




group by功能
在SQL中group by主要用来进行分组统计,分组字段放在group by的后面;分组结果一般需要借助聚合函数实现。
SELECT
column_name1,column_name2, ......
聚合函数1,聚合函数2 , ......
FROM table_name
GROUP BY column_name1,column_name2, ......
说明:
1、group by中的分组字段和select后的字段要保持一致;
2、通常group by和聚合函数一起使用,但也可以不包含聚合函数。
3、常用的聚合函数有max()、min()、avg()、sum()、count()等。
CREATE TABLE `employee` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '姓名',
`gender` char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '性别',
`salary` int DEFAULT NULL COMMENT '薪资',
`department` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '部门',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
插入测试数据:
INSERT INTO `employee` (`id`, `name`, `gender`, `salary`, `department`)
VALUES
(1, '张三', '男', 1000, '营销部'),
(2, '李四', '女', 1500, '研发部'),
(3, '王五', '女', 4000, '营销部'),
(4, '赵六', '男', 5000, '研发部'),
(5, '孙七', '女', 1500, '研发部'),
(6, '周八', '男', 2500, '营销部'),
(7, '吴九', '男', 1500, '人事部'),
(8, '郑十', '女', 2500, '财务部'),
(9, '刘备', '男', 1500, '人事部'),
(10, '孙权', '女', 1500, '人事部'),
(11, '程序员恰恰', '男', 2500, '财务部'),
(12, '周扒皮', '女', 2500, '财务部');
查询所有:
select * from employee
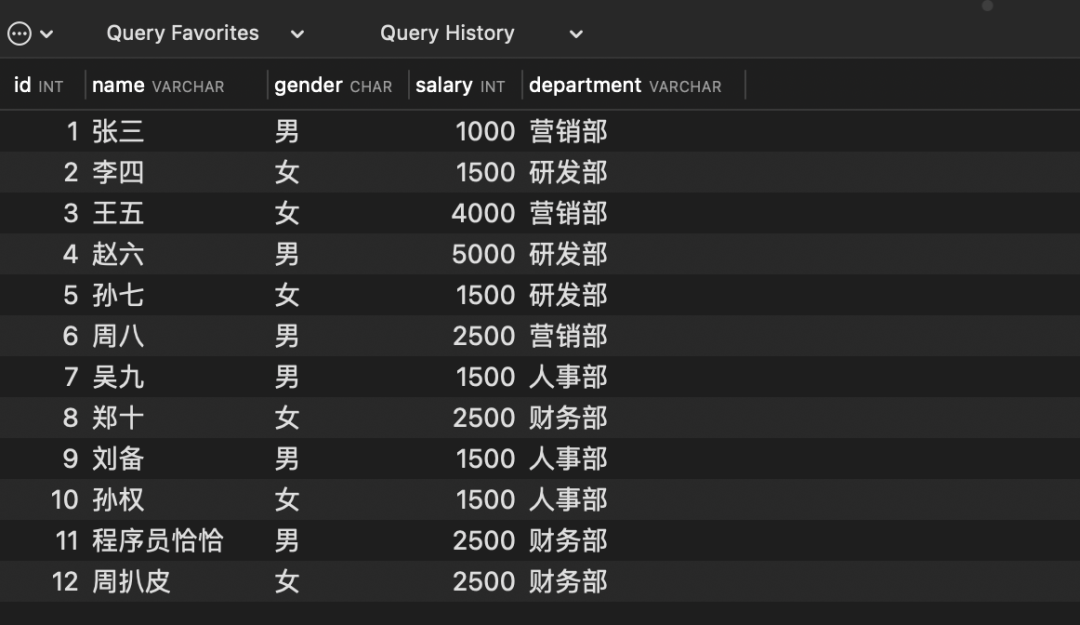
# 按照部门名称进行分组,查询各部门工资之和
select department, sum(salary) from employee group by department
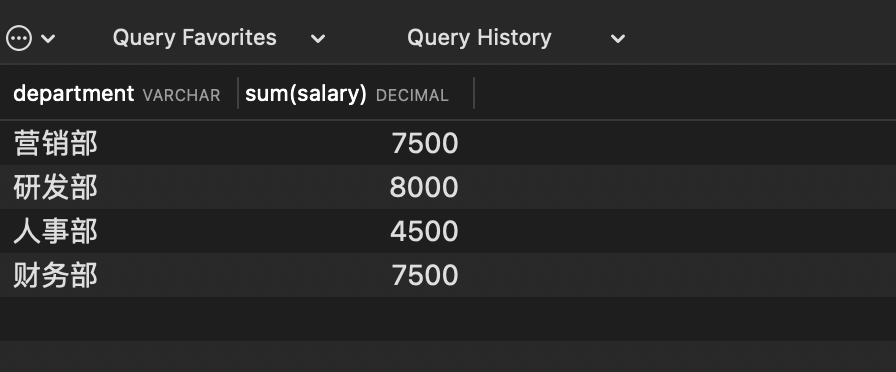
