




一、摘要
分享论文《Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution》
二、引入
在两篇数学文章之后,本文回归计算机,今天讨论一个计算机内十分原始的问题:我们乒乒乓乓这么久又是机器学习又是人工智能,机器究竟距离人还差啥?
一定程度上,前两篇概率的思考都是为这篇文章做铺垫,第一次看到这个文章的摘要的时候,我就感觉无论如何要深入分析一下这个文章。但另一方面又有点担心,因为过去的胡思乱想已经足够民科了,而这篇文章如果不是因为作者的话,就是一篇十足的民科YY。

所以还是先说一下作者,Judea Pearl,中文的一些资料一般称之为珀尔,他是一位以色列裔美国计算机科学家,现在是加州大学洛杉矶分校的一名教授,1980年将贝叶斯算法引入机器学习领域,2011年获得图灵奖,真人如上图。但是他在国内甚至世界的知名度似乎都谈不上很高,至少我是第一次知道这个人,主要还是他的研究方向可能比较冷门,我们可以看一下本文的参考文献:
A. Balke and J. Pearl. 1994. Probabilistic evaluation of counterfactual queries. In Proceedings of the Twelfth National Conference on Artificial Intelligence. Vol. I. MIT Press, Menlo Park, CA, 230–237.
E. Bareinboim and J. Pearl. 2016. Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences 113 (2016), 7345–7352. Issue 27.
A. Darwiche. 2017. Human-Level Intelligence or Animal-Like Abilities? Technical Report. Department of Computer Science, University of California, Los Angeles, CA. arXiv:1707.04327.
J.Y. Halpern and J. Pearl. 2005. Causes and Explanations: A Structural-Model Approach—Part I: Causes. British Journal of Philosophy of Science 56 (2005), 843–887.
K. Mohan and J. Pearl. 2017. Graphical Models for Processing Missing Data. Technical Report R-473, <http://ftp.cs.ucla.edu/pub/stat ser/r473.pdf>. Department of Computer Science, University of California, Los Angeles, CA. Submitted.
S.L. Morgan and C.Winship. 2015. Counterfactuals and Causal Inference: Methods and Principles for Social Research (Analytical Methods for Social Research) (2nd ed.). Cambridge University Press, New York, NY.
J. Pearl. 1988. Probabilistic Reasoning in Intelligent Systems. Morgan Kaufmann, San Mateo, CA.
J. Pearl. 1993. Comment: Graphical Models, Causality, and Intervention. Statist. Sci. 8, 3 (1993), 266–269.
J. Pearl. 1995. Causal diagrams for empirical research. Biometrika 82, 4 (1995), 669–710.
J. Pearl. 2000. Causality: Models, Reasoning, and Inference. Cambridge University Press, New York. 2nd edition, 2009.
J. Pearl. 2001. Direct and indirect effects. In Uncertainty in Artificial Intelligence, Proceedings of the Seventeenth Conference. Morgan Kaufmann, San Francisco, CA, 411–420.
J. Pearl. 2015a. Causes of Effects and Effects of Causes. Journal of Sociological Methods and Research 44 (2015), 149–164. Issue 1.
J. Pearl. 2015b. Trygve Haavelmo and the emergence of causal calculus. Econometric Theory 31 (2015), 152–179. Issue 1. Special issue on Haavelmo Centennial.
J. Pearl and D. Mackenzie. 2018, forthcoming. The Book of Why: The New Science of Cause and Effect. Basic Books, New York.
J. Peters, D. Janzing, and B. Sch¨olkopf. 2017. Elements of Causal Inference – Foundations and Learning Algorithms. The MIT Press, Cambridge, MA.
J.M. Robins and S. Greenland. 1992. Identifiability and Exchangeability for Direct and Indirect Effects. Epidemiology 3, 2 (1992), 143–155.
P. Rosenbaum and D. Rubin. 1983. The central role of propensity score in observational studies for causal effects. Biometrika 70 (1983), 41–55.
I. Shpitser and J. Pearl. 2008. Complete Identification Methods for the Causal Hierarchy. Journal of Machine Learning Research 9 (2008), 1941–1979.
