




KNN是啥?
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。面试的过程中不要说成是回归算法,当然面试官回问你能不能用来做回归,当然是可以的喽~~~
如果对于某个节点通过暴力找到其最近的K个点的话,计算效率可想而知是多大。现在已经发明了大量的基于树的数据结构可以使得近邻搜索的计算成本可以降低为O[DNlog(N)]或更低。 这是对于暴力搜索在大样本数N中表现的显著改善。下面说一波在sklearn中的实现方式是Kd tree和ball tree。
1. Kd tree
大家了解最多的可能就是Kd tree了,基本思想是对样本在笛卡尔空间进行矩形划分,虽然Kd tree 的方法对于低维度 (D<20) 近邻搜索非常快, 当D增长到很大时, 效率变低: 这就是所谓的“维度灾难” 的一种体现。
2. ball tree
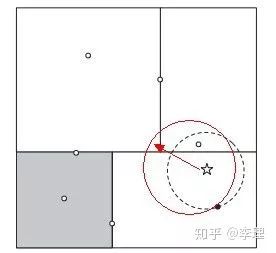
因为使用kd tree最近邻预测时,矩形与目标点和树上点构成的圆于相交,时常会因为菱角相交导致一些,无关多余的搜索,球树就是在kd树这个缺点上进行改进而生,通过将特征点转化为球状分割,从而减少无效相交。通过这种方法构建的树要比 Kd tree消耗更多的时间, 但是这种数据结构对于高结构化的数据是非常有效的, 即使在高维度上也是一样。

参考文献:
blog.csdn.net/weixin_41
宏观经济算命椰:【数学】kd 树算法之思路篇
blog.csdn.net/App_12062
文章转载自百面机器学习,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
