





-导语-
本文介绍了Vasebase中执行器的实现原理,包括解决的问题、整体设计框架以及原理等。通过本文介绍,可以对Vastbase的执行器有一个基本的了解。
执行器在SQL执行过程中,接收优化器生成的执行计划,然后通过操作存储引擎提供的数据读写接口,实现对数据进行计算得到查询的结果集。如下图所示:

执行器接口抽象
Vastbase使用了经典的Tuple-At-A-Time模型,也即火山模型(Volcano-Model) 数据库的执行以算子迭代的方式进行驱动执行,每个算子抽象成为 open()/next()/close()三种类型操作,上层算子通过嵌套调用下层的next()进行处理 数据的返回,同样初始化的过程和结束过程也通过open()/close()嵌套调用,火山模型也是大多数传统数据库实现的执行模型,对比我们的数据库就是ExecutorStart、ExecutorRun、ExecutorEnd。

计划节点
根据计划生成的plan,进行对应算子的数据库,plan的数据结构抽象如下:
投影列信息表示了这个算子输出的成员列表,过滤条件在支持过滤的算子上才会有。有的算子同时有左右子树,例如JOIN算子,有的算子只有右子树,例如AGG算子。

对于算子执行完初始化阶段后,会将初始化的信息存到PlanState中。
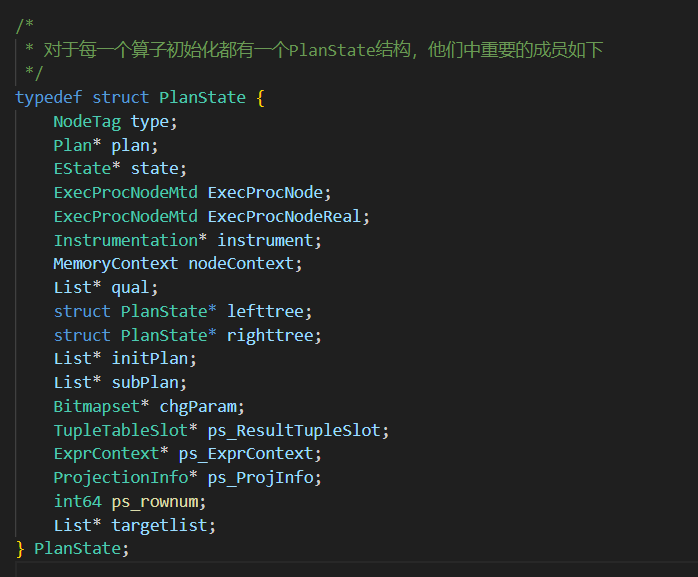
里面存储了执行器的信息,左右子树的路径,表达式执行的入口,内存上下文,以及一些统计信息等等。
表达式计算
执行算子实现了具体的算子逻辑,为了代数运算符的完备性,我们还需要表达式计算。根据SQL语句的不同,表达式计算可能产生在每个算子上,用于进一步处理算子上的数据流,主要有以下两个功能:
过滤:根据表达式的逻辑,过滤掉不符合规则的数据。
投影:根据表达式的逻辑,对数据流进行表达式变换,产生新的数据。
表达式计算的核心是对于表达式树的遍历和计算(算子也是用树来表达执行计划)。
例如SQL:
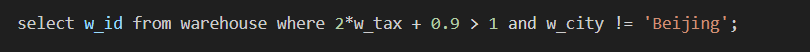
该SQL语句中有投影:w_id, 也有过滤条件:2*w_tax+0.9>1andw_city!='Beijing' 两个表达式需要执行,对于过滤的表达式树如下:

表达式需要先初始化才能进行调用,表达式包含过滤条件表达式,投影表达式等。在初始化过程中,接收计划树中的qual和targetlist进行处理。
当表达式初始化后会返回一个ExprState的数据结构,用于在执行期间进行表达式的计算。表达式的执行与火山模型类似,从顶层入口开始初步向下调用,然后数据从底部向上返回。在执行期间,表达式还需使用ExprContext来传递一下上下文,算子在执行表达式之前也会将外部获取到的数据放入ExprContext。
TupleTableSlot
TupleTableSlot是执行器中常用的数据结构,算子间传递数据都使用TupleTableSlot来进行。TupleTableSlot结构体中不仅用来传递元组,还是保存了元组的解析信息,元组在磁盘上没有解析之前无法直接访问每个字段,需要经过解析后才可以,但是也不会直接将全部字段都解析出来,而是在该字段被访问时才会进行解析,减少计算开销。
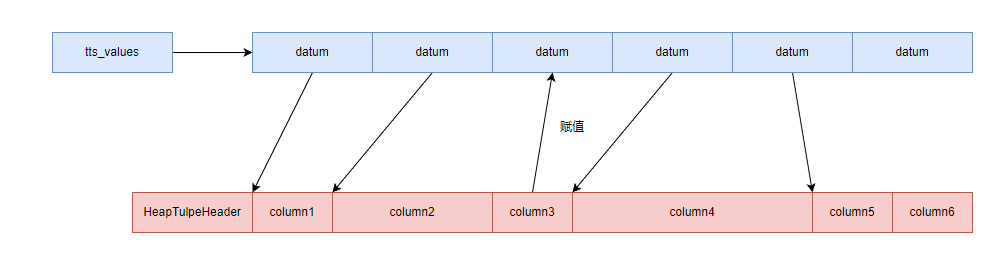
如图所示tts_values和tts_isnull的内存来自于tts_mcxt的上下文中进行分配,当元组进行解析的时候,如果这个元素是通过值传递的,那么就将值复制到对应下标的datum中,例如上面的column3,如果是通过地址传递的,那么就将元素的首地址放入datum中。
执行算子的分类
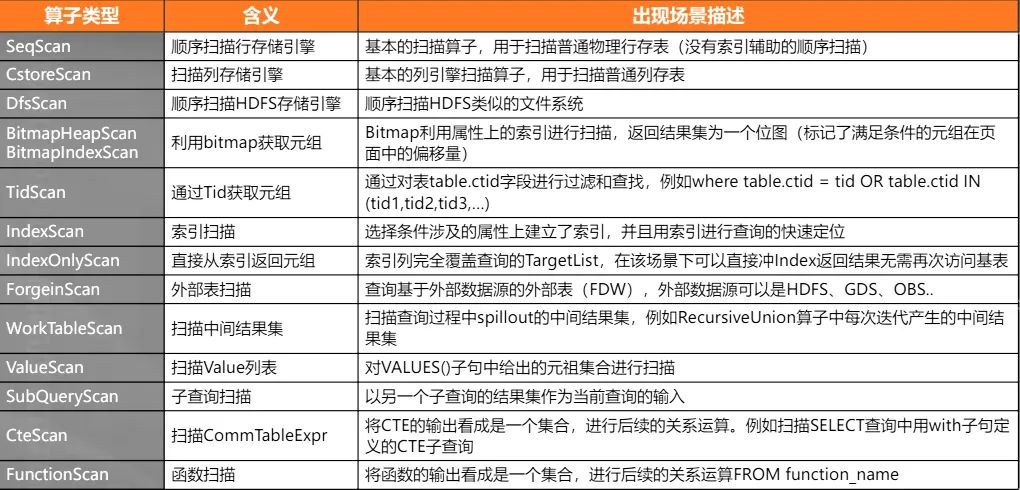
关系数据库本身是对关系集合Relation的运算操作,执行引擎作为运算的控制逻辑主体也是仪围绕着关系运算来实现的, 在传统数据库实现理论中,算子的分类可以分成以下几类:
扫描算子(Scan Plan Node)
扫描节点负责从底层数据来源抽取数据,数据来源可能是来自文件系统,也可能来自网络(分布式查询)。一般而言扫描节点都位于执 行树的叶子节点,作为执行树PlanTree的数据输入来源 关键特征:输入数据、叶子节点、表达式过滤。
控制算子(Control Plan Node)
控制算子一般不映射代数运算符,通常是为了执行器完成一些特殊的流程引入的算子 关键特征:用于控制数据流程。

物化算子(Materialize Plan Node)
物化算子一般指算法要求,在做算子逻辑处理的时候,要求把下层的数据进行缓存处理,因为对于下层算子返回的数据量不可提前预知, 因此需要在算法上考虑数据无法全部放置到内存的情况 关键特征:需要扫描所有数据之后才返回 。
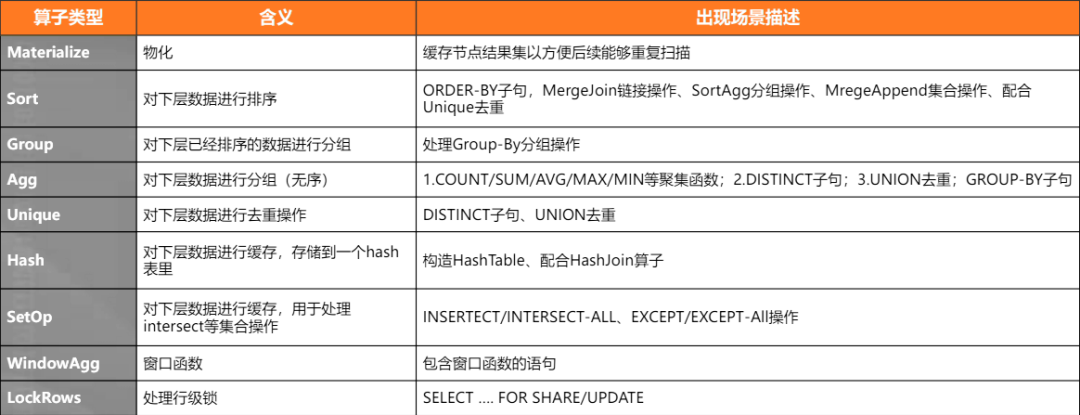
连接算子(Join Plan Node)
这类算子是为了应对数据库中最常见的关联操作,根据处理算法和数据输入源的不同分成几类 关键特征:多个输入。

-结语-
通过以上的介绍可以看出,Vastbase执行器利用了经典的火山模型执行引擎,可以很好地应对数据库中不同场景的执行需要。同时整体设计架构的扩展性较好,可以随时根据新的的查询场景进行扩展开发。
• END •
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列、海量大数据Datalink系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