P. Spirtes, C.N. Glymour, and R. Scheines. 2000. Causation, Prediction, and Search (2nd ed.). MIT Press, Cambridge, MA.
J. Tian and J. Pearl. 2002. A general identification condition for causal effects. In Proceedings of the Eighteenth National Conference on Artificial Intelligence. AAAI Press/The MIT Press, Menlo Park, CA, 567–573.
S. Toulmin. 1961. Forecast and Understanding. University Press, Indiana.
T.J. VanderWeele. 2015. Explanation in Causal Inference: Methods for Mediation and Interaction. Oxford University Press, New York.
我们发现本文的22篇参考文献中,只有6篇不是他写或合作完成的。事实上本文是一篇很新的文章,2018年1月11号发表的,这篇文章中的一些例子和语段实际上来自Pearl之前的一些书上的内容,这篇文章基本上就是对Pearl之前研究的在机器学习领域的一个综述后得到的一个结论。事实上,这篇文章起源的背景是Rahimi在2017年NIPS大会上的演讲[9],演讲中提到深度学习和古代的炼金术很相似。这篇演讲立刻激起学术界很多大牛的反对,反对最激烈的就是深度学习三巨头之一的LeCun[7],在我所掌握的资料来看,这个问题争论到今天依然没有答案,很多计算机研究人员后来开始自嘲自己的研究过程是炼金。事实上这个问题的本质就是本文开头所提的问题“机器究竟距离人还差啥”。我们在百度随便搜搜“炼金+深度学习”就有很多大佬在讨论[6,11]。
其中除了本文介绍的这个文章还出来很多重量级的文章,比如google的DeepMind和MIT一大帮子人在2018年6月发的《Relational Inductive Bias for Physical Construction in Humans and Machines》[3]讨论深度学习的因果推理问题,还有Gary Marcus在2018年1月发的《Deep Learning: A Critical Appraisal》[8,10]对深度学习的批判。
我们发现似乎很多自然科学发展到一定阶段都会陷入哲学怪圈,一个世纪以前的物理学是这样,一个世纪以后的计算机也是这样。从另一个角度看,一个世纪以前的讨论后,人类社会的基础科学红利开始逐渐变缓。一个世纪以后计算机在基础计算机科学高速迭代了几十年以后,我们其实已经能看到有些传统计算机领域出现疲软了,技术进步的红利逐渐消失,互联网开始变冷,是否也是一样的规律呢?如今计算机的讨论也一定程度开始有哲学的身影,但好在如今信息是爆炸的,怀疑和争论都会迅速发酵,大大缩短了大多数科研工作者的迷茫期。

回到分享,作为争论的发言文,这篇文章很多观点和依据都来自Pearl的两本著作《Causality: Models, Reasoning, and Inference》[12]和《The Book of Why》[2],这两本书主要都是在讲因果关系的问题,主要看第二本书,序中提到:
这本书致力于完成一个三步走的任务:
首先,用非数学语言向你展示因果革命的知识内容,以及它如何影响我们的生活和未来;
第二,与你们分享一些科学家在面对关键的因果关系问题时所进行的英勇之旅,既有成功的,也有失败的。
最后,让因果革命回到人工智能的发源地,我的目标是向你们描述如何构建能够学会用我们的母语——因果语言——交流的机器人。新一代的机器人应该向我们解释为什么会发生这样的事情,为什么它们会做出这样的反应,为什么大自然会以一种方式而不是另一种方式运作。更有野心的是,它们还应该教会我们了解自己:为什么我们的大脑会这样运作,理性思考因果关系、荣誉和遗憾、意图和责任意味着什么。
这本书第一章中还提到:
当我第100次重读《创世纪》时,我注意到一个细微的差别,多年来不知怎的一直没有引起我的注意。 当上帝发现亚当藏在花园里时,他问:“你吃了我禁止你吃的那棵树上的果子了吗?” 亚当回答说、你所赐给我作伴的女人、就是那树上的果子、给我吃。 “你做了什么?” 上帝问夏娃。 她回答说:“蛇欺骗了我,我吃了。”
我们都知道,这种互相指责的游戏对万能的上帝不起作用,他把他们俩都赶出了花园。 但我以前忽略了一点:上帝问“什么”,他们回答“为什么”。 上帝问他们事实,他们回答说有道理。 此外,两人都深信,说出原因会以不同的方式描绘他们的行为。 他们是从哪里得到这个想法的?