# 按照部门名称进行分组,查询各部门工资之和大于5000的部门
select department, sum(salary) from employee group by department
having sum(salary)>5000 and department !='营销部门'
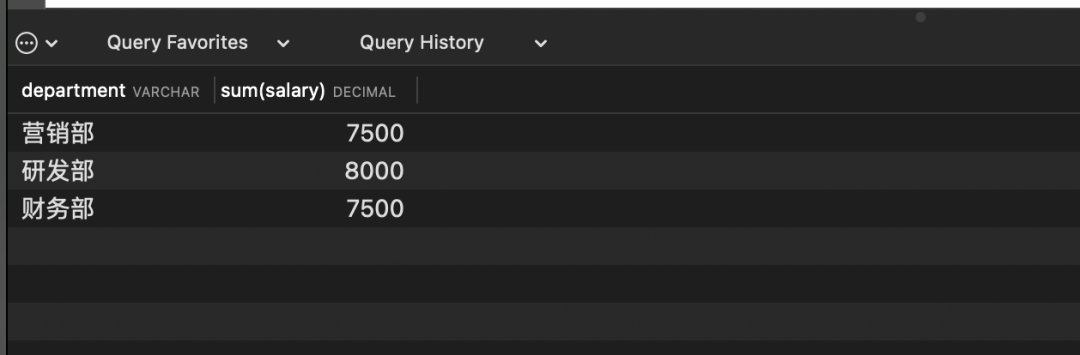
# 按照部门分组,查询非营销部且部门总工资大于5000的部门select department, sum(salary) from employee group by department
HAVING department NOT LIKE '营销部' AND SUM(salary) > 5000;
#等价于
select department, sum(salary) from employee
where department NOT LIKE '营销部' group by department
HAVING SUM(salary) > 5000
having是在分组后对数据进行过滤,where是在分组前对数据进行过滤。having后面可以使用分组函数进行过滤(统计计算),where后面不能使用分组函数,where是分组前的记录的条件,如果记录没有满足where,那么这行记录就不会参与分组。
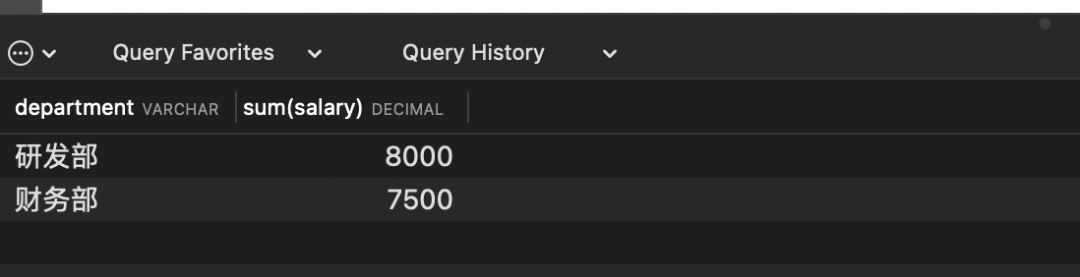
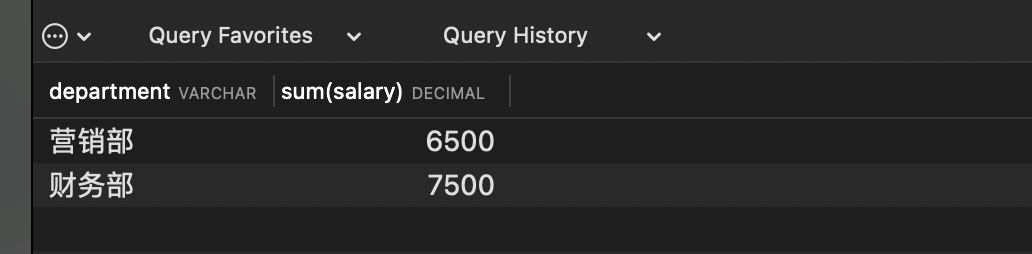
# 查询工资大于2000的,部门总工资之和大于5000的部门
select department, sum(salary) from employee
where salary >2000
group by department having sum(salary)>5000
查询结果:
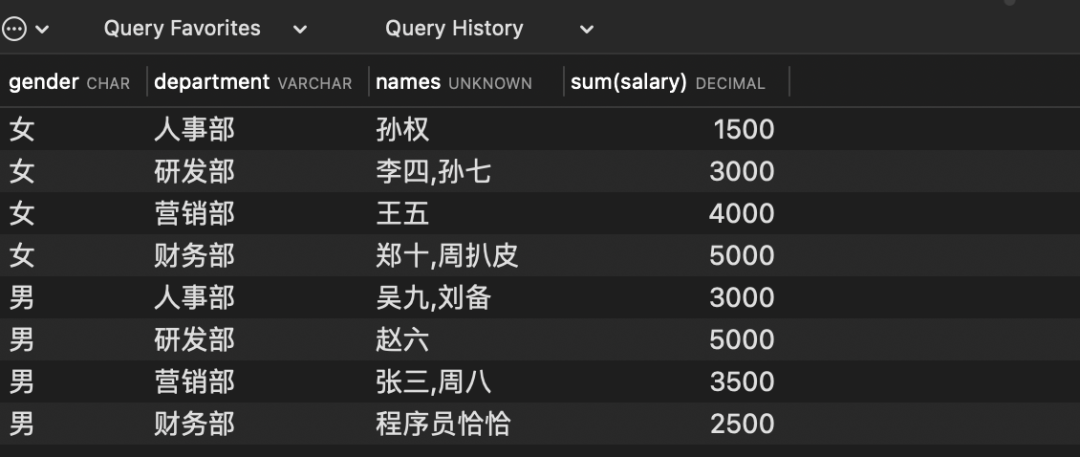
# 按照性别和部门分组
select gender, department, group_concat(name) names,sum(salary) from employee
group by gender ,department
查询结果:group_concat(name)可以返回本组的数据有哪些。
总结一下:你使用了group by后,那你select的列就只能是group by的列或者对其他列进行聚合运算。
注意:新版的mysql 在group by的时候,如果你查询的字段不在分组字段里的时候会报only_full_group_by的错
其实正规的来说,就应该给你报错,你group by的时候,查询的字段就应该是分组的字段或者对其他列进行聚合运算。
按分组字段分完组后,其他不是分组的字段,就可能出现多个值,那怎么办,那就需要用聚合函数,聚合函数的作用就是,输入多个数据,给你产出一个数据


文章转载自程序员恰恰,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
