




问题引入
大家在做项目或者比赛的时候,经常会使用到k折交叉验证,但大家用的时候可能没有注意。这个K到底取多少合适呢?在面试过程中我们可能通常会遇到这样的问题。所以我们得提前准备一下哦.
问题解答
在理想情况下,可认为K折交叉验证可以降低模型的方差,从而提高模型的泛化能力,通俗地说,我们期望模型在训练集的多个子数据集上表现良好,要胜过单单在整个训练数据集上表现良好。(但实际上,由于我们所得到K折数据之间并非独立而存在相关性,K折交叉验证到底能降低多少方差还不确定,同时带来的偏差上升有多少也还存疑。)
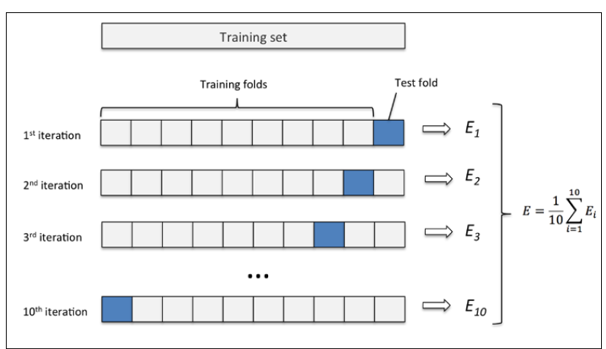
完全不使用交叉验证是一种极端情况,即K=1的情况下。在这个情况下所有数据都被用于训练,因而过拟合导致低偏差、高方差(low bias and high variance)。留一法是K折的另一种极端情况,即K=n。随着K值的不断升高,单一模型评估时的方差逐渐加大而偏差减小。但从总体模型角度来看,反而是偏差升高了而方差降低了。所以当K值在1到n之间的游走,可以理解为一种方差和偏差妥协的结果。
2017年的一项研究给出了另一种经验式的选择方法,作者建议k=log(n) 且保证n/K>3d ,n代表了数据量,d代表了特征数。
1、使用交叉验证的根本原因是数据集太小,而较小的K值会导致可用于建模的数据量太小,所以小数据集的交叉验证结果需要格外注意。建议选择较大的K值。2、当模型稳定性较低时,增大K的取值可以给出更好的结果 3、相对而言,较大的K值的交叉验证结果倾向于更好。但同时也要考虑较大K值的计算开销。
参考
https://blog.csdn.net/tianguiyuyu/article/details/80697223
https://zhuanlan.zhihu.com/p/38121870
https://www.cnblogs.com/pythonfl/p/12299110.html

