




一、摘要
介绍一偏用户画像的文章《Look Who's Talking: Inferring Speaker Attributes from Personal Longitudinal Dialog》
二、引入
用户画像是所有搞推荐搜索广告的人在面对的第一关,因为用户不会主动把自己的详细信息交给算法开发人员,所以如何从用户和产品之间的交互中来推测用户的属性是所有算法工程师的必备手艺。
这篇文章的作者有四人,分别是Charles Welch, Veronica Perez-Rosas, Jonathan K. Kummerfeld, Rada Mihalcea,第四个人是一名教授,前三个人是她的学生,她研究的方向是:
计算社会语言学(跨文化价值学习、基于文本的地理定位、基于语言的世界观建模、多模态人格检测、欺骗检测)
人类行为的多模态感知和跟踪(欺骗、情感、压力、警觉性)
语言与视觉的联合建模(文本-视频问答、文本-图像相似性、图像标注)
词汇语义(语义相似、词义消歧、词汇替代)
基于图的自然语言处理算法(文本摘要、词义消歧、关键词提取、类别分配)
多语言自然语言处理
多语言的主体性、情感性和情感分析
计算幽默
前面几个没什么好说的,最后一个计算幽默是个什么鬼?看了下她的文章,关于幽默的文章有[4-9],可以作为后续的一个课题研究一下。她的很多文章和很多研究课题的代码和数据都可以在她博客上下载[2],值得尊敬!
看这个文章之前,先对其前序文章梳理一下,按照作者的介绍,和他研究最相关的是一个通过观察Facebook用户[3]讨论的单词、短语和话题在语言使用上的群体差异,来识别性别、年龄和性格等方面的文章《Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach》,这篇文章放在下一个公众号文章内。
三、模型
【目标数据】
数据源来自这篇文章的其中一位作者贡献的个人facebook聊天记录(所以没有公开,但作者给了一些下载个人数据的步骤,可以用google,facebook,imessage或instagram做实验),包含这个人和他104个好友之间的近45W的对话消息。作者人工对这份语料进行了分组:
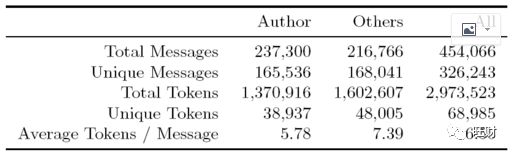
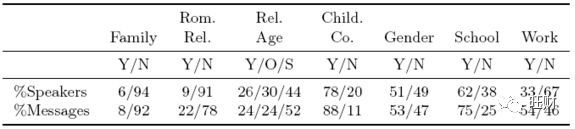
【参考数据】
Glove词库:作者这里使用的是斯坦福大学公开的训练好的Glove模型,作者说这样选择的原因是因为这份嵌入模型的训练数据集和他的比较接近。下载地址在:https://nlp.stanford.edu/data/
LIWC词汇表[10]:可以在https://liwc.wpengine.com/这里下载,包含了每个单词的心理属性。不过是收费的,作者在文中把最常见的一些词列了出来,但作者的实验用的是全量的LIWC的词表:

事实上类似的东西国内也有,比如CN-DBpedia和百度知识图谱等。有了训练数据和参考数据,剩下的就是模型选择了。
【模型】
作者使用的模型是seq2seq模型,输入的seq是原始内容词向量和从内容中提取的9种特征的组合,输出的是用户画像的7类特征。
输入9种特征:
交谈的用户描述向量
LIWC值
消息时间:包括消息间隔、每条消息的具体时间(精确到秒)、每组消息在当日出现的小时
消息频率:和目标用户之间近一天、近一周、近一月和总的消息数
Turn change vector:如果目标是7类输出特征中的某一个,那么输出特征中余下的6个将作为一个输入特征
Stopword:停止词词典中的词出现的频率
消息风格LSM值:作者这里使用9类虚词归一化的得分来定义消息风格,这一策略来09年的一篇文章《Language style matching as a predictor of social dynamics in small groups》[11]
对话统计特征:包括对话总词数,双方各自的词数等等
用户关系图:作者将这个特征定义为先把所有的语料中谈话双方提及第三个人情况作为一种训练依据来训练用户之间的相关度
输出的7个特征:
性别
相对年龄
家庭成员
是否有浪漫关系
同学
同事
同一个国家
注意所有输入特征都是来自于上下文,没有对用户的预先标注的某些内容,只有训练过程才有标注的数据集。这意味着这个模型可以应用在很多对话预测领域。
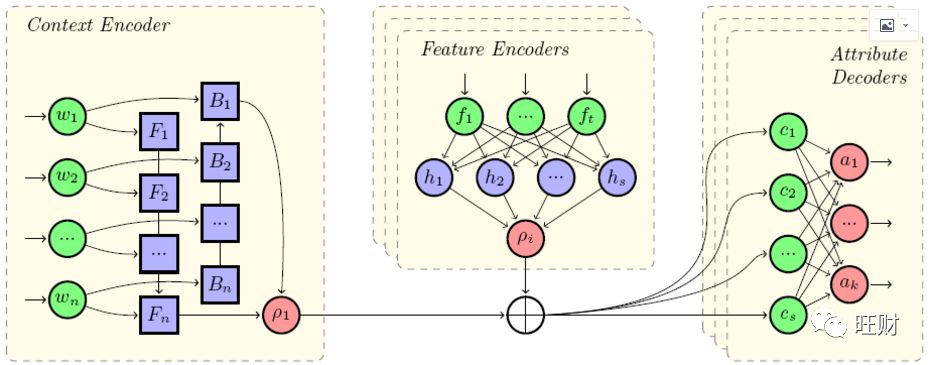
从上图的模型中可以看出,如果没有对feature的encoder,那么整个模型就是一个很标准的词嵌入+BiLSTM+seq2seq的模型,而对输入特征实际额外添加了一个全连接层进行特征组合和优选,且输入特征的 ρ 并不是使用同一个全连接层进行选择的。模型的具体细节文中没有过多说明,但是好在本文代码是提供的[1]。
【数据提取的代码】
代码中作者对每一种特征的提取都单独写了一个python脚本,比如如果对支持的数据直接运行,那么需要把数据放在这里:
GOOGLE_PATH = '/path/to/Hangouts.json'FACEBOOK_PATH = '/path/to/facebook/messages/'IMESSAGE_PATH = '/path/to/imessage-chat/chat.db'INSTAGRAM_PATH = '/path/to/instagram/messages.json'
然后运行message_formatter,这里面主要是提取这几个数据:每条消息的user、text、date,换句话说,如果我们按照这个格式写一个微信导出数据的消息提取就可以。
之后运行people_merger,进行实体检测。
之后运行argmentor,对原始数据的几类输入特征进行提取。
【模型代码】
作者使用pytorch构建的模型,encoder层有两部分,第一部分是对对话本身的:
feature_sets = sum(1 if feature_set else 0 for feature_set in [self.add_user_rep, self.add_liwc_counts, self.add_time_values, self.add_freq_values, self.add_tc_values, self.add_stop_values, self.add_lsm_values, self.add_surf_values, self.add_graph_values])self.fwdlstm = nn.LSTM(self.embed_size, hidden_size, bias=True, dropout=p, batch_first=True)self.bkwdlstm = nn.LSTM(self.embed_size, hidden_size, bias=True, dropout=p, batch_first=True)self.out_dropout = nn.Dropout(p=p)
第二部分是对9个输入特征的:
self.encode_user = nn.Linear(sum([len(tag_set[tag]) for tag in tag_set]), hidden_size)self.encode_liwc = nn.Linear(liwc_len, hidden_size)self.encode_time = nn.Linear(time_len, hidden_size)self.encode_freq = nn.Linear(freq_len, hidden_size)self.encode_tc = nn.Linear(tc_len, hidden_size)self.encode_stop = nn.Linear(stop_len, hidden_size)self.encode_lsm = nn.Linear(lsm_len, hidden_size)self.encode_surf = nn.Linear(surf_len, hidden_size)self.encode_graph = nn.Linear(graph_len, hidden_size)
第三部分是对输出特征的:
self.fam_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)self.npr_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)self.ra_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 3)self.scc_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)self.sg_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)self.sch_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)self.work_proj = nn.Linear((self.main_directions + feature_sets) * hidden_size, 2)
优化器使用Adam。loss函数使用的是交叉熵+L1正则,实际使用所有输出特征的loss之和作为总的loss值。
其它的就没什么了,代码很工整。模型并不复杂,主要是涉及的特征多种多样,很有大厂范,但是对于每一种特征的分析不够,这就意味着如果加入更多的特征也许能获得更好的结果,同时也意味着这个模型如果用在新环境下,不做足够的试验很可能是没有好结果的。
四、参考文献
[1] Welch, C., Pérez-Rosas, V., Kummerfeld, J. K., & Mihalcea, R. (2019). Look Who’s Talking: Inferring Speaker Attributes from Personal Longitudinal Dialog. ArXiv:1904.11610 [Cs]. https://github.com/cfwelch/longitudinal_dialog[2] rada mihalcea, http://web.eecs.umich.edu/~mihalcea/downloads.html[3] Schwartz, H. A., Eichstaedt, J. C., Kern, M. L., Dziurzynski, L., Ramones, S. M., Agrawal, M., Ungar, L. H. (2013). Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach. PLoS ONE, 8(9), e73791.[4] Rada Mihalcea, Carlo Strapparava, Stephen Pulman, Computational Models for Incongruity Detection in Humor, in Proceedings of the Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2010), Iasi, Romania, March 2010.[5] Rada Mihalcea and Stephen Pulman, Characterizing Humour: An Exploration of Features in Humorous Texts, in Proceedings of the Conference on Computational Linguistics and Intelligent Text Processing (CICLing), Springer, Mexico City, February 2007. 2nd best paper award.[6]Rada Mihalcea and Carlo Strapparava, Learning to Laugh (Automatically): Computational Models for Humor Recognition, in Journal of Computational Intelligence, 2006.[7] Rada Mihalcea and Carlo Strapparava, Making Computers Laugh: Investigations in Automatic Humor Recognition, in Proceedings of the Joint Conference on Human Language Technology / Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, October, 2005. [pdf] [ps][8] Rada Mihalcea and Carlo Strapparava, Computational Laughing: Automatic Recognition of Humorous One-liners, in Proceedings of the Cognitive Science Conference (CogSci), Stresa, Italy, July 2005.[9] Rada Mihalcea and Carlo Strapparava, Bootstrapping for Fun: Web-based Construction of Large Data Sets for Humor Recognition, in Proceedings of the Workshop on the Analysis of Informal and Formal Information Exchange during Negotiations FINEXIN 2005, Ottawa, Canada, May 2005.[10] Tausczik, Y.R., Pennebaker, J.W.: The psychological meaning of words: Liwc and computerized text analysis methods. Journal of language and social psychology 29(1), 24{54 (2010)[11] Gonzales, A.L., Hancock, J.T., Pennebaker, J.W.: Language style matching as a predictor of social dynamics in small groups. Communication Research (2009)
