• Capacity:字节,BE 上总的磁盘空间大小
• UsedPercent:百分比,BE 上的磁盘空间使用率
• ReplicaNum:BE 上副本数量
• CapCoeff/ReplCoeff:磁盘空间和副本数的权重系数
• Score:负载分数。分数越高,负载越重
• Class:根据负载情况分类,LOW/MID/HIGH。均衡调度会将高负载节点上的副本迁往低负载节点
根据标签定位到以下源码:
public enum Classification {
INIT,
LOW, // load score is Config.balance_load_score_threshold lower than average load score of cluster
MID, // between LOW and HIGH
HIGH // load score is Config.balance_load_score_threshold higher than average load score of cluster
}
从注释中可以看到有一个参数 balance_load_score_threshold 可以界定该节点是负载还是低负载,这个值系统默认是 0.1。
负载分数计算的源码如下:
loadScore.score = capacityProportion * loadScore.capacityCoefficient
+ replicaNumProportion * loadScore.getReplicaNumCoefficient();
负载因素系数和磁盘使用率系数一般都是 0.5,所以决定 load score 的是 磁盘使用率 和 副本数量 。
标签的计算方法如下:
这里有个限制,HIGH至少比LOW基本的磁盘使用率大5%,防止磁盘使用率很低的情况下的副本均衡太敏感。
// ensure: HIGH - LOW >= 2.5% * 2 = 5%
if (Math.abs(pathStat.getUsedPercent() - avgUsedPercent)
> Math.max(avgUsedPercent * Config.balance_load_score_threshold, 0.025)) {
if (pathStat.getUsedPercent() > avgUsedPercent) {
pathStat.setClazz(Classification.HIGH);
highCounter++;
} else if (pathStat.getUsedPercent() < avgUsedPercent) {
pathStat.setClazz(Classification.LOW);
lowCounter++;
}
} else {
pathStat.setClazz(Classification.MID);
midCounter++;
}
分区均衡
分区均衡的主要思想是,将每个分区的在各个 Backend 上的 replica 数量差(即 partition skew),减少到最小。因此只考虑副本个数,不考虑磁盘使用率。为了尽量少的迁移次数,分区均衡使用二维贪心的策略,优先均衡partition skew最大的分区,均衡分区时会尽量选择,可以使整个 cluster 的在各个 Backend 上的 replica 数量差(即 cluster skew/total skew)减少的方向。
资源控制
无论是副本修复还是均衡,都是通过副本在各个 BE 之间拷贝完成的。如果同一台 BE 同一时间执行过多的任务,则会带来不小的 IO 压力。因此,Doris 在调度时控制了每个节点上能够执行的任务数目。最小的资源控制单位是磁盘(即在 be.conf 中指定的一个数据路径)。Doris默认为每块磁盘配置两个 slot 用于副本修复。一个 clone 任务会占用源端和目的端各一个 slot。如果 slot 数目为零,则不会再对这块磁盘分配任务。该 slot 个数可以通过 FE 的 schedule_slot_num_per_hdd_path/schedule_slot_num_per_ssd_path
参数配置,用于为每块磁盘提供单独的 slot 用于均衡任务。目的是防止高负载的节点因为 slot 被修复任务占用,而无法通过均衡释放空间。
注意事项
涉及到be节点重启的操作,如集群升级
,需要关闭集群副本修复和均衡功能
先通过以下命令关闭:
admin set frontend config("disable_balance" = "true");
admin set frontend config("disable_colocate_balance" = "true");
admin set frontend config("disable_tablet_scheduler" = "true");
升级完成,并且所有 BE 节点状态变为 Alive
后,打开集群副本修复和均衡功能:
admin set frontend config("disable_balance" = "false");
admin set frontend config("disable_colocate_balance" = "false");
admin set frontend config("disable_tablet_scheduler" = "false");
总结
最后再回到文章开始的几个问题:
• 数据磁盘快用满了,怎么办?
• 数据磁盘用满之前,集群内部会通过高水位、危险水位等限制一些行为,尽可能避免磁盘变慢
• 数据磁盘用满之后,可以手动删除一些低优先级数据
• 数据误删了数据如何恢复
• 如果是误删了表,可以在一段时间内,可以通过recover指令恢复
• 如果是误删了tablet文件,可以在一段时间内,可以通过restore_tablet_tool.sh来恢复
• 副本损坏了该怎么修复
• Doris内部会有自动的修复机制,用户无需关心
• be节点新增存储目录或者新增be节点,存量的tablet数据会移动过去吗?
• Doris内部会有自动的副本均衡机制,用户无需关心
关于作者
隐形(邢颖) 网易资深数据库内核工程师,毕业至今一直从事数据库内核开发工作,目前主要参与 MySQL 与 Apache Doris 的开发维护和业务支持工作。
作为 MySQL 内核贡献者,为 MySQL 上报了 60 多个 Bugfix 及优化patch,多个提交被合入 MySQL 8.0 版本。从 2023 年起加入 Apache Doris 社区,Apache Doris Active Contributor,已为社区提交并合入数十个 Commits。