对我来说,这些细微差别有三个深刻的含义。 首先,在我们进化的早期,我们人类意识到世界不仅仅是由枯燥的事实组成的(我们今天可能称之为数据); 相反,这些事实是由错综复杂的因果关系网络连接在一起的。 第二,因果解释,而不是枯燥的事实,构成了我们知识的大部分,应该是机器智能的基石。 最后,我们从数据处理器到解释制造者的转变不是渐进的; 这是一个飞跃,需要从一个不寻常的水果外部推动。 这与我在因果关系阶梯理论中观察到的情况完全吻合:没有机器能从原始数据中得出解释。 它需要一个推力。
关于因果关系本身,维基百科在工程学、法律、物理、哲学和宗教都做了说明[13]:
工程学:
因果系统是指该系统的输出和内部状态取决于当前和以前的输入值。如果系统除依赖当前和过去的输出值以外,还会依赖于未来的输出值,则该系统为非因果系统(acausal system),而如果只依赖于未来的输出值,则是反因果系统(anticausal system)。
法律:
根据法学理论,要认定被告对犯罪或侵权行为承担责任,必须证明存在法律上的因果关系。在国际商法中,为获得救济,因果关系也是要必须证明的一个关键法律因素。
物理:
非正式的场合中,物理学家使用因果关系一词和普通人所说的该词没什么差别。例如,在物理理论中,一些物理学家会说力导致了运动的改变(或加速)。然而,严格说来,这并非因果律的正式理论。因果关系并不内在隐含于运动公式中,而是假定作为一个额外的需要满足的限制条件,也即,原因总是先于效果。
西方哲学:
亚里士多德提出四因说,对原因问题概括了四种答案或解释模式,即质料因、形式因、动力因、目的因。
然而,随着中世纪的结束,亚里士多德的方法,尤其是涉及形式因和目的因,遭到了批评,例如马基亚维利在政治学领域,以及弗兰西斯·培根在科学领域。当代广为使用的关于因果关系的定义出自大卫·休谟;他认为,我们只不过发展了一个思考习惯,把总是前后相继的两类客体或事件联系起来,除此之外,我们无法感知到原因和结果。
热力学:
19世纪发现的热力学第二定律帮助确定了时间之箭。这使得我们可以描述原因何以不同于结果:效果的总和绝不会比原因的总和熵更低。
决定论:
宇宙只不过是根据因果律而发生的一连串事件,并不存在什么自由意志。而相容论则认为决定论对于自由意志是相容的,甚至是必要的。存在主义认为虽然本质意义是在决定论的宇宙中设计的,但我们每个人都可以为我们自己提供意义。
关于因果律在计算机上的作用,在我看来是和人工智能的起源所有关的,人工智能从历史上一直是一个目标驱动问题的很不健康的过程。图灵这家伙不是好东西,一开始造机器就奔着造人去弄的,弄得后面大家都觉得搞计算机就是搞人工智能。其实本身是两码事,计算机的客观研究一直是做着数学计算的事情,而且从冯诺依曼之后计算机就有了严格且精确的工程意义,这对应着算法和工程两个方向。图灵主推的人工智能起源于一个目标,即让机器成人。这个目标如此宏大和让人热血沸腾,因为无论是基督教还是中国的神话传说,造人都是神才能干的事。但大家脑子一热,就觉着计算器好神奇,拿着键盘就开始干了,甚至连要解决的问题都放在一边。
早期人工智能是没有好问题的,大家都在搞数学计算本身。后来问题一点点进步,研究人员逐渐根据两类问题团结成两派[14]:
联结主义:归纳总结。主要为神经网络及神经网络间的连接机制与学习算法。主张模仿人类的神经元,用神经网络的连接机制实现人工智能。主要包括神经网络、特征工程、聚类分类等算法。
符号主义:逻辑演绎。主要为物理符号系统(即符号操作系统)假设和有限合理性原理,主张用公理和逻辑体系搭建一套人工智能系统。主要包括语义网、知识图谱等内容。
有的地方还有行为主义(比如遗传算法、强化学习等),但我并不认可行为主义能和联结主义以及符号主义并列,因为行为主义没有触及信息的本质,虽然目标很大,但它缺乏很严格的理论。
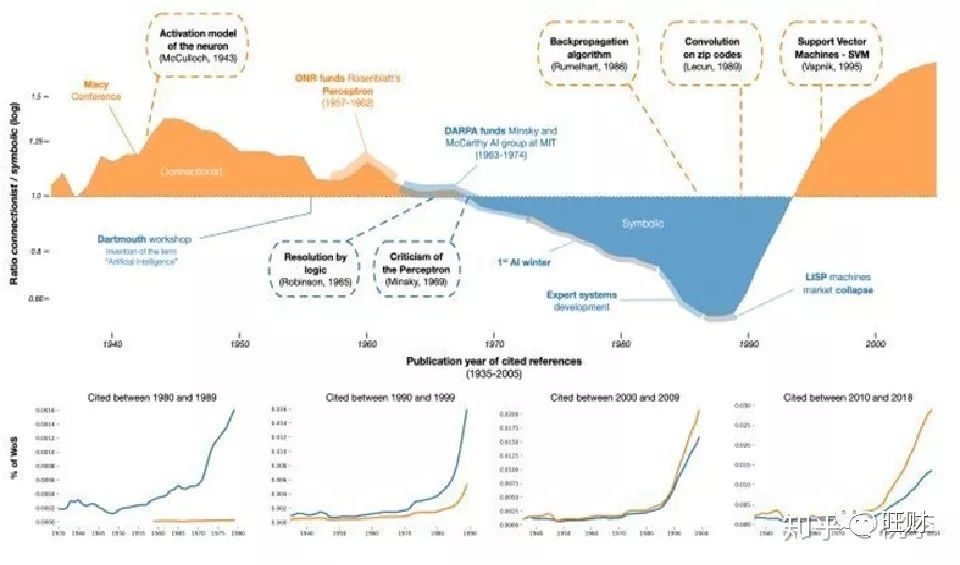
这两个派别的发展如上图所示,最初是连接主义(图中的黄色部分)占上风,到上个世纪70年代到90年代中期,是符号主义成为主流,而后则又是连接主义(图中的蓝色部分)占据垄断地位。这个问题感兴趣可以去看人工智能的发展史。
三、七大障碍
回到分享文,Pearl认为当前的机器学习系统主要学习的是统计知识,这带来了严重的理论限制,使得计算机几乎不能“对干预和回顾进行推理”,因此“不能作为强工智能的基础”。为了说明这个问题,Pearl列举了机器学习无法完成的七类任务。这七类任务按照属性可以归为3类:
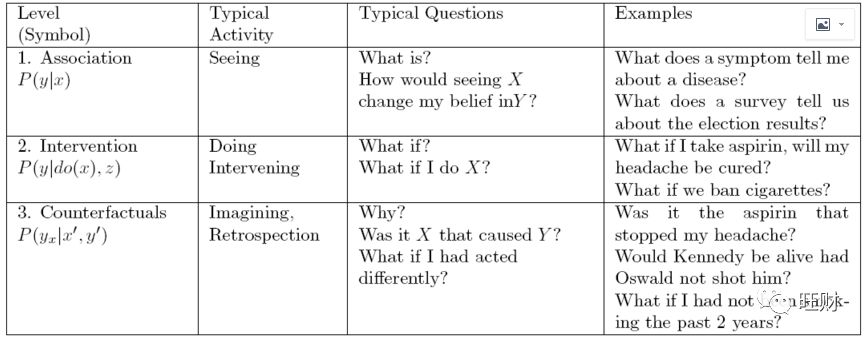
学习机通过优化从环境接收到的一系列感官输入的参数来提高性能。这是一个缓慢的过程,在许多方面类似于推动达尔文进化论的自然选择过程。它解释了像鹰和蛇这样的物种如何在数百万年的时间里发展出了高超的视觉系统。然而,这并不能解释人类在不到一千年的时间里就能制造出眼镜和望远镜的超级进化过程。人类拥有的是其他物种所缺乏的一种精神表征,一种他们可以随意操纵的环境蓝图,用来想象另一种可供规划和学习的假想环境。这使得大约40000年前我们现代人的祖先有了统治全球的能力。
这问题特征如下:
关联
调用由裸数据定义的纯统计关系。
例如,观察一位购买牙膏的顾客,他/她更有可能购买牙线
这种关联可以使用条件期望直接从观测数据推断出来。
这一层的问题,因为它们不需要因果信息,所以放在层次结构的最底层。
干预
比联想更重要,因为它不仅涉及看到什么,而且涉及改变我们看到的。
在这个水平上,一个典型的问题是:
如果我们把价格提高一倍,会发生什么?
这些问题不能仅从销售数据来回答,因为它们涉及到客户行为的变化,对新定价的反应。
这些选择可能与以前涨价时的选择有很大不同。
(除非我们完全复制价格达到当前价格两倍时的市场状况。)
反事实
这个术语可以追溯到哲学家大卫•休谟(David Hume)和约翰•斯图尔特•密尔(John Stewart Mill),在过去20年里,它被赋予了计算机语义。
反事实类别中的一个典型问题是“如果我采取了不同的行动会怎样?”反事实位于层次结构的顶部,因为它们包含了介入和关联问题。
如果我们有一个模型可以回答反事实的问题,我们也可以回答关于干预和观察的问题。
比如:如果价格翻倍会发生什么?
我们可以问一个反事实的问题来回答这个问题:
如果价格是当前价值的两倍,会发生什么?
同样,一旦我们能回答介入性问题,联想性问题就能得到回答;
我们只是忽略了行动的部分,让观察取而代之。
反事实是科学思维的基石,也是法律和道德推理的基石。
例如,在民事法庭上,如果没有被告的行为,伤害很可能不会发生,那么被告就被认为是伤害的罪犯。
【障碍1:编码因果假设——透明性和可测试性】
一旦我们认真对待透明性和可测试性的要求,以紧凑和可用的形式对假设进行编码就不是一件小事了。
透明度使分析人员能够辨别编码的假设是否可信(基于科学的理由),或者是否需要额外的假设。
可测试性允许我们(无论是分析师还是机器)确定编码的假设是否与可用数据兼容,如果不兼容,则确定需要修复的假设。
图形模型的进步使得压缩编码成为可能。
它们的透明性自然源于这样一个事实:
所有的假设都是以图形方式编码的,反映了研究人员对该领域因果关系的认知方式;不需要判断反事实或统计相关性,因为这些可以从图的结构中读出。
可测试性是通过一个叫做d-separation的图形标准来实现的,它提供了原因和概率之间的基本联系。
它告诉我们,对于模型中任何给定的路径模式,我们应该期望在数据中找到什么样的依赖关系模式。
【障碍2:做微积分和控制混淆】
混淆,或存在两个或两个以上变量的未观察到的原因,长期以来一直被认为是从数据中得出因果推断的主要障碍,这一障碍已通过一种称为“后门”的图形标准被解密和“消除”。
特别是,选择一组合适的协变量来控制混杂的任务已经被简化为一个简单的“路障”难题,可以用一个简单的算法来解决。
对于“后门”标准不成立的模型,可以使用一种符号引擎,称为do-calculus,它在可行的情况下预测政策干预的效果,在无法用特定假设确定预测的情况下失败退出。
【障碍3:反事实的算法化】
反事实的分析处理特定个人的行为,确定了一套不同的特点,例如,考虑到乔的工资是Y = Y,和他去X = X年大学,乔的工资是他一年的教育。
因果革命最重要的成就之一是在图形表示中形式化反事实推理,而图形表示正是研究人员用来编码科学知识的表示。
每一个结构方程模型决定了每一个反事实句的真值。
因此,我们可以通过分析来判断这个句子的概率是可以通过实验研究或观察研究来估计的,还是通过实验研究或观察研究的结合来估计的。
因果语篇中特别感兴趣的是关于“结果的原因”而不是“原因的结果”的反事实问题。
例如,乔的游泳运动是乔死亡的必要(或充分)原因的可能性有多大。
【障碍4:调解分析和评估直接和间接影响】
中介分析关注的是将变更从原因传递到结果的机制。
确定这种中间机制对于产生解释至关重要,必须援引反事实分析来促进这种确定。
反事实的图形表示使我们能够定义直接和间接的影响,并决定什么时候这些影响可以从数据或实验中估计。
通过这种分析可以回答的典型问题是:X对Y的影响中有多少是由变量Z介导的?
【障碍5:外部有效性和样本选择偏差】
每一项实验研究的有效性都受到实验和实施机构之间的差异的挑战。
除非对环境条件进行本地化和识别,否则在一个环境中训练过的机器在环境条件发生变化时,就不能指望它能很好地工作。
这个问题以及它的各种表现形式都被机器学习研究人员很好地认识到,而企业,如“领域适应”、“转移学习”、“终身学习”和“可解释的人工智能”,只是研究人员和资助机构为了减轻鲁棒性这一普遍问题而确定的一些子任务。
不幸的是,健壮性问题需要环境的因果模型,并且不能在关联级别上处理,而大多数补救措施都是在关联级别上尝试的。
关联不足以确定发生的变化所影响的机制。
上面讨论的do-calculus现在提供了一个完整的方法来克服由于环境变化而产生的偏见。
它既可以用来重新调整学习策略以规避环境变化,也可以用来控制由于非代表性样本而产生的偏见。
【障碍6:缺少数据】
缺少数据的问题困扰着实验科学的每一个分支。
受访者不会回答问卷上的每一项问题,传感器会随着环境条件的变化而褪色,患者往往会因为未知的原因退出临床研究。
关于这个问题的丰富文献都是与统计分析的模型盲范式相结合的,因此,它严重局限于随机出现缺失的情况,即不依赖于模型中其他变量所取的值。
利用缺失过程的因果模型,我们现在可以形式化从不完整的数据中恢复因果关系和概率关系的条件,并且,只要满足条件,就可以对期望的关系产生一致的估计。
【障碍7:因果发现】
上面描述的d-separation准则使我们能够检测和列举给定因果模型的可测试含义。
这就为用温和的假设推断一组与数据兼容的模型提供了可能,并能简洁地表示这组模型。
系统的搜索已经开发出来,在某些情况下,可以大幅削减兼容模型集,使因果查询可以直接从该集估计。
这六个障碍文中说的语焉不详,很多是Pearl之前研究过程中举出的案例,在后面我会对Pear的书进行一下介绍,再反过来看这个文章就能清晰一些。最后,Pearl给出了结论:
回到强大的人工智能,我们已经看到,盲学习机器对它们能够执行的认知任务有内在的限制。我们的普遍结论是,人类水平的人工智能不能仅仅从盲学习机器中产生,它需要数据和模型的共生协作。数据科学仅仅是一门科学,因为它有助于解释数据——一个将数据与现实联系起来的两体问题。数据本身很难成为一门科学,不管它们有多大,也不管它们被如何巧妙地运用。
四、参考文献
[1] Pearl, Judea. 2018. “Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution.” arXiv:1801.04016 [cs, stat]. http://arxiv.org/abs/1801.04016[2] J. Pearl and D. Mackenzie. 2018, forthcoming. The Book of Why: The New Science of Cause and Effect. Basic Books, New York.[3] Hamrick, Jessica B. et al. 2018. “Relational Inductive Bias for Physical Construction in Humans and Machines.” arXiv:1806.01203 [cs, stat]. http://arxiv.org/abs/1806.01203[4] CNN已老,GNN来了:重磅论文讲述深度学习的因果推理,csdn,https://blog.csdn.net/enohtzvqijxo00atz3y8/article/details/80730749[5] NIPS机器学习炼金术之争,Twitter机器学习研究员参战,http://www.sohu.com/a/209219735_473283[6] MIT人工智能教授:深度学习是这个时代的炼金术,http://tech.qq.com/a/20180128/009567.htm[7] 深度学习是科学还是炼金术?LeCun 演讲,https://zhuanlan.zhihu.com/p/59632910[8] Marcus, Gary. 2018. “Deep Learning: A Critical Appraisal.” arXiv:1801.00631 [cs, stat]. http://arxiv.org/abs/1801.00631 (May 8, 2019).[9] rahimi长滩演讲,https://imgcache.qq.com/tencentvideo_v1/player/TPout.swf?max_age=86400&v=20140714[10] 对话Gary Marcus:人工智能还未找到它的牛顿,我们不能依赖它,https://zhuanlan.zhihu.com/p/56355420[11] Tomaso Poggio:深度学习需要从炼金术走向化学,http://www.360doc.com/content/18/0128/15/38093621_725792947.shtml[12] J. Pearl. 2000. Causality: Models, Reasoning, and Inference. Cambridge University Press, New York. 2nd edition, 2009.[13] 因果关系,维基百科,https://zh.wikipedia.org/wiki/因果关系[14] 顾险峰. (2016). 人工智能中的联结主义和符号主义. 科技导报, 34(7), 20-25.
